
时间序列基本概念、任务、预测方法
本文开启时间序列系列的相关介绍,从零梳理时序概念、相关技术、和实战案例。
本篇介绍时间序列的定义、任务、构成以及预测方法,主要是基本概念的介绍和理解。
时间序列定义
时间序列,通俗的字面含义为一系列历史时间的序列集合。比如2013年到2022年我国全国总人口数依次记录下来,就构成了一个序列长度为10的时间序列。
专业领域里,时间序列定义为一个随机过程,是按时间顺序排列的一组随机变量的序列集,记为。并用 或者 表示该随机序列的N有序观测值。
这里有两个概念,随机变量和观测值。
随机变量:用大写字母表示,我们认为每个时间点的变量都符合一定的分布特性,变量值从分布中随机得到。
观测值:用小写字母表示,是随机变量的实现,也就是我们现实世界看到的数值。
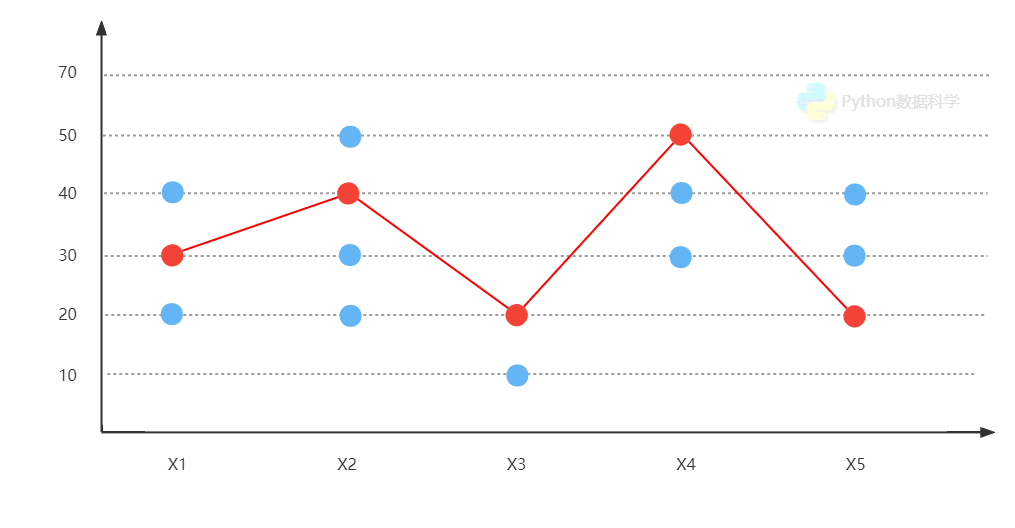
结合上图理解随机变量和观测值的关系。
我们认为每个时间点发生的数据都来自于一个分布的,即时序点是个随机的变量,如上图中所示,在未发生之前每个时序点有可能是红色,也有可能是蓝色。而一旦发生了就会成为一个事实,会变成历史,所以就只能存在一个唯一的数据。
这里的红色点就是观测点,是我们现实世界某个时刻我们肉眼看到的数据,而蓝色点则是随机变量里可能会出现的其他数据。蓝色和红色点一起组合了发生时刻的一个变量分布。拿股价举例,收盘之前的价格我们认为会在一个合理的分布区间之内浮动,但不到收盘结束谁都不知道具体是多少,可能是红色或者蓝色,一旦到了收盘就必然会有一个唯一的价格。
时间序列任务
学习时间序列都能做什么?为什么要做时序分析?
时间序列的常见作用可以分类以下几种,其中预测和异常检测是比较常用的应用场景。
预测:是最广泛的应用,基于历史时序数据预测未来时序数据,比如常见的股票价格、食品价格。
时序预测与回归预测类似,但又不同。相似的是都通过,不同的是回归预测是,用其他数据预测,而时序预测是,用预测。
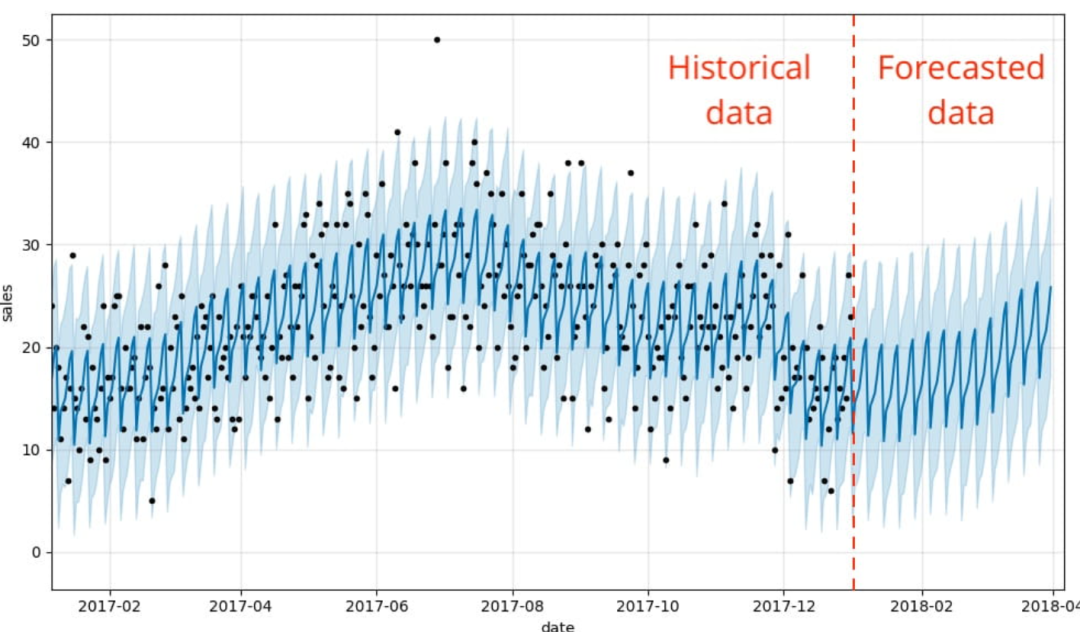
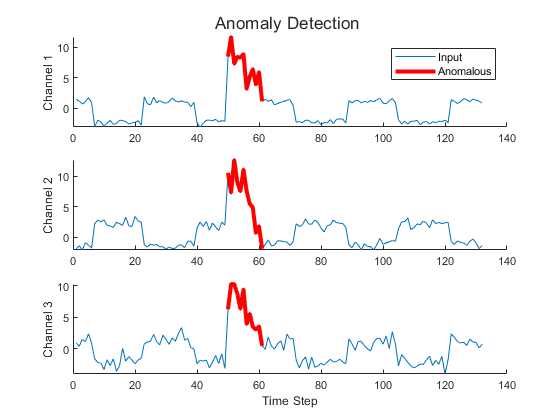
异常检测:用于查找时序数据中的异常数据点(称为异常值)或子序列的任务。
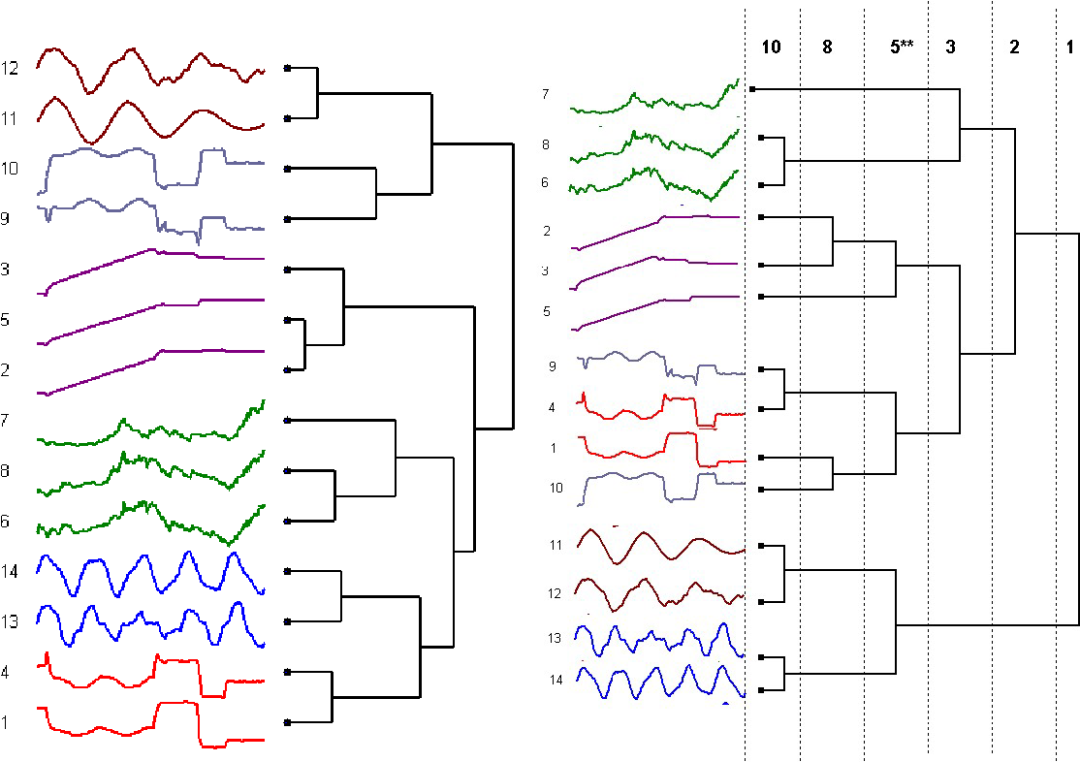
聚类:是将相似的时间序列聚合一起。
分类:将时间序列与预定义的类别对应。
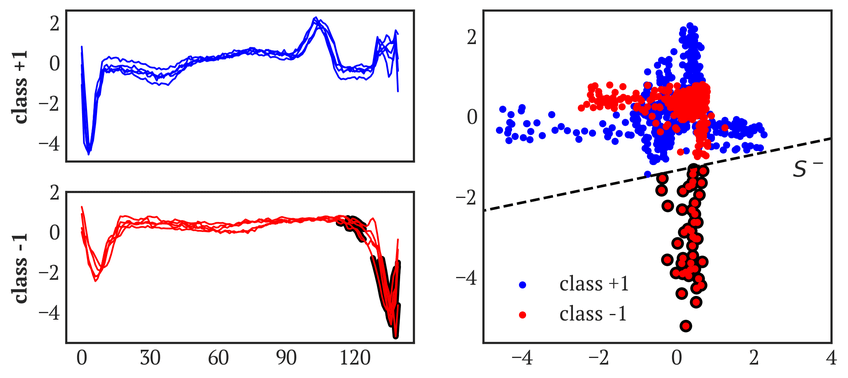
变点检测:需要寻找时间序列的统计属性(如均值、方差)突然变化的时间点。
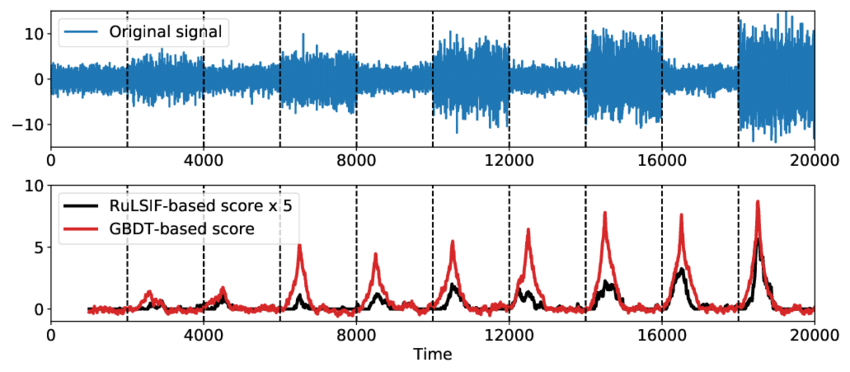
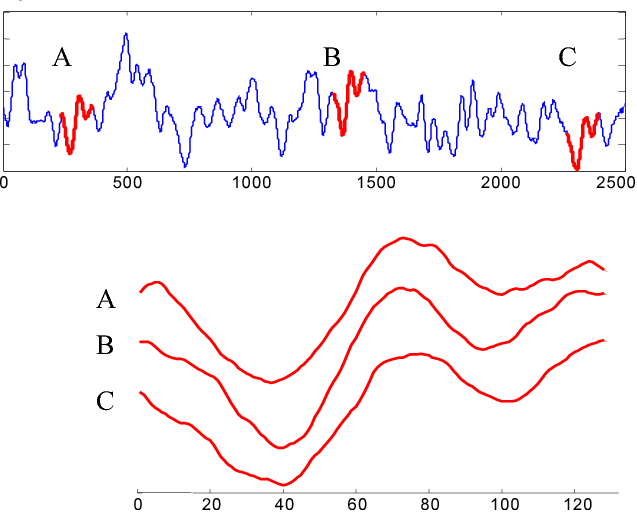
主题发现:寻找反复出现的时间序列子序列。
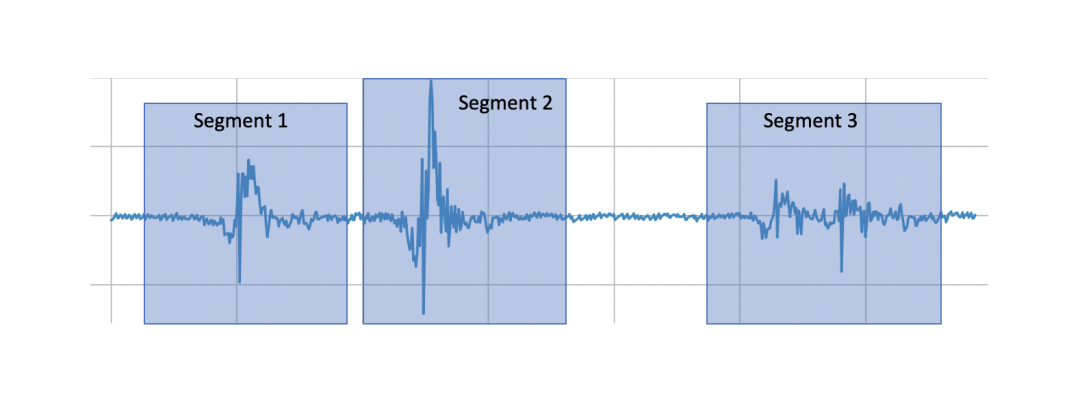
分割:通过减少时间序列的维度,同时保留其基本特征来创建时间序列的准确近似的任务
时间序列构成
时间序列通常由以下三个组成部分构成。
趋势:指时间序列在较长一段时间内呈现出来的持续向上或者持续向下的变动
季节性:指时间序列在一年内重复出现的周期性波动,如气候条件、生产条件、节假日等
残差:也称为不规则波动,指除去趋势、季节性、周期性外的随机波动。不规则波动通常总是夹杂在时间序列中,致使时间序列产生一种波浪形或震荡式的变动。只含有随机波动的序列也称为平稳序列
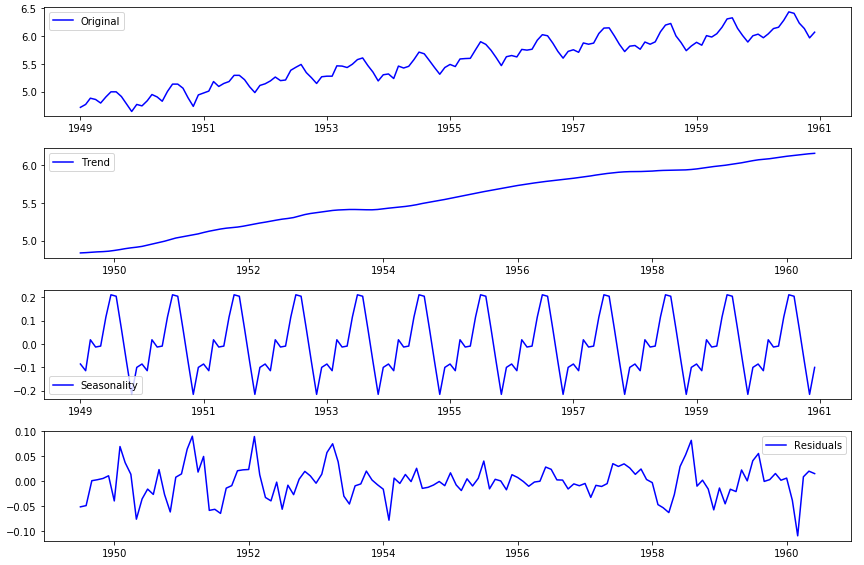
以上图二为趋势,图三为季节性,图四为残差。
既然时间序列可以拆解为这三部分,它们会不会组合起来使用呢?
是可以的,通常可以用两种简单模型来表示:
加法模型:
乘法模型:
代表趋势,表示季节,表示残差即无法解释的变化。
当趋势和季节性变化独立作用时,加法模型是合适的。
当季节性效应的大小取决于趋势的大小,乘法模型是合适的。
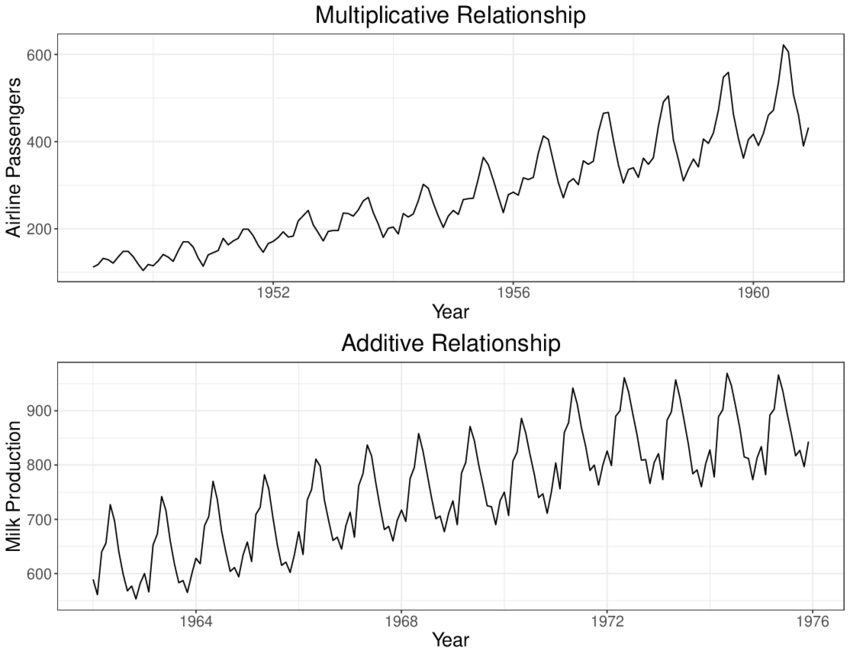
时间序列预测方法
1. 传统时序建模
比如典型的传统时序建模如ARMA、ARIMA模型。
ARIMA模型是ARMA模型的升级版。ARMA模型只能针对平稳数据进行建模,而ARIMA模型需要先对数据进行差分,差分平稳后在进行建模。这两个模型能处理的问题还是比较简单,究其原因主要是以下两点:
ARMA/ARIMA模型归根到底还是简单的线性模型,能表征的问题复杂程度有限ARMA全名是自回归滑动平均模型,它只能支持对单变量历史数据的回归,处理不了多变量的情况
2. 机器学习模型方法
这类方法把时序问题转换为监督学习,通过特征工程和机器学习方法去预测,支持复杂的数据建模,支持多变量协同回归,支持非线性问题,以lightgbm、xgboost为代表。
机器学习方法较为复杂的是特征工程部分,需要一定的专业知识或者丰富的想象力。特征工程能力的高低往往决定了机器学习的上限,而机器学习方法只是尽可能的逼近这个上限。特征建立好之后,就可以直接套用树模型算法lightgbm/xgboost。
机器学习方法主要有以下特点:
计算速度快,模型精度高; 缺失值不需要处理,比较方便; 支持category变量; 支持特征交叉
3. 深度学习模型方法
深度学习方法以LSTM/GRU、seq2seq、wavenet、1D-CNN、transformer为主。
其中,LSTM/GRU模型,是专门为解决时间序列问题而设计的。CNN模型是本来解决图像问题的,但是经过演变和发展,也可以用来解决时间序列问题
深度学习类模型主要有以下特点:
不能包括缺失值,必须要填充缺失值,否则会报错 支持特征交叉,如二阶交叉,高阶交叉等 需要embedding层处理category变量,可以直接学习到离散特征的语义变量,并表征其相对关系 Prophet数据量小的时候,模型效果不如树方法;但是数据量巨大的时候,神经网络会有更好的表现 神经网络模型支持在线训练
本篇是时序系列的开胃菜,后续会逐渐展开深入传统时序核心概念、应用案例,以及机器学习和深度学习方法、Python中使用时序的各种方法。
参考链接:
[1].https://mp.weixin.qq.com/s/sc9OJ-GVmtLB1CGL1Sr8VQ
[2].https://mp.weixin.qq.com/s/jqQMlJlt_OCvz0sJOVANUA
[3].https://mp.weixin.qq.com/s/-FhSxHWGH8WUwLE2YkWNEg>
[4].https://www.researchgate.net
[5].https://zhuanlan.zhihu.com/p/471014006
[6].https://medium.com/@nathanvenos/time-series-analysis-in-python-ab582dd803cd
[7].https://www.mathworks.com/help/deeplearning/ug/time-series-anomaly-detection-using-deep-learning.html
[8].https://vitalflux.com/different-types-of-time-series-forecasting-models/
往期精彩回顾
适合初学者入门人工智能的路线及资料下载 (图文+视频)机器学习入门系列下载 机器学习及深度学习笔记等资料打印 《统计学习方法》的代码复现专辑 机器学习交流qq群955171419,加入微信群请扫码