
一文解读时间序列基本概念
如果我可以根据仪表的过去表现,根据供求规律来预测它的未来价值,那会怎样呢?
准确预测什么时间采取相应策略来实现目标,这是一个不小的挑战,但对于这个挑战,其实是可以通过时间序列预测来解决。当你们在高峰期苦苦寻找停车位时,又被告知这将收取你比平时更多的费用,你们肯定难以接受。但街道通畅无阻的话,车主停车方便,也能给我带来不少的收入,真是一举两得!
接下来我们来探索一些时间序列算法。
一些定义
时间序列预测法
时间序列预测法是一种历史资料延伸预测,也称历史引伸预测法。是以数据数列所能反映的社会经济现象的发展过程和规律性,进行引伸外推,预测其发展趋势的方法。
需要明确一点的是,与回归分析预测模型不同,时间序列模型依赖于数值在时间上的先后顺序,同样大小的值改变顺序后输入模型产生的结果是不同的。
时间序列预测对商业有真正的价值,因为它直接应用于定价、库存和供应链问题。虽然深度学习技术已经开始用于获得更多的洞察力,以更好地预测未来,但时间序列预测仍然是一个主要由经典ML技术提供信息的领域。
当遇到时间序列这个词时,你需要了解它在不同语境中的用法。
时间序列
在数学中,时间序列是按时间顺序索引(或列出或图表)的一系列数据点。最常见的是,时间序列是在连续的等间隔时间点上获得的序列。
时间序列的一个例子是道琼斯工业平均指数[1]的日收盘价。在信号处理、天气预报、地震预报和其他可以绘制事件和数据点的领域中,经常会遇到时间序列图和统计建模的使用。
时间序列分析
时间序列分析,就是对上述时间序列数据的分析。时间序列数据可以采取不同的形式,包括中断时间序列,它检测时间序列在中断事件前后的演变模式。时间序列所需的分析类型取决于数据的性质。时间序列数据本身可以采用数字或字符序列的形式。
时间序列分析考虑了这样一个事实,即随着时间的推移获取的数据点可能具有应该考虑的内部结构(例如自相关、趋势或季节性变化)
要进行的分析使用多种方法,包括频域和时域、线性和非线性等等。可参见了解更多关于这类数据的时间序列分析的多种方法[2]。
时间序列分解
时间序列由四个部分组成:
:季节性成分 :趋势性成分 :周期性成分 :残差,或不规则组件。
时间序列分量分解之间的关系:
加法分解:
, 在哪里 是当时的数据 吨.乘法分解: 将乘法关系变成加法关系:
一个加模型是否季节性波动的幅度不随水平变化是适当的。如果季节性波动与序列的水平成正比,那么乘法模型是合适的。乘法分解在经济序列中更为普遍。
时间序列预测
时间序列预测是使用一个模型来预测未来的价值,该模型基于以前收集的数据在过去发生的模式。虽然可以使用回归模型来探索时间序列数据,将时间指数作为图表上的 变量,但最好使用特殊类型的模型来分析此类数据。
时间序列数据是一组有序的观测数据,不像可以通过线性回归分析的数据。最常见的是ARIMA,这是Autoregressive Integrated Moving Average(自回归综合移动平均线)的首字母缩写。
ARIMA 模型[3] 将一系列的现值与过去的值和过去的预测误差联系起来。它们最适合于分析时域数据,其中数据是随时间排序的。
后面推文将介绍使用单变量时间序列[4]构建一个ARIMA模型,该模型关注一个随时间改变其值的变量。这类数据的一个例子是这个数据集[5],它记录了莫纳罗亚天文台每月的二氧化碳浓度:
| CO2 | YearMonth | Year | Month |
|---|---|---|---|
| 330.62 | 1975.04 | 1975 | 1 |
| 331.40 | 1975.13 | 1975 | 2 |
| 331.87 | 1975.21 | 1975 | 3 |
| 333.18 | 1975.29 | 1975 | 4 |
| 333.92 | 1975.38 | 1975 | 5 |
| 333.43 | 1975.46 | 1975 | 6 |
| 331.85 | 1975.54 | 1975 | 7 |
| 330.01 | 1975.63 | 1975 | 8 |
| 328.51 | 1975.71 | 1975 | 9 |
| 328.41 | 1975.79 | 1975 | 10 |
| 329.25 | 1975.88 | 1975 | 11 |
| 330.97 | 1975.96 | 1975 | 12 |
时间序列数据特征
在查看时间序列数据时,为了更好地理解其模式,需要拆解某些特征。如果你想要分析"信号"包含在时间序列数据中,那么就认为这些特征是相对于"信号"的"噪声"。此时需要通过使用一些统计技术来抵消这些特征以减少"噪音"。
时间序列数据变动存在规律性与不规律性
时间序列中的每个观察值大小,是影响变化的各种不同因素在同一时刻发生作用的综合结果。从这些影响因素发生作用的大小和方向变化的时间特性来看,这些因素造成的时间序列数据的变动分为四种类型。
趋势性
某个变量随着时间进展或自变量变化,呈现一种比较缓慢而长期的持续上升、下降、停留的同性质变动趋向,但变动幅度可能不相等。季节性
某因素由于外部影响随着自然季节的交替出现高峰与低谷的规律。随机性
个别为随机变动,整体呈统计规律。综合性
实际变化情况是几种变动的叠加或组合。预测时设法过滤除去不规则变动,突出反映趋势性和周期性变动。
查看时间序列时首先要考虑的重要特征
是否存在趋势,意味着平均而言,测量值会随着时间的推移而增加(或减少)? 是否存在季节性,这意味着与日历时间(例如季节、季度、月份、星期几等)相关的高点和低点有规律地重复模式? 有异常值吗?在回归中,离群值离你的线很远。对于时间序列数据,您的异常值与其他数据相距甚远。 是否存在与季节性因素无关的长期周期或时期? 随着时间的推移是否存在恒定的方差,或者方差是非常量的? 序列水平或方差是否有任何突然变化?
趋势性
通常,时间序列中不具有周期性的系统变化称为趋势。趋势是序列随时间的持续增加或减少。从时间序列数据集中识别、建模甚至删除趋势信息可能会带来好处。
趋势类型
有各种各样的趋势,通常分为:
确定性趋势:这些是持续增加或减少的趋势。 随机性趋势:这些趋势会不一致地增加和减少。
一般来说,确定性趋势更容易识别和删除。
根据观察范围来分类趋势:
全局趋势:这些趋势适用于整个时间序列。 本地趋势:这些趋势适用于时间序列的部分或子序列。
一般来说,全局趋势更容易识别和应对。
识别趋势
可以绘制时间序列数据以查看趋势是否明显。
而在实践中,识别时间序列中的趋势可能是一个主观过程。因此从时间序列中提取或删除它可能同样具有主观性。创建数据的线图并检查图中的明显趋势。 在图中添加线性和非线性趋势线,看看趋势是否明显。
删除趋势
具有趋势的时间序列称为非平稳的。可以对识别的趋势进行建模。建模后,可以将其从时间序列数据集中删除。这称为去趋势时间序列。
如果数据集没有趋势或我们成功地移除了趋势,则称该数据集是趋势平稳的。
在机器学习中使用时间序列趋势
从机器学习的角度来看,数据的趋势代表着两个机会:
删除信息:删除扭曲输入和输出变量之间关系的系统信息。 添加信息:添加系统信息以改善输入和输出变量之间的关系。
具体来说,作为数据准备和清洗练习,可以从时间序列数据(以及未来的数据)中删除趋势。这在使用统计方法进行时间序列预测时很常见,但在使用机器学习模型时并不总是能改善结果。
季节性
季节性被定义为周期性的波动,季节性变化或季节性是随着时间有规律地重复的循环。
许多时间序列显示季节性。例如,零售额往往在春季期间达到顶峰,然后在假期过后下降。因此,零售销售的时间序列通常会显示 1月至 3月的销售额增加,而 4 月和 5 月的销售额下降。季节性在经济时间序列中很常见,它在工程和科学数据中不太常见。
时间序列中的周期结构可能是季节性的,也可能不是。如果它始终以相同的频率重复,则是季节性的,否则就不是季节性的,称为循环。
季节性类型
季节性有很多种。例如:时间、日、每周、每月、每年。因此,确定时间序列问题中是否存在季节性成分是主观的。
确定是否存在季节性因素的最简单方法是绘制和查看数据,可能以不同的比例并添加趋势线。
去除季节性
一旦确定了季节性,就可以对其进行建模。季节性模型可以从时间序列中删除。此过程称为季节性调整[8]或去季节性[9]化。
去除了季节性成分的时间序列称为季节性平稳。具有明显季节性成分的时间序列被称为非平稳的。
在时间序列分析领域,有一些复杂的方法可以从时间序列中研究和提取季节性。
机器学习中作用
了解时间序列中的季节性成分可以提高机器学习建模的性能。
这可以通过两种主要方式发生:
更清晰的信号:从时间序列中识别和去除季节性成分可以使输入和输出变量之间的关系更清晰。 更多信息:关于时间序列季节性分量的附加信息可以提供新信息以提高模型性能。
这两种方法都可能对项目有用。并在数据清洗和准备期间就需要建模季节性并将其从时间序列中删除。
在特征提取和特征工程期间,可能会提取季节性信息并将其作为输入特征。
其他
离群值:离群值离标准数据方差很远。
长期循环:独立于季节性因素,数据可能显示一个长期周期,比如持续超过一年的经济衰退。
恒定方差:随着时间的推移,一些数据显示出不断的波动,比如每天和晚上的能源使用量。
突变:数据可能显示出突变,可能需要进一步分析。例如,由于COVID而突然关闭的企业导致了数据的变化。
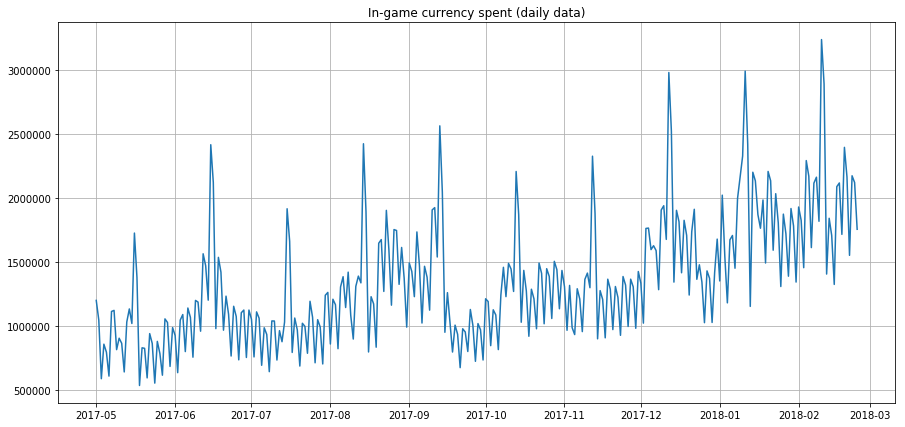
以下是时间序列样本图[11],显示了玩家在过去几年里每天花费在游戏中的货币。你能在这个数据中识别出上面列出的任何特征吗?
时间序列预测方法
基本规则
通过人工经验,挖掘时序数据的演化特征,找到时序变化的周期,从而预估时间序列的未来走势。具体的观察一个时间序列,当序列存在周期性时,提取时间序列的周期性特征进行预测。
传统参数法
传统的参数预测方法可以分为两种,
一种拟合标准时间序列的餐顺方法,包括移动平均,指数平均等;
另一种是考虑多因素组合的参数方法,即 AR, MA, ARMA, ARIMA等模型。这类方法比较适用于小规模,单变量的预测。
时间序列分解
一个时间序列往往是一下几类变化形式的叠加或耦合
长期趋势 (Secular trend, T)
长期趋势指现象在较长时期内持续发展变化的一种趋向或状态。季节变动 (Seasonal Variation, S)
季节波动是由于季节的变化引起的现象发展水平的规则变动循环波动 (Cyclical Variation, C)
循环波动指以若干年为期限,不具严格规则的周期性连续变动不规则波动 (Irregular Variation, I)
不规则波动指由于众多偶然因素对时间序列造成的影响
机器学习
主要是构建样本数据集,采用“时间特征”到“样本值”的方式,通过有监督学习,学习特征与标签之前的关联关系,从而实现时间序列预测。
单步预测
在时间序列预测中使用滞后的观测值 ,作为输入变量来预测当前的时间的观测值
多步预测
使用过去的观测序列 来预测未来的观测序列
多变量预测
每个时间有多个观测值:
通过不同的测量手段得到了多种观测值,并且希望预测其中的一个或几个值。
深度学习
对于时间序列的分析,有许多方法可以进行处理,包括:循环神经网络-LSTM模型 / 卷积神经网络 / 基于注意力机制的模型(seq2seq)/...
循环神经网络
循环神经网络(RNN)框架及其变种(LSTM/GRU/...)是为处理序列型而生的模型,天生的循环自回归的结构是对时间序列的很好的表示
时间卷积网络
时间卷积网络(TCN)是一种特殊的卷积神经网络,针对一维空间做卷积,迭代多层捕捉长期关系。具体的,对于上一层t时刻的值,只依赖于下一层t时刻及其之前的值。
一个时间序列数据--电力使用数据
开始创建一个时间序列模型,根据过去的使用情况来预测未来的电力使用量。
本例中的数据来自GEFCom2014预测竞赛。由2012 - 2014年3年的小时电负荷和温度值组成。
import os
import matplotlib.pyplot as plt
import pandas as pd
%matplotlib inline
data_dir = './data'
energy = pd.read_csv('./energy.csv')
energy.head()
可以看到有两列表示date和load
| load | |
|---|---|
| 2012-01-01 00:00:00 | 2698.0 |
| 2012-01-01 01:00:00 | 2558.0 |
| 2012-01-01 02:00:00 | 2444.0 |
| 2012-01-01 03:00:00 | 2402.0 |
| 2012-01-01 04:00:00 | 2403.0 |
可视化
energy.plot(y='load', subplots=True, figsize=(15, 8), fontsize=12)
plt.xlabel('timestamp', fontsize=12)
plt.ylabel('load', fontsize=12)
plt.show()

现在,绘制2014年7月的第一周,将其作为energy的输入,在[from date]: [to date] 模式中:
energy['2014-07-01':'2014-07-07'].plot(y='load', subplots=True, figsize=(15, 8), fontsize=12)
plt.xlabel('timestamp', fontsize=12)
plt.ylabel('load', fontsize=12)
plt.show()
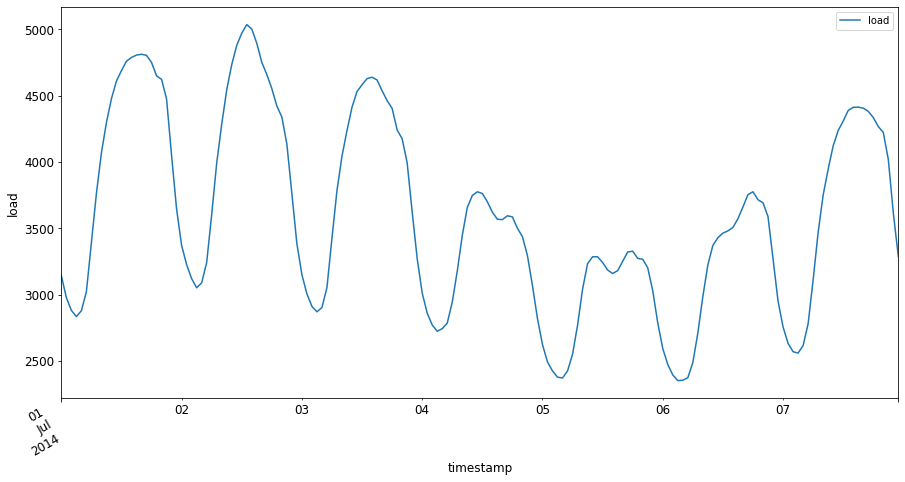
看看这些图,看看你是否能确定上面列出的任何特征。通过可视化数据我们可以推测出什么?后面将介绍创建一个ARIMA模型来创建一些预测。




