
机器学习第20篇 - 基于Boruta选择的特征变量构建随机森林
前面机器学习第18篇 - Boruta特征变量筛选(2)已经完成了特征变量筛选,下面看下基于筛选的特征变量构建的模型准确性怎样?
定义一个函数生成一些列用来测试的mtry (一系列不大于总变量数的数值)。
generateTestVariableSet <- function(num_toal_variable){
max_power <- ceiling(log10(num_toal_variable))
tmp_subset <- unique(unlist(sapply(1:max_power, function(x) (1:10)^x, simplify = F)))
sort(tmp_subset[tmp_subset} 选择关键特征变量相关的数据
# withTentative=F: 不包含tentative变量
boruta.confirmed <- getSelectedAttributes(boruta, withTentative = F)
# 提取训练集的特征变量子集
boruta_train_data <- train_data[, boruta.confirmed]
boruta_mtry <- generateTestVariableSet(length(boruta.confirmed))使用 Caret 进行调参和建模
library(caret)
# Create model with default parameters
trControl <- trainControl(method="repeatedcv", number=10, repeats=5)
# train model
if(file.exists('rda/borutaConfirmed_rf_default.rda')){
borutaConfirmed_rf_default <- readRDS("rda/borutaConfirmed_rf_default.rda")
} else {
# 设置随机数种子,使得结果可重复
seed <- 1
set.seed(seed)
# 根据经验或感觉设置一些待查询的参数和参数值
tuneGrid <- expand.grid(mtry=boruta_mtry)
borutaConfirmed_rf_default <- train(x=boruta_train_data, y=train_data_group, method="rf",
tuneGrid = tuneGrid, #
metric="Accuracy", #metric='Kappa'
trControl=trControl)
saveRDS(borutaConfirmed_rf_default, "rda/borutaConfirmed_rf_default.rda")
}
print(borutaConfirmed_rf_default)在使用Boruta选择的特征变量后,模型的准确性和Kappa值都提升了很多。
## Random Forest
##
## 59 samples
## 56 predictors
## 2 classes: 'DLBCL', 'FL'
##
## No pre-processing
## Resampling: Cross-Validated (10 fold, repeated 5 times)
## Summary of sample sizes: 53, 54, 53, 54, 53, 52, ...
## Resampling results across tuning parameters:
##
## mtry Accuracy Kappa
## 1 0.9862857 0.9565868
## 2 0.9632381 0.8898836
## 3 0.9519048 0.8413122
## 4 0.9519048 0.8413122
## 5 0.9519048 0.8413122
## 6 0.9519048 0.8413122
## 7 0.9552381 0.8498836
## 8 0.9519048 0.8413122
## 9 0.9547619 0.8473992
## 10 0.9519048 0.8413122
## 16 0.9479048 0.8361174
## 25 0.9519048 0.8413122
## 36 0.9450476 0.8282044
## 49 0.9421905 0.8199691
##
## Accuracy was used to select the optimal model using the largest value.
## The final value used for the model was mtry = 1.提取最终选择的模型,并绘制 ROC 曲线。
borutaConfirmed_rf_default_finalmodel <- borutaConfirmed_rf_default$finalModel采用训练数据集评估构建的模型,Accuracy=1; Kappa=1,训练的非常完美。
模型的预测显著性P-Value [Acc > NIR] : 3.044e-08。其中NIR是No Information Rate,其计算方式为数据集中最大的类包含的数据占总数据集的比例。如某套数据中,分组A有80个样品,分组B有20个样品,我们只要猜A,正确率就会有80%,这就是NIR。如果基于这套数据构建的模型准确率也是80%,那么这个看上去准确率较高的模型也没有意义。
confusionMatrix使用binom.test函数检验模型的准确性Accuracy是否显著优于NIR,若P-value<0.05,则表示模型预测准确率显著高于随便猜测。
# 获得模型结果评估矩阵(`confusion matrix`)
predictions_train <- predict(borutaConfirmed_rf_default_finalmodel, newdata=train_data)
confusionMatrix(predictions_train, train_data_group)## Confusion Matrix and Statistics
##
## Reference
## Prediction DLBCL FL
## DLBCL 44 0
## FL 0 15
##
## Accuracy : 1
## 95% CI : (0.9394, 1)
## No Information Rate : 0.7458
## P-Value [Acc > NIR] : 3.044e-08
##
## Kappa : 1
##
## Mcnemar's Test P-Value : NA
##
## Sensitivity : 1.0000
## Specificity : 1.0000
## Pos Pred Value : 1.0000
## Neg Pred Value : 1.0000
## Prevalence : 0.7458
## Detection Rate : 0.7458
## Detection Prevalence : 0.7458
## Balanced Accuracy : 1.0000
##
## 'Positive' Class : DLBCL
##绘制ROC曲线,计算模型整体的AUC值,并选择最佳阈值。
# 绘制ROC曲线
prediction_prob <- predict(borutaConfirmed_rf_default_finalmodel, newdata=test_data, type="prob")
library(pROC)
roc_curve <- roc(test_data_group, prediction_prob[,1])
#roc <- roc(test_data_group, factor(predictions, ordered=T))
roc_curve##
## Call:
## roc.default(response = test_data_group, predictor = prediction_prob[, 1])
##
## Data: prediction_prob[, 1] in 14 controls (test_data_group DLBCL) > 4 cases (test_data_group FL).
## Area under the curve: 0.9821选择最佳阈值,在控制假阳性率的基础上获得高的敏感性
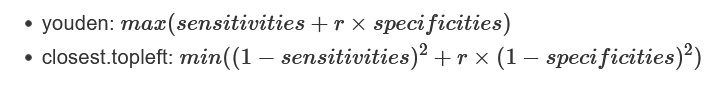
r是加权系数,默认是1,其计算方式为
best.weights控制加权方式:(cost, prevalence)默认是(1, 0.5),据此算出的r为1。
cost: 假阴性率占假阳性率的比例,容忍更高的假阳性率还是假阴性率
prevalence: 关注的类中的个体所占的比例 (
n.cases/(n.controls+n.cases)).
best_thresh <- data.frame(coords(roc=roc_curve, x = "best", input="threshold",
transpose = F, best.method = "youden"))
best_thresh## threshold specificity sensitivity
## 1 0.736 0.9285714 1准备数据绘制ROC曲线
library(ggrepel)
ROC_data <- data.frame(FPR = 1- roc_curve$specificities, TPR=roc_curve$sensitivities)
ROC_data <- ROC_data[with(ROC_data, order(FPR,TPR)),]
best_thresh$best <- apply(best_thresh, 1, function (x)
paste0('threshold: ', x[1], ' (', round(1-x[2],3), ", ", round(x[3],3), ")"))
p <- ggplot(data=ROC_data, mapping=aes(x=FPR, y=TPR)) +
geom_step(color="red", size=1, direction = "vh") +
geom_segment(aes(x=0, xend=1, y=0, yend=1)) + theme_classic() +
xlab("False positive rate") +
ylab("True positive rate") + coord_fixed(1) + xlim(0,1) + ylim(0,1) +
annotate('text', x=0.5, y=0.25, label=paste('AUC=', round(roc$auc,2))) +
geom_point(data=best_thresh, mapping=aes(x=1-specificity, y=sensitivity), color='blue', size=2) +
geom_text_repel(data=best_thresh, mapping=aes(x=1.05-specificity, y=sensitivity ,label=best))
p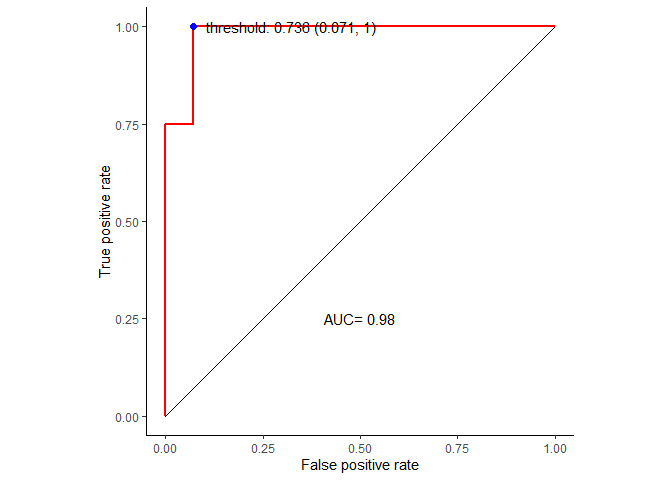
基于默认阈值绘制混淆矩阵并评估模型预测准确度显著性,结果不显著P-Value [Acc > NIR]>0.05。
# 获得模型结果评估矩阵(`confusion matrix`)
predictions <- predict(borutaConfirmed_rf_default_finalmodel, newdata=test_data)
confusionMatrix(predictions, test_data_group)## Confusion Matrix and Statistics
##
## Reference
## Prediction DLBCL FL
## DLBCL 14 1
## FL 0 3
##
## Accuracy : 0.9444
## 95% CI : (0.7271, 0.9986)
## No Information Rate : 0.7778
## P-Value [Acc > NIR] : 0.06665
##
## Kappa : 0.8235
##
## Mcnemar's Test P-Value : 1.00000
##
## Sensitivity : 1.0000
## Specificity : 0.7500
## Pos Pred Value : 0.9333
## Neg Pred Value : 1.0000
## Prevalence : 0.7778
## Detection Rate : 0.7778
## Detection Prevalence : 0.8333
## Balanced Accuracy : 0.8750
##
## 'Positive' Class : DLBCL
##基于选定的最优阈值制作混淆矩阵并评估模型预测准确度显著性,结果还是不显著 P-Value [Acc > NIR]>0.05。
predict_result <- data.frame(Predict_status=c(T,F), Predict_class=colnames(prediction_prob))
head(predict_result)## Predict_status Predict_class
## 1 TRUE DLBCL
## 2 FALSE FLpredictions2 <- plyr::join(data.frame(Predict_status=prediction_prob[,1] > best_thresh[1,1]), predict_result)
predictions2 <- as.factor(predictions2$Predict_class)
confusionMatrix(predictions2, test_data_group)## Confusion Matrix and Statistics
##
## Reference
## Prediction DLBCL FL
## DLBCL 13 0
## FL 1 4
##
## Accuracy : 0.9444
## 95% CI : (0.7271, 0.9986)
## No Information Rate : 0.7778
## P-Value [Acc > NIR] : 0.06665
##
## Kappa : 0.8525
##
## Mcnemar's Test P-Value : 1.00000
##
## Sensitivity : 0.9286
## Specificity : 1.0000
## Pos Pred Value : 1.0000
## Neg Pred Value : 0.8000
## Prevalence : 0.7778
## Detection Rate : 0.7222
## Detection Prevalence : 0.7222
## Balanced Accuracy : 0.9643
##
## 'Positive' Class : DLBCL
##筛选完特征变量后,模型的准确性和Kappa值都提高了很多。但统计检验却还是提示不显著,这可能是数据不平衡的问题,我们后续继续优化。
机器学习系列教程
从随机森林开始,一步步理解决策树、随机森林、ROC/AUC、数据集、交叉验证的概念和实践。
文字能说清的用文字、图片能展示的用、描述不清的用公式、公式还不清楚的写个简单代码,一步步理清各个环节和概念。
再到成熟代码应用、模型调参、模型比较、模型评估,学习整个机器学习需要用到的知识和技能。