
生成对抗网络中的数据增广:一种可微分的数据增广方法
NIPS2020 - Differentiable Augmentation For Data-Efficient GAN Training
1. 摘要
本文聚焦于探究在受限数据量情况下,生成对抗网络的性能退化问题。在本文的假设中,在数据量不足的情况下,生成对抗网络GAN的性能下降的原因:判别器过拟合了,记忆了整个数据集。在本文中,提出了一个DIfferentiable Augmentation(DiffAugment)方法,该种方法通过在生成样本Fake Samples与真实样本Real Samples引入可微分的数据增广操作来扩充数据,实现生成对抗网络在小样本量下也能达到较优的性能。本文提出增广方法与过去的直接在真实样本Real images上进行数据增广的操作不同,DiffAugment也在生成样本上进行了数据增广,因此在训练过程中也大幅度提升了系统训练的稳定性,同时也促进了网络的收敛。
2. Introduction
虽然现在生成对抗网络已经在很多领域广泛应用,但是仍然存在两大问题:Computation Efficiency(需要大量计算资源) 和Data Efficiency(需要大量训练数据)的问题。近年来,[1], [2]论文尝试降低了模型推理时对计算资源的要求,但是对大量数据的需求仍然是一个很严峻的问题。
生成对抗网络很依赖与训练样本的多样性和广泛性。比如在FFHQ数据集中,一共有接近70000张预先选择+预处理过的高清晰度人脸图像。收集高质量的大规模数据集需要大量的人力物力。除此以外,在很多罕见的种类的图片本身就很获取,因此如果GAN能够在较少样本的情况下生成更多符合实际的图片,具有很强的现实意义。
但是,我们发现降低训练数据集的图片数量会带来明显的网络性能下降。
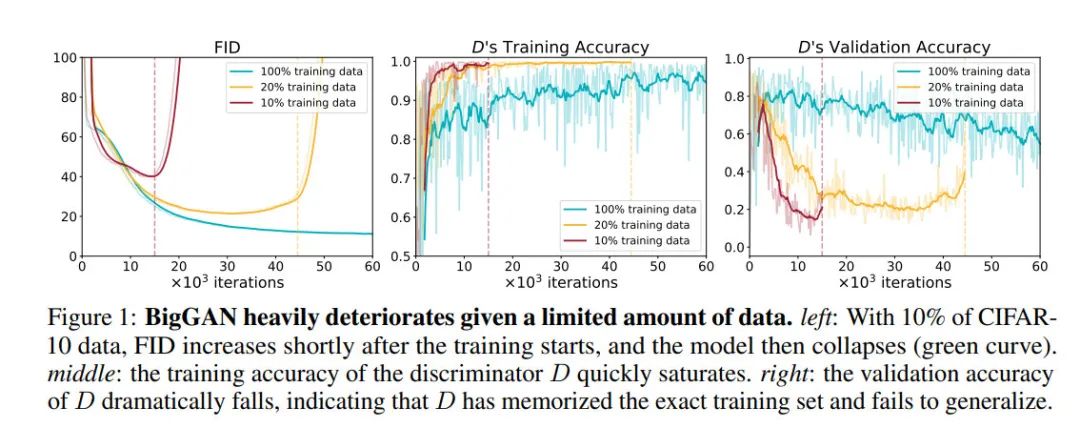
从Figure1可以看出,我们只采用10%或者20%的CIFAR-10数据集作为训练集时,判别器的训练准确性迅速收敛,并且很快就能达到接近100%;但是判别器的训练准确性曲线却持续下降,最低的时候,判别器在验证集上的准确率会降至30%。这代表着我们的判别器出现了明显的过拟合现象。这种判别器的过拟合问题打破了生成对抗网络的训练的动态平衡,并且进一步导致了生成图像的质量下降。

在图像分类任务中,已经有很多成熟的数据增广方法。但是,这些方法在生成对抗网络中并不好用。如果我们仅仅对真实样本Real Samples应用数据增广方法,生成器更倾向于去匹配增广后的图片的分布情况。这样的后果是:生成对抗网络生成图像存在较为明显的分布漂移、引入了外部的artifacts(比如masked区域,不自然的颜色)等情况(如图5a所示)。
当然,我们也可以尝试去对Real Samples以及Fake Samples都进行数据增广操作。但是这种增广操作将会打破生成器与判别器之间的微妙的平衡,进而导致生成器与判别器的收敛方向完全不同(因为他们优化了完全不同的目标)。
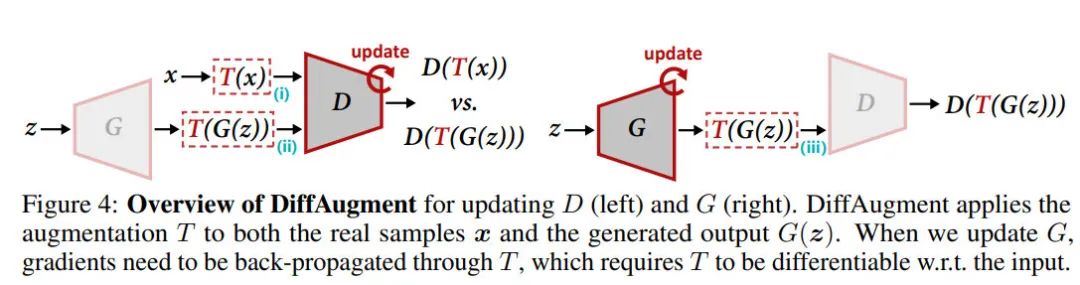
为了对抗这种现象,本文提出了DiffAug的想法,通过在生成器与判别器训练时施加相同的可微分的数据增广方法,是的梯度能够从图像增广部分回传给生成器,并且在不操作目标分布的情况下,达到对判别器施加正则化项的目的,保持训练过程的稳定性。
3. 本文方法
3.1 重思考数据增广
数据增广方法与正则化手段都是常见图像任务中解决网络过拟合的方法,两者重要性不相伯仲。但是在生成对抗网络领域的研究中,与大家常见的对于判别器施加正则化约束的方法相比,几乎没有人使用数据增广方法来避免判别器的过拟合现象。本文探究:为什么我们不能将数据增广方法施加到生成对抗网络中,为什么在生成对抗网络中使用数据增广方法不像在分类器中使用数据增广方法那么有效。
本文通过不同的数据增广方式入手,研究数据增广在生成对抗网络中的正确打开方式。
3.1.1 只增广真实图片Aug Real Samples Only
该方法最直接,对于生成对抗网络,我们只在真实的观测值(Training Samples, a.k.a. Real Samples)上施加数据增广操作。该方法的数学公式如下:
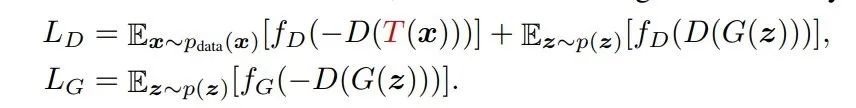
但是这种方法具有局限性。生成对抗网络的本质上是学习数据的分布,因此我们采用的数据增广方法不能够大幅度改变数据的原始分布x,否则生成对抗网络会去学习一个完全不一样的数据分布T(x)。该前提阻止我们应用那些会严重改变真实图像分布的图像增广方法。这导致在大多数情况下,我们只能对图片施加水平翻转。本文实验发现:加入水平翻转能够显著提升网络的重建性能。因此本文中的Baseline就直接使用水平翻转作为默认的数据增广方法。
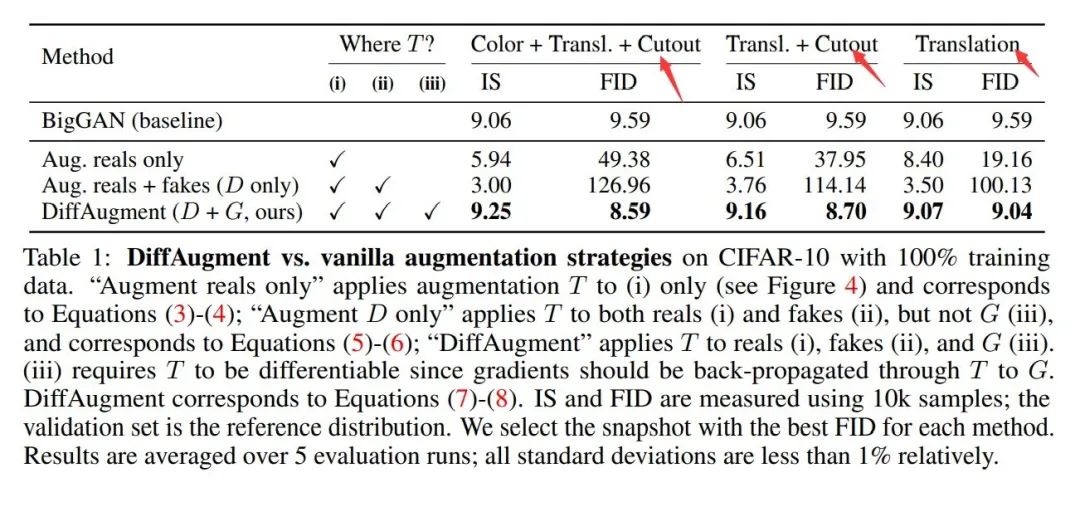
 我们在表一中展示了对图片施加强增广策略后,对GAN网络带来的负面影响。同时在Fig5(a)中我们可以看出:网络会学习到数据增广后图片的不需要的图片扭曲以及几何扭曲。这导致网络生成的图像质量不佳。
我们在表一中展示了对图片施加强增广策略后,对GAN网络带来的负面影响。同时在Fig5(a)中我们可以看出:网络会学习到数据增广后图片的不需要的图片扭曲以及几何扭曲。这导致网络生成的图像质量不佳。
3.1.2 只增广生成图片Aug D Only
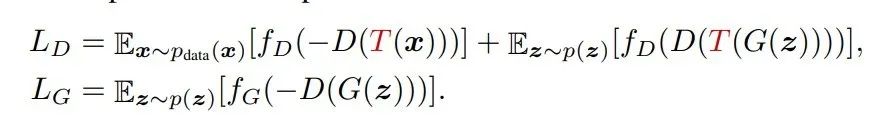
这里我们对生成图像以及真实图像同时进行数据增广操作。
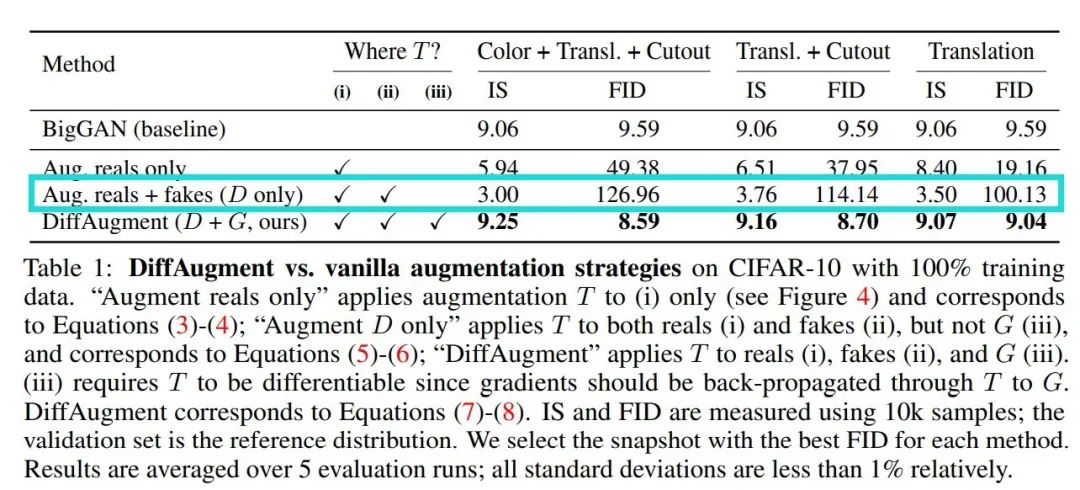
理想情况下,如果生成模型成功建模了原始分布x,那么T(G(Z))以及T(X)对于判别器来说应该是不可分的。但是,实验证明这种策略导致了更差的结果。如表1中蓝色框所示。
尽管判别器成功对于增广后的图片进行了分类,但是我们发现网络无法识别出生成图片G(z)(未进行图像增广的生成图片)。从这里可以看出:生成器完全迷惑了判别器,因此生成器也没有办法从判别器中获取有用的信息。这从侧面证明了:任何打破生成器与判别器之间微妙平衡的尝试都会导致生成对抗网络的性能猛烈衰减。
3.2 适用于GAN的可微数据增广
从3.1.1节和3.1.2节可知:我们不仅仅需要同时对生成样本与真实样本进行数据增广,而且生成器不能够忽略增广的样本。为了达到这种目的,我们需要让图像的增广策略伴随着生成器动态变化,这种策略也被称为:Differentiable Augmentations (DiffAugment):
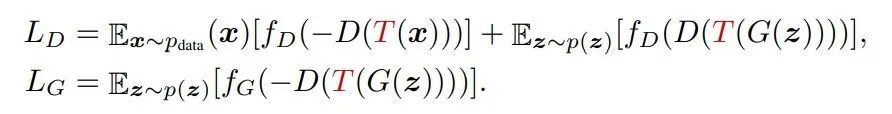
这里的图像的增广策略T需要是相同的functions(但是增广function中参数的随机数种子可以不一致)。本文作为验证,采用3种带来较大图像变化的数据增广方法(Translation、Cutout、Color)。具体三种方法的参数详见官方代码及论文细节。

定量实验如上表所示:BigGAN能够通过简单的图片Translation策略得到性能提升,并且进一步通过CutOut+Translation策略能够有显著的性能提升,进一步的加入Color策略后,生成的图像质量最佳。
4. 实验
本文进一步在StyleGAN2网络的基础上,验证了FFHQ、LSUN-Cat数据集在256*256分辨率情况下的实验结果。为了进一步验证本文的数据增广方法的效果,本文还进行了不同张数的训练图片情况下的不同实验的比较。
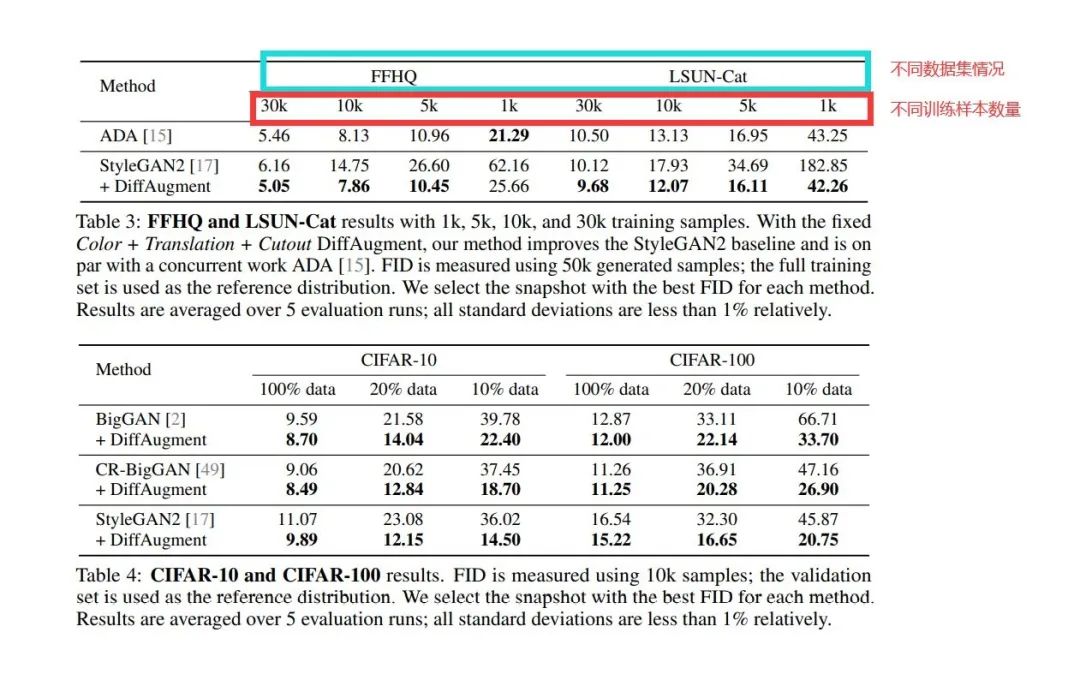
实验结果证明了,本文提出的增广方法是有效的。同时这里有一点需要注意:本文采用的BigGAN、CR-BigGAN以及StyleGAN2的模型都已经加入了先进的正则化手段:Spectral Normalization [27], Consistency Regularization [49], and R1 regularization [26]; 本文提出的方法在特别小训练数据的情况下,生成图像的质量明显更优。
同时,本文还和一些low-shot生成图像的方法进行了比较。
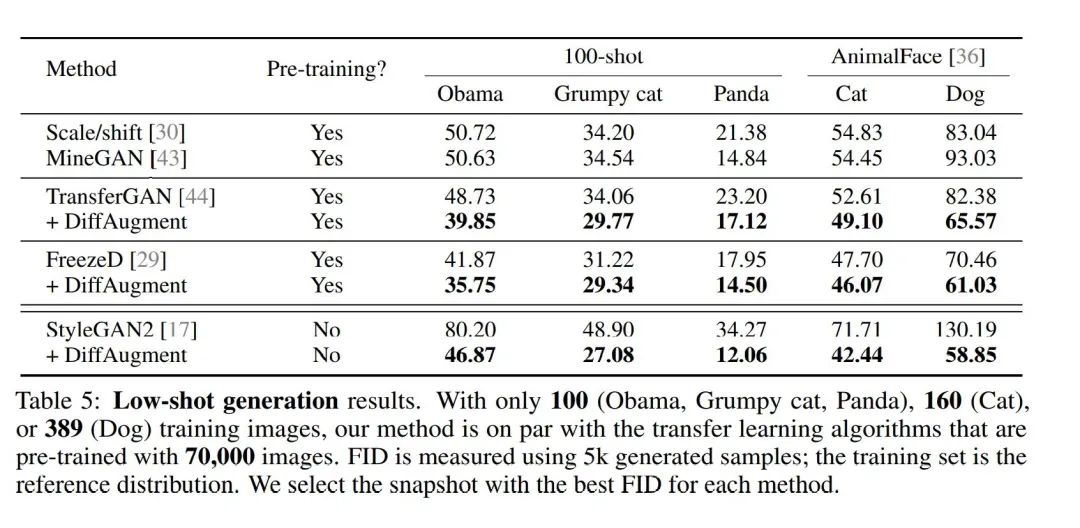
可以看到,本文的方法无论是在需要pretrained model的基于迁移学习的GAN方法还是在不需要迁移学习的方法上均有效,生成图像质量都有着明显提升。

同时从图7也可以看出,我们生成图像的多样性仍然较强,该方法的确缓和了生成对抗网络的过拟合问题。
4.5 额外分析
本文同时还分析了为什么采用较小模型或者施加了强正则化的GAN网络能够降低过拟合风险,并且本文提出的DIffAug方法是否仍然有效。并且在最后,本文还探究了DIffAug方法是否有更多的图像增广方法的潜在选择选项。
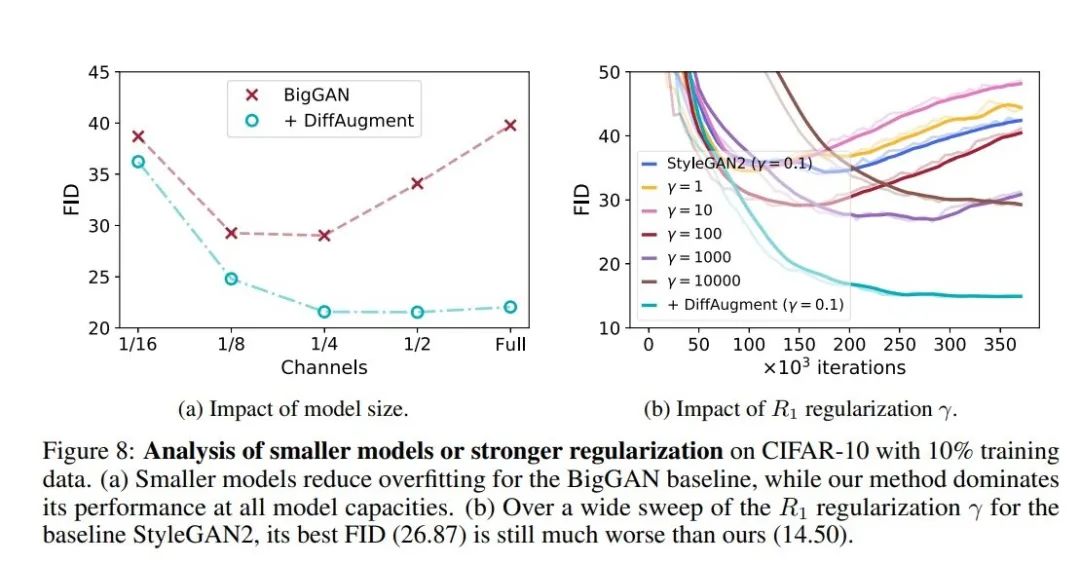
从图8(a)看出:我们通过对BigGAN网络进行剪支后,性能在一定程度上有提高。但是剪支过多时,性能又出现下降。同时从图8(b)中可以看出,我们加入了正则化项后,我们的方法比常规的正则化方法更有效。

同时,从图9可以看出,我们采用Color+Translation+Cutout策略效果更佳。
5. 参考文献
[1] Muyang Li, Ji Lin, Yaoyao Ding, Zhijian Liu, Jun-Yan Zhu, and Song Han. GAN Compression: Efficient Architectures for Interactive Conditional GANs. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020.
[2] Han Shu, Yunhe Wang, Xu Jia, Kai Han, Hanting Chen, Chunjing Xu, Qi Tian, and Chang Xu. CoEvolutionary Compression for Unpaired Image Translation. In IEEE International Conference on Computer Vision (ICCV), 2019
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:
为了方便读者获取资料以及我们公众号的作者发布一些Github工程的更新,我们成立了一个QQ群,二维码如下,感兴趣可以加入。