
生成对抗网络(GANs)总结
你好,我是郭震
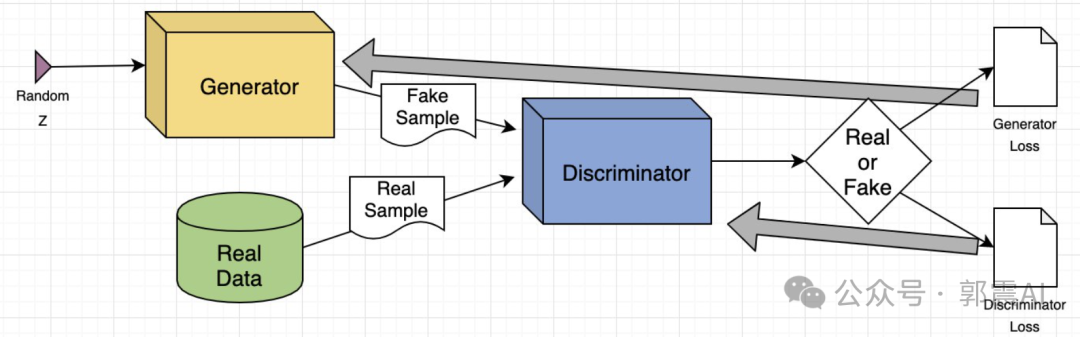
生成对抗网络(GANs)是一种深度学习模型,它由两部分组成:生成器(Generator)和判别器(Discriminator)。
这种模型通过一个对抗的训练过程来生成接近真实的数据。
GANs在图像生成、语音合成、文本到图像转换等领域展示了其强大的能力。
核心概念
生成器(Generator)
- 功能:生成器G是一个深度神经网络,其目标是从随机噪声中生成逼真的数据。它试图创建的数据应足以欺骗判别器,使判别器认为这些数据是真实的。
- 输入:随机噪声,通常来源于某种概率分布,如正态分布。
- 输出:生成的数据,旨在模仿真实世界数据的分布。
判别器(Discriminator)
- 功能:判别器D也是一个深度神经网络,其任务是区分输入数据是来自于真实数据集还是生成器G产生的。
- 输入:真实数据或生成器产生的数据。输出:一个概率值,表示输入数据为真实数据的可能性。
通俗解释:
生成对抗网络(GAN)可以用一个通俗的比喻来解释:想象一个画家(生成器)正在学习如何画出非常逼真的伪造画作,而有一个艺术鉴赏家(判别器)则试图区分出这些画作是真品还是伪造品。开始时,画家的技术可能还不成熟,画出的作品容易被鉴赏家识破。但随着时间的推移,画家从鉴赏家的判断中学习,不断提高自己的画技,使得作品越来越难以被辨认。
在这个比喻中,画家不断尝试创建更逼真的艺术作品,目的是要让鉴赏家无法区分其作品是真是假。而鉴赏家则不断提高自己的辨别能力,以识别出哪些是真正的艺术作品,哪些是伪造的。这个过程就是一种“对抗”的过程,双方都在不断学习和适应对方的策略。
在GAN的训练过程中,生成器(画家)学习如何生成数据(画作),尽量模仿真实的数据分布,而判别器(鉴赏家)则学习如何区分真实数据和生成器生成的数据。最终的目标是让生成器能够生成非常逼真的数据,以至于判别器无法区分生成的数据和真实的数据。
训练过程
GAN的训练涉及到以下步骤:
- 训练判别器:固定生成器G,更新判别器D。使用真实数据和生成的数据训练D,目标是正确分类真实数据和生成数据。
- 训练生成器:固定判别器D,更新生成器G。通过生成数据并尝试欺骗判别器,来提高生成器的生成能力。
目标函数
GAN的目标函数反映了生成器和判别器之间的对抗性质。理想状态下,生成器生成的数据无法被判别器区分。这可以通过以下目标函数来描述:
其中:
- 是判别器和生成器的价值函数。
- 是判别器对于真实数据的判别结果。
- 是生成器基于输入噪声生成的数据。
- 是真实数据的分布。
- 是生成器输入的噪声分布。
训练的目标是通过调整和的参数,找到使最小的G和使最大的
结论
生成对抗网络通过生成器和判别器之间的对抗训练,能够生成高度逼真的数据。
其成功的关键在于找到一个平衡点,即生成器能够生成足够好的数据,使得判别器不能轻易区分真实数据与生成数据。这一过程不仅对深入理解数据分布有重要意义,也为机器学习和人工智能领域的应用开辟了新的可能性。更多:https://zglg.work