
超强语义分割算法!基于语义流的快速而准确的场景解析
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达


论文地址:https://arxiv.org/abs/2002.10120
代码地址:https://github.com/donnyyou/torchcv
该论文提出了一种有效且快速的场景解析方法。通常,提高场景解析或语义分割性能的常用方法是获得具有强大语义表示的高分辨率特征图。广泛使用的有两种策略:使用带孔(空洞)卷积或特征金字塔进行多尺度特征的融合,但会有计算量大、稳定性的考验。
受光流技术启发,通常需要在相邻视频帧之间进行运动对齐,文章中提出了一种流对齐模块(FAM),以学习相邻层级特征图之间的语义流,并有效地将高层特征传播到高分辨率特征当中并进行对齐。此外,将FAM模块集成到一个通用的金字塔结构中,使得即使在非常轻量的骨干网络(如ResNet-18)上,也比其他实时方法具有更高的性能。
实验方面,在几个具有挑战性的数据集上进行了广泛的实验,包括Cityscapes,PASCALContext,ADE20K和CamVid。特别是,网络在Cityscapes上达到80.4%mIoU,帧速率为26 FPS。
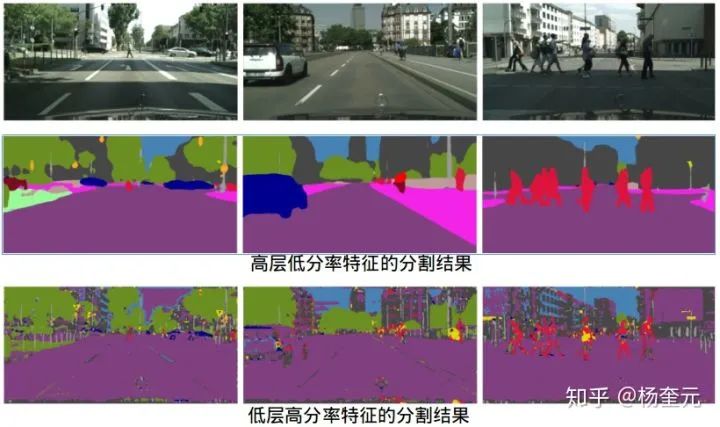
场景解析或语义分割是一项基本的视觉任务,旨在对图像中的每个像素进行正确分类。语义分割具有两大需求,即高分辨率和高层语义,而这两个需求和卷积网络设计是矛盾的。
卷积网络从输入到输出,会经过多个下采样层(一般为5个,输出原图1/32的特征图),从而逐步扩大视野获取高层语义特征,高层语义特征靠近输出端但分辨率低,高分率特征靠近输入端但语义层次低。高层特征和底层特征都有各自的弱点,各自的分割问题如图1所示,第二行高层特征的分割结果保持了大的语义结构,但小结构丢失严重;第三行低层特征的分割结果保留了丰富的细节,但语义类别预测的很差。
FCN(全卷积网络)由于使用了下采样池和卷积层的堆叠,因此缺少对性能至关重要的边界细节信息。为了缓解这个问题,其他方法在其网络的最后几个阶段应用空洞卷积来生成具有强语义表示的特征图,同时保持高分辨率。但是,这样做不可避免地需要进行大量的额外计算。
为了不仅维护详细的分辨率信息,而且获得表现出强大语义表示的特征,另一个方向是建立类似于FPN的模型,该模型利用横向路径以自上而下的方式融合特征图。这样,最后几层的深层特征以高分辨率增强了浅层特征,因此,经过细化的特征有可能满足上述两个因素,并有利于精度的提高。然而,与那些在最后几个阶段持有粗大特征图的网络相比,此类方法仍会遇到精度问题。
FPN(Feature Pyramid Network)
将深层信息上采样,与浅层信息逐元素地相加,从而构建了尺寸不同的特征金字塔结构,性能优越,现已成为目标检测算法的一个标准组件。FPN的结构如下所示。

自下而上:最左侧为普通的卷积网络,默认使用ResNet结构,用作提取语义信息。C1代表了ResNet的前几个卷积与池化层,而C2至C5分别为不同的ResNet卷积组,这些卷积组包含了多个Bottleneck结构,组内的特征图大小相同,组间大小递减。
自上而下:首先对C5进行1×1卷积降低通道数得到P5,然后依次进行上采样得到P4、P3和P2,目的是得到与C4、C3与C2长宽相同的特征,以方便下一步进行逐元素相加。这里采用2倍最邻近上采样,即直接对临近元素进行复制,而非线性插值。
横向连接(Lateral Connection):目的是为了将上采样后的高语义特征与浅层的定位细节特征进行融合。高语义特征经过上采样后,其长宽与对应的浅层特征相同,而通道数固定为256,因此需要对底层特征C2至C4进行11卷积使得其通道数变为256,然后两者进行逐元素相加得到P4、P3与P2。由于C1的特征图尺寸较大且语义信息不足,因此没有把C1放到横向连接中。
卷积融合:在得到相加后的特征后,利用3×3卷积对生成的P2至P4再进行融合,目的是消除上采样过程带来的重叠效应,以生成最终的特征图。
FPN对于不同大小的RoI,使用不同的特征图,大尺度的RoI在深层的特征图上进行提取,如P5,小尺度的RoI在浅层的特征图上进行提取,如P2。
文中认为,精度较差的主要原因在于这些方法从较深层到较浅层的无效语义传递。为了缓解这个问题,文中建议学习具有不同分辨率的层之间的语义流。语义流的灵感来自光流方法,该方法用于在视频处理任务中对齐相邻帧之间的像素。
在语义流的基础上,针对场景解析领域,构造了一种新颖的网络模块,称为流对齐模块(FAM)。它以相邻级别的要素为输入,生成偏移场,然后根据偏移场将粗略特征矫正为具有更高分辨率的精细特征。由于FAM通过非常简单的操作将语义信息从深层有效地传输到浅层,因此在提高准确性和保持超高效率方面都显示出了卓越的功效。而且,所提议的模块是端到端可训练的,并且可以插入任何骨干网络以形成称为SFNet的新网络。
论文主要贡献:
提出了一种新颖的基于流的对齐模块(FAM),以学习相邻级别的特征图之间的语义流,并有效地将高级特征传播到高分辨率的特征。
将FAM模块插入特征金字塔网络(FPN)框架,并构建名为SFNet的特征金字塔对齐网络,以快速准确地进行场景解析。
详细的实验和分析表明,提出的模块在提高精度和保持轻量化方面均有效。在Cityscapes,Pascal Context,ADE20K和Camvid数据集上取得了最先进的结果。具体来说,网络在Cityscapes数据集上实现了80.4%的mIoU,同时在单个GTX 1080Ti GPU上实现了26 FPS的实时速度。
2. 背景
对于场景解析,主要有两种用于高分辨率语义图预测的方法。一种方法是将空间和语义信息都保留在主要路径上,而另一个方法将空间和语义信息分布到网络中的不同部分,然后通过不同的策略将它们融合合并。
第一个方法主要基于空洞卷积,它在网络中保留了高分辨率的特征图。
第二个方法都将特征图缩小到相当低的分辨率,并以很大的比例对它们进行升采样,这会导致结果变差,尤其是对于小物体和物体边界。
之前的方法中主流的做法是,通过双线性插值方法来进行上采样,并且以自上而下的方式将高级特征图逐渐融合为低级特征图,该方法最初是为对象检测提出的,最近用于场景解析或语义分割邻域中。
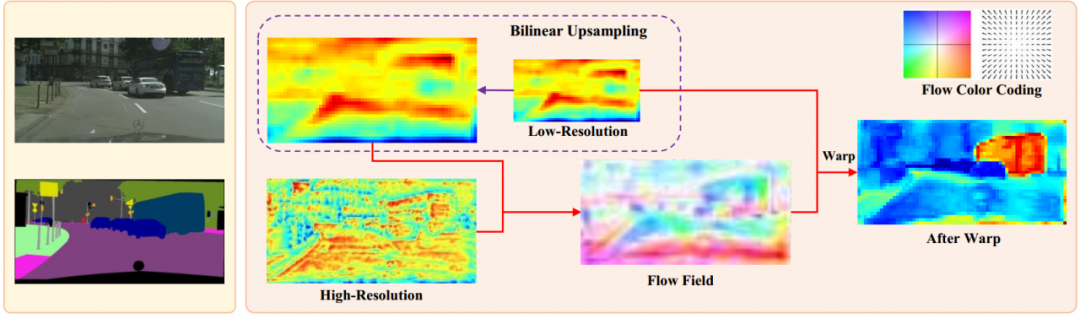
虽然整个设计看起来像具有下采样编码器和上采样解码器的对称性,但是一个重要的问题在于通用和简单的双线性插值上采样算法会破坏对称性。双线性插值上采样通过对一组统一采样的位置进行插值来恢复下采样特征图的分辨率(即,它只能处理一种固定的和预定义的未对准),而由残差连接导致的特征图之间的未对准要复杂得多。因此,需要明确建立特征图之间的对应关系以解决其真正的未对准问题。
光流对准模块(FAM)
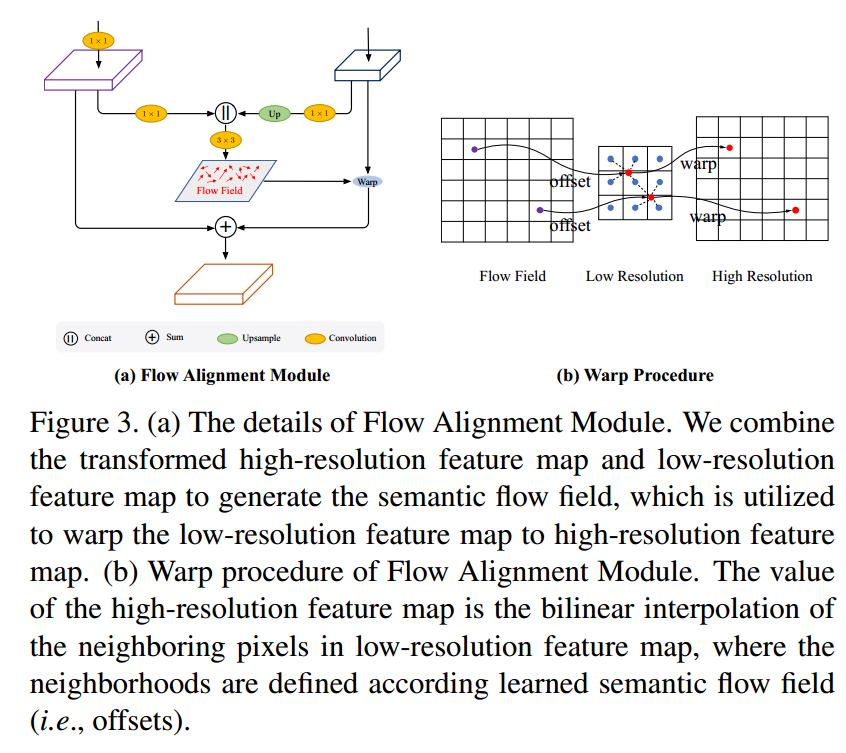
网络结构
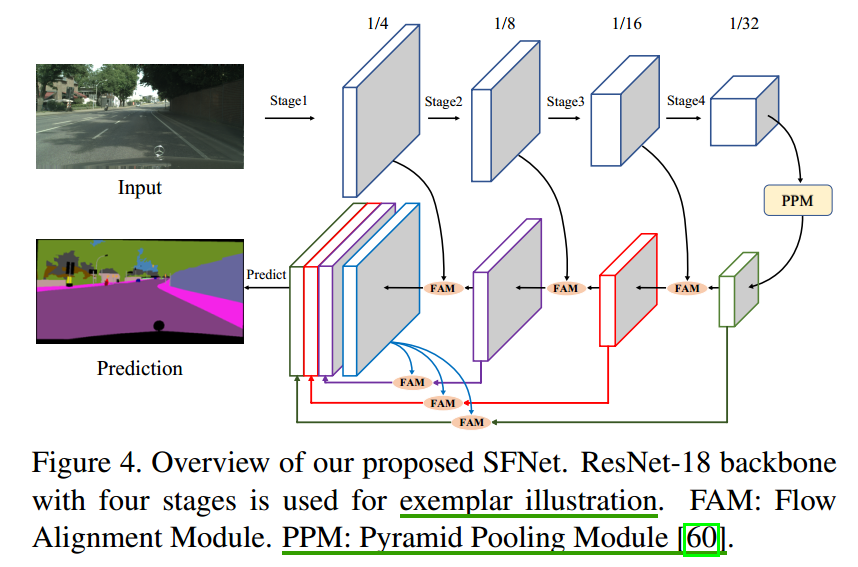
整个网络架构包含自下而上的路径作为编码器和自上而下的路径作为解码器,通过使用上下文建模模块替换完全连接的层,编码器具有与图像分类相同的主干,并且解码器配有FPN(特征金字塔) FAM(光流对齐模块)PPM(金字塔池化模块)。
backbone
通过删除最后一个完全连接的层,选择从ImageNet 预训练的用于图像分类的标准网络作为我们的骨干网络。具体而言,在实验中使用了ResNet系列,ShuffleNet v2 等。所有主干网络具有四个带有残差块的阶段,并且每个阶段在第一卷积层中都有stride=2以对特征图进行下采样,以实现计算效率和更大的感受野。
上下文模块
上下文模块 在场景解析中捕获远程上下文信息起着重要的作用,在本文中采用了金字塔池模块(PPM)(源自PSPNet经典工作)。由于PPM输出的分辨率特征图与最后一个残差模块相同,因此将PPM和最后一个残差模块一起视为FPN的最后一个阶段。其他模块,例如ASPP 也可以很容易地以类似的方式插入整个网络的体系结构当中,“实验”部分进行了验证。
具有对齐模块的FPN(特征金字塔)
编码器得到特征图后送入解码器阶段,并将对齐的特征金字塔用于最终场景解析语义分割任务。在FPN的自上而下的路径中用FAM替换正常的双线性插值实现上采样。
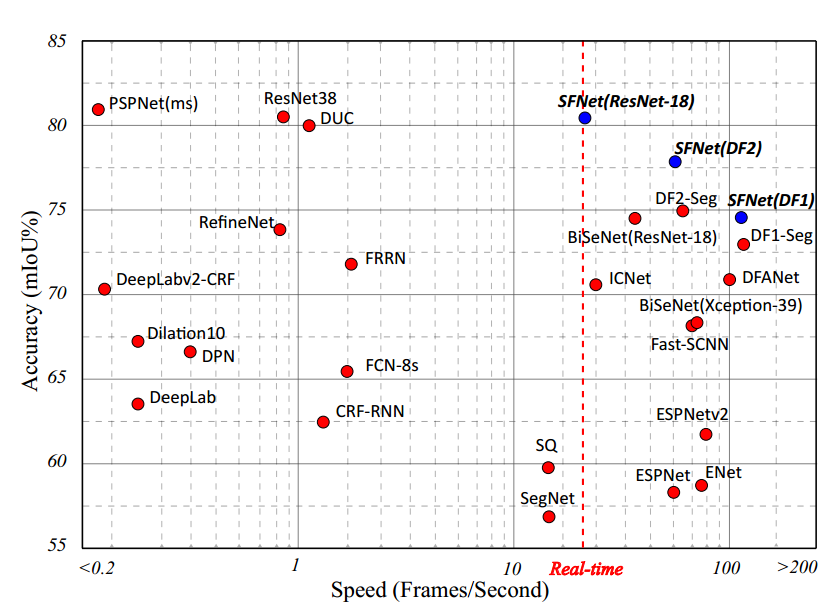
Cityscapes数据集上的实验
实现细节:使用PyTorch 框架进行以下实验。所有网络都在相同的设置下训练,其中批量大小为16的随机梯度下降(SGD)被用作优化器,动量为0.9,重量衰减为5e-4。所有模型都经过50K迭代训练,初始学习率为0.01。数据扩充包含随机水平翻转,缩放范围为[0.75,2.0]的随机大小调整以及裁剪大小为1024×1024的随机裁剪。

表1.以ResNet-18为骨干的基线方法的消融研究

几乎可以改善所有类别,特别是对于卡车而言,mIoU改善了19%以上。下图可视化了这两种方法的预测误差,其中FAM极大地解决了大型物体(例如卡车)内部的歧义,并为较小和较薄的物体(例如杆,墙的边缘)产生了更精确的边界。

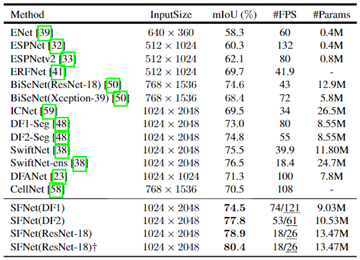
表. Cityscapes测试集测试效果与最新实时模型的比较。为了公平比较,还考虑了输入大小,并且所有模型都使用单比例推断。
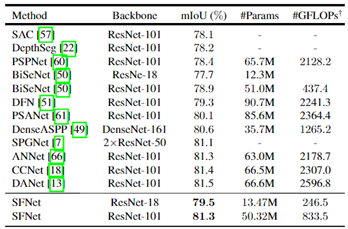
表7. Cityscapes测试集测试效果与最新模型的比较。为了获得更高的准确性,所有模型都使用多尺度推断。
更多实验细节,可关注原文。
在本文中使用所提出的流对齐模块,高级特征可以很好地流向具有高分辨率的低级特征图。通过丢弃无用的卷积以减少计算开销,并使用流对齐模块来丰富低级特征的语义表示,我们的网络在语义分割精度和运行时间效率之间实现了最佳折衷。在多个具有挑战性的数据集上进行的实验说明了我们方法的有效性。由于我们的网络非常高效,并且具有与光流方法相同的思路来对齐不同的地图(即不同视频帧的特征图),因此它可以自然地扩展到视频语义分割中,从而在层次上和时间上对齐特征图。此外,也可以将语义流的概念扩展到其他相关领域,例如全景分割等。
当然,这里面还要很多问题待探究,比如:
1、用于特征对齐的最优网络结构应该怎么设计?目前是采用了类似FlowNet-S的结构,FlowNet-C结构不适合于该任务,原因是高低层特征之间不能像前后帧图像对应层特征之间算相似性。
2、高低层特征对不齐的原因是什么?
3、能否在对不齐发生时就记录下来,而不是事后补救(类似SegNet那种记录Pooling Indices的方式)?
参考
1、目标检测系列秘籍三:多尺度检测
2、知乎文章:https://zhuanlan.zhihu.com/p/110667995
好消息!
小白学视觉知识星球
开始面向外开放啦👇👇👇
下载1:OpenCV-Contrib扩展模块中文版教程 在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。 下载2:Python视觉实战项目52讲 在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。 下载3:OpenCV实战项目20讲 在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。 交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~