
颠覆大规模预训练!清华杨植麟组提出全新NLP学习框架TLM,学习效率×100倍
新智元报道
新智元报道
作者:yxc
编辑:好困
【新智元导读】近期,清华大学团队提出一种无需预训练的高效NLP学习框架,在仅使用了1%的算力和1%的训练语料的条件下,在众多NLP任务上实现了比肩甚至超越预训练模型的性能。这一研究结果对大规模预训练语言模型的必要性提出了质疑:我们真的需要大规模预训练来达到最好的效果吗?

论文地址:https://arxiv.org/pdf/2111.04130.pdf
项目地址:https://github.com/yaoxingcheng/TLM
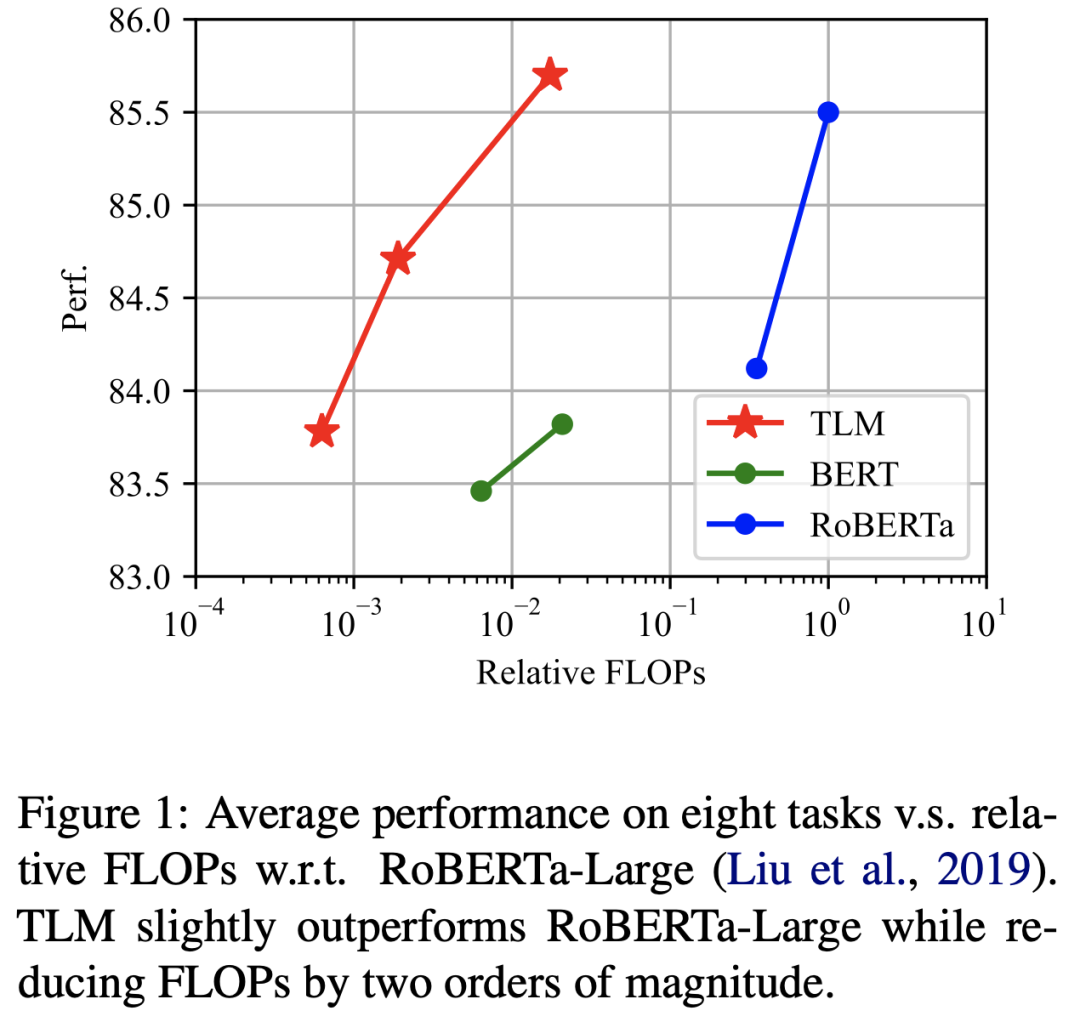
TLM框架无需进行大规模预训练,仅需要相较于传统预训练模型(例如 RoBERTa)约 1% 的训练时间与 1% 的语料, 即可在众多任务上实现和预训练模型比肩甚至更好的性能。
作者希望TLM的提出能够引发NLP研究者们对现有预训练-微调范式的重新审视,并促进NLP民主化的进程,加速NLP领域的进一步发展。
语言模型也可以「临时抱佛脚」?
任务驱动的语言建模
我们有这样的观察:人类可以以有限的时间和精力高效掌握某种技能,这整个过程并不需要掌握所有可能的知识和信息,而是只需要对核心的部分有针对性地学习。
例如,考生考试前临时抱佛脚,仅需要突击学习重点内容即可应对考试。受到这一现象的启发,我们不禁发问:预训练语言模型可以「临时抱佛脚」吗?
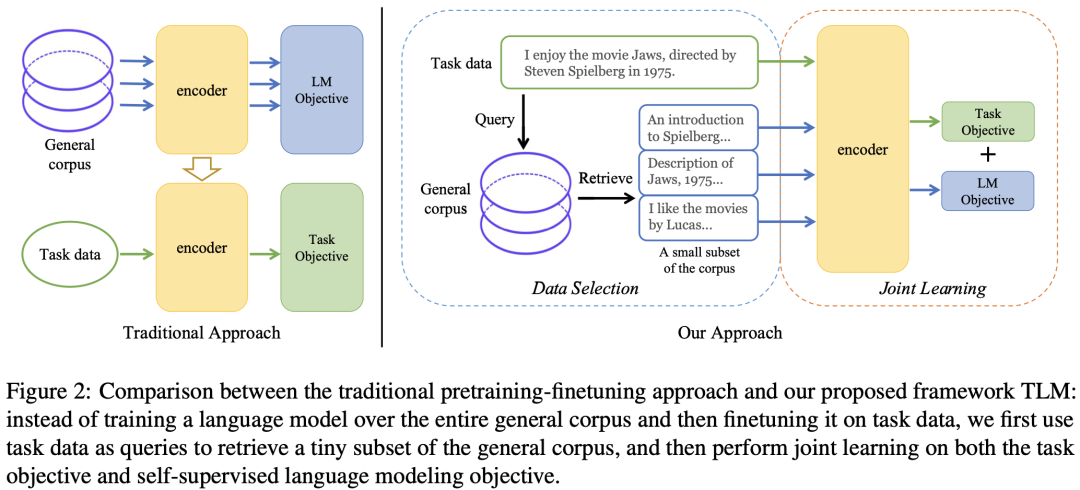
传统的预训练-微调方法与TLM框架之间的比较
类似地,作者提出假设:预训练语言模型在特定任务上的性能,仅受益于大规模通用语料中仅与任务相关的部分,而不需要大规模的全量数据。
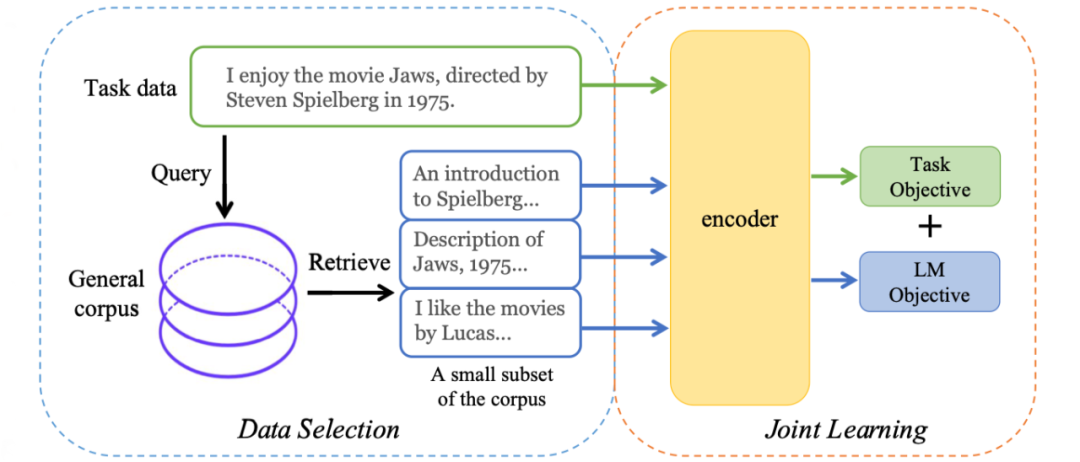
该方法主要包含两个阶段:
为了从大规模通用语料中抽取关键数据,TLM首先以任务数据作为查询,对通用语料库进行相似数据的召回; TLM基于任务数据和召回数据,从零开始进行基于任务目标和语言建模目标的联合训练。
基于任务数据的语料召回
首先根据任务数据,从大规模通用语料中抽取相关数据。
相比于大多数文本匹配算法倾向于采用稠密特征,本文作者另辟蹊径,采用了使用基于稀疏特征的BM25算法[2] 作为召回算法,它简单高效,并且不依赖于下游任务给出的监督信号。
同时该算法完全不依赖预训练模型,从而可以公平地与传统的大规模预训练进行比较。
自监督任务与下游任务的联合训练
TLM基于筛选后的通用预料数据和任务数据,进行了自监督任务与下游任务的联合训练。
作者采用了传统的掩码语言模型(Masked Language Modeling)作为自监督训练任务。
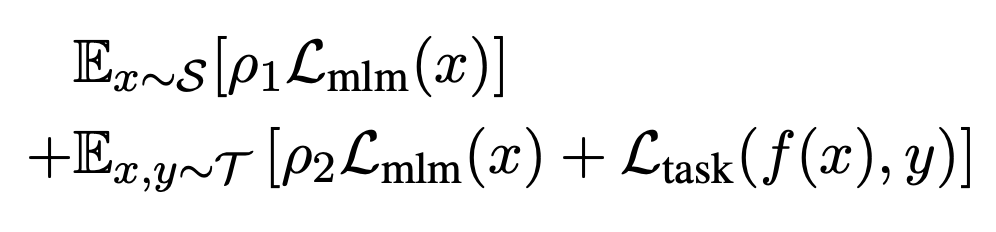
训练的损失函数
实验结果:小资源比肩大规模预训练语言
主要结果
作者在8个自然语言分类任务上,从三个不同的规模分别开展了对比实验。这些任务涵盖了生物医药、新闻、评论、计算机等领域,并且覆盖了情感分类、实体关系抽取、话题分类等任务类型。
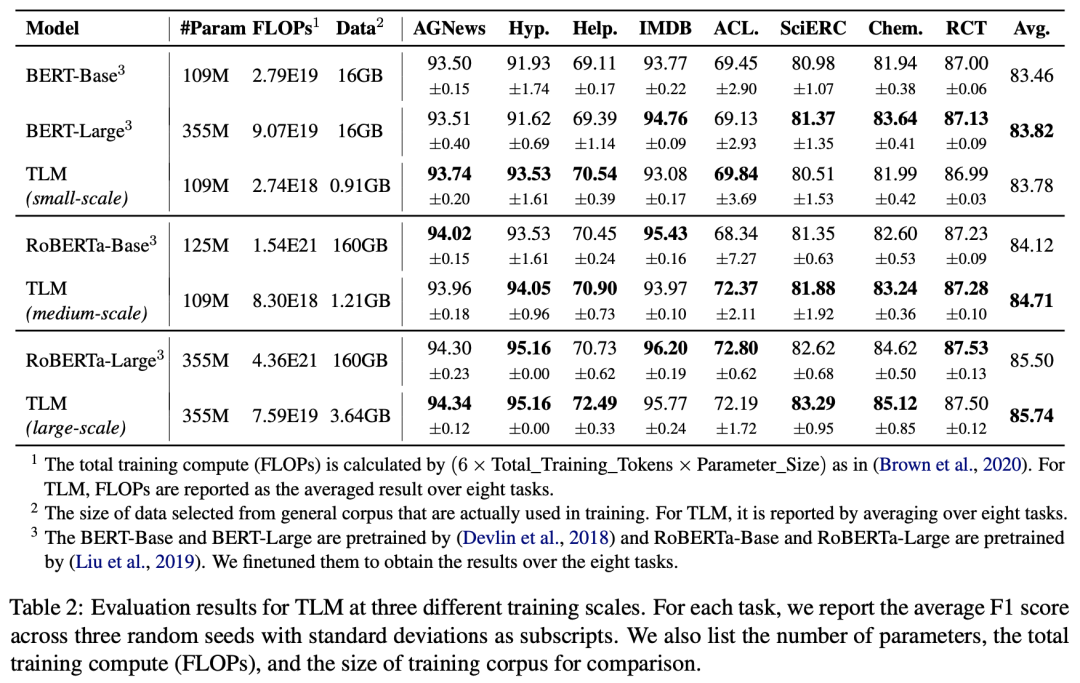
TLM在三种不同训练规模下的评估结果
和传统的预训练-微调范式相比,TLM在多领域多任务类型的数据集上实现了大致相当甚至更优的结果。
而更大的优势在于,TLM实现该相当甚至更优的结果所使用的资源(包括计算量FLOPs和使用的训练数据量),相较于对应预训练-微调基准的资源使用量极大减少约两个数量级规模。
参数高效性分析
为了探究TLM高效性更本质的来源,作者们对模型的每个注意力头所输出的注意力结果进行了可视化分析。
已有研究[1]指出,呈现「对角线」模式的注意力结果(如红框所示)是对模型性能影响的关键因素,因为「对角线」模式把注意力关注于此前或者此后的符号(token)上,从而可以捕捉和建模相邻符号之间的关联性。

注意力结果可视化分析
从可视化结果可以观察到,TLM中包含了更多「对角线」模式,即有更多的符号位置都将注意力分散赋予了其相邻的其他符号。
对比之下,原始的大规模预训练模型(BERT-Base和RoBERTa-Base)「对角线」模式较少,而「垂直」模式更多(如灰色所示),这意味着更多符号位置将注意力关注到[CLS]、[SEP]或者标点符号这种不具备语法或者语义信息的符号上。
可以看出,TLM的参数高效性要显著优于预训练语言模型,任务驱动使得TLM针对下游任务学习到了更丰富的语法语义信息。
消融实验
此外作者还分别在数据选取策略、数据召回数量、多任务学习目标权重等多个角度进行了消融实验探究,以此考察模型性能的稳定性和最优配置。
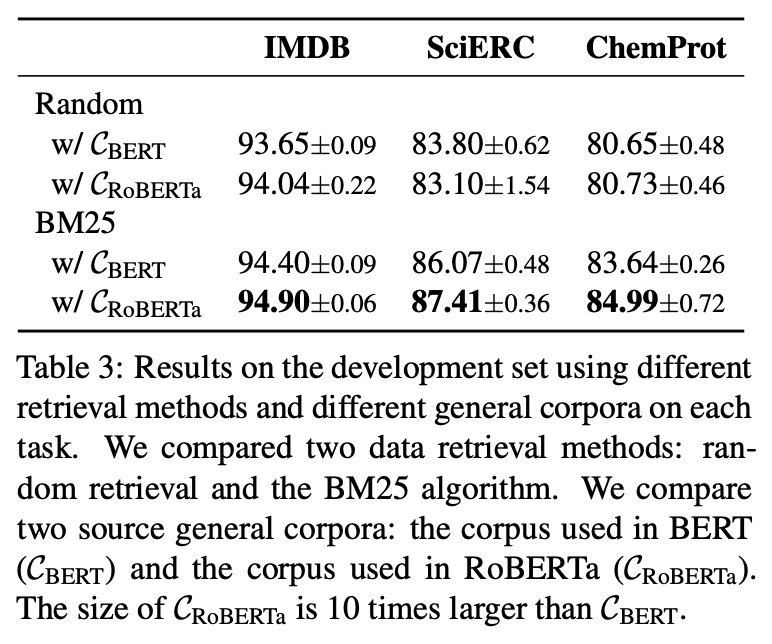
数据选取策略消融实验结果
在数据召回策略上,相比起同等数量的随机选取,基于稀疏特征的BM25算法最终结果有显著提升(约1-4个点),证明其在召回和任务数据相似的通用数据上的有效性。
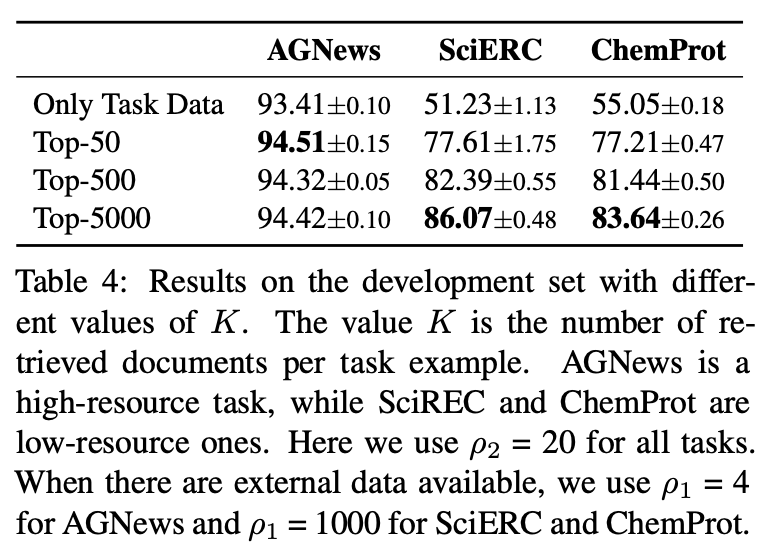
最优数据召回量消融实验结果
对于最优数据召回量和多任务学习目标权重两因素的消融实验结果展示出一致的结论:即两因素的选择显示出和任务数据规模强相关性:
对于数据规模较大的任务(如AGNews,RCT),它需要召回相对更少的相似通用数据,同时应赋予任务数据目标更大的比重;
对于数据规模较小的任务(如ChemProt,SciERC),它需要召回相对更多的通用数据提供充足信息,同时赋予召回通用数据上的无监督训练目标更大的权重。
TLM vs PLM:优势如何?
总结来说,PLM以极高的成本学习尽可能多的任务无关的知识,而TLM以非常低的成本针对每个任务学习相关知识。
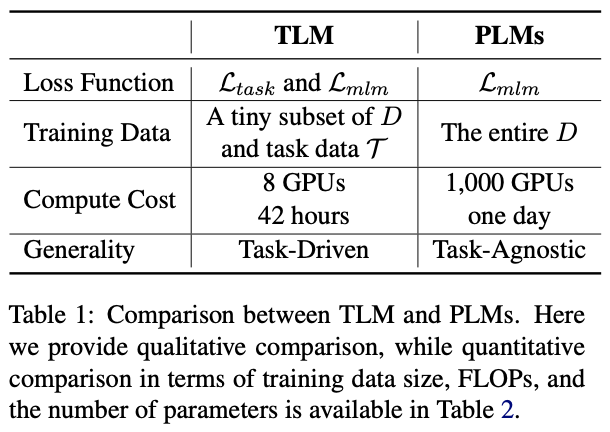
TLM和PLM的对比
具体来说,TLM和PLM相比还具有如下特点:
1. 民主化
TLM的提出打破了NLP研究受限于大规模计算资源,以及只能由极少数机构和人员开展相关探索的现状。基于TLM框架,大多数NLP研究者都可以以较低代价以及较高效率,对目前最先进的解决方案做更进一步的自由探索和研究。
2. 灵活性
相比PLM,TLM允许研究者以更加灵活的方式根据具体的任务自定义标记策略、数据表示、序列长度、超参数等等。这使得进一步提升性能和效率成为可能。
3. 高效性
如实验结果所示,TLM的每个任务上的FLOPs消耗显著少于PLM。TLM和PLM分别适用不同情况——当面临少数目标任务或者领域特定的稀有任务(例如,NLP科研工作开展过程对少数数据集进行实验和研究;工业界面临极其特殊领域问题的解决),TLM是非常高效的选择;当需要一次性解决大量相似且常见任务时(例如,公司需要构建统一平台为多方提供相似服务),PLM的可重复利用使其仍然具备优势。
4. 通用性
PLM学习任务无关的一般性表示,即强调通用性,而TLM通过学习任务相关的表示一定程度牺牲通用性换取更高的效率。当然,也可以将PLM和TLM结合从而实现通用性和效率之间更好的权衡。
总结展望
TLM的提出给自然语言处理领域带来「新面貌」,它使得现有NLP的研究可以脱离代价高昂的预训练,也使得更多独立NLP研究者们可以在更广阔的空间进行自由探索成为可能。
未来可以进一步开展更多基于TLM框架的研究,例如:如何进一步提升TLM的通用性和可迁移性;如何更加经济地达到更大规模预训练模型的表现效果等等。
作者介绍
论文一作为清华大学姚班大四本科生姚星丞,他也是今年大火的EMNLP接收论文SimCSE的共同一作。

论文的通讯作者为清华大学交叉信息院助理教授、Recurrent AI联合创始人杨植麟,曾做出Transformer-XL、XLNet、HotpotQA等诸多NLP领域大受欢迎的工作。
论文的另外两名作者郑亚男和杨小骢也来自清华大学,其中郑亚男是今年年初备受瞩目的P-tuning(GPT Understands, Too)的共同一作。

论文地址:https://arxiv.org/pdf/2103.10385.pdf
参考资料:
[1] Elena Voita, David Talbot, Fedor Moiseev, Rico Sennrich, and Ivan Titov. 2019. Analyzing multi-head self-attention: Specialized heads do the heavy lifting, the rest can be pruned. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 5797–5808, Florence, Italy. Association for Computational Linguistics.
[2] Stephen E. Robertson and Hugo Zaragoza. 2009. The probabilistic relevance framework: BM25 and beyond. Found. Trends Inf. Retr., 3(4):333–389.
