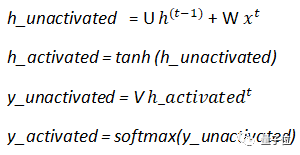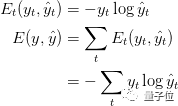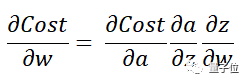hidden_dim = 100 output_dim = 80# this is the total unique words in the vocabulary input_weights = np.random.uniform(0, 1, (hidden_dim,hidden_dim)) internal_state_weights = np.random.uniform(0,1, (hidden_dim, hidden_dim)) output_weights = np.random.uniform(0,1, (output_dim,hidden_dim))
input_string = [2,45,10,65] embeddings = [] # this is the sentence embedding list that contains the embeddings for each word for i in range(0,T): x = np.random.randn(hidden_dim,1) embeddings.append(x)
deftanh_activation(Z): return (np.exp(Z)-np.exp(-Z))/(np.exp(Z)-np.exp(-Z)) # this is the tanh function can also be written as np.tanh(Z) defsoftmax_activation(Z): e_x = np.exp(Z - np.max(Z)) # this is the code for softmax function return e_x / e_x.sum(axis=0)
defcalculate_loss(output_mapper,predicted_output): total_loss = 0 layer_loss = [] for y,y_ in zip(output_mapper.values(),predicted_output): # this for loop calculation is for the first equation, where loss for each time-stamp is calculated loss = -sum(y[i]*np.log2(y_[i]) for i in range(len(y))) loss = loss/ float(len(y)) layer_loss.append(loss) for i in range(len(layer_loss)): #this the total loss calculated for all the time-stamps considered together. total_loss = total_loss + layer_loss[i] return total_loss/float(len(predicted_output))
defdelta_cross_entropy(predicted_output,original_t_output): li = [] grad = predicted_output for i,l in enumerate(original_t_output): #check if the value in the index is 1 or not, if yes then take the same index value from the predicted_ouput list and subtract 1 from it. if l == 1: #grad = np.asarray(np.concatenate( grad, axis=0 )) grad[i] -= 1 return grad
defadd_backward(x1,x2,dz):# this function is for calculating the derivative of ht_unactivated function dx1 = dz * np.ones_like(x1) dx2 = dz * np.ones_like(x2) return dx1,dx2
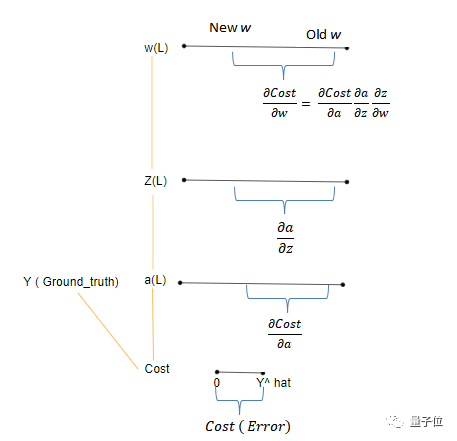
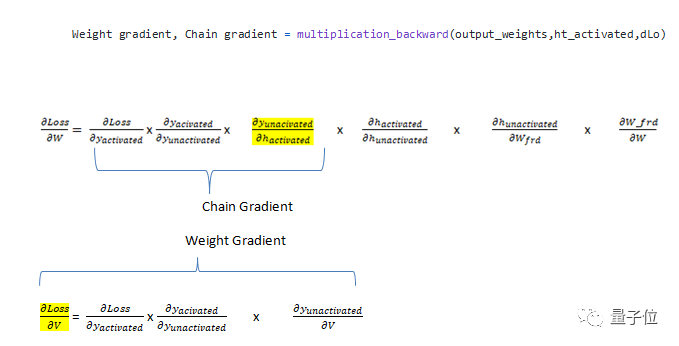
defsingle_backprop(X,input_weights,internal_state_weights,output_weights,ht_activated,dLo,forward_params_t,diff_s,prev_s):# inlide all the param values for all the data thats there W_frd = forward_params_t[0][0] U_frd = forward_params_t[0][1] ht_unactivated = forward_params_t[0][2] yt_unactivated = forward_params_t[0][3] dV,dsv = multiplication_backward(output_weights,ht_activated,dLo) ds = np.add(dsv,diff_s) # used for truncation of memory dadd = tanh_activation_backward(ht_unactivated, ds) dmulw,dmulu = add_backward(U_frd,W_frd,dadd) dW, dprev_s = multiplication_backward(internal_state_weights, prev_s ,dmulw) dU, dx = multiplication_backward(input_weights, X, dmulu) #input weights return (dprev_s, dU, dW, dV)
对于RNN,由于存在梯度消失的问题,所以采用的是截断的反向传播,而不是使用原始的。
在此技术中,当前单元将只查看k个时间戳,而不是只看一次时间戳,其中k表示要回溯的先前单元的数量。
defrnn_backprop(embeddings,memory,output_t,dU,dV,dW,bptt_truncate,input_weights,output_weights,internal_state_weights): T = 4 # we start the backprop from the first timestamp. for t in range(4): prev_s_t = np.zeros((hidden_dim,1)) #required as the first timestamp does not have a previous memory, diff_s = np.zeros((hidden_dim,1)) # this is used for the truncating purpose of restoring a previous information from the before level predictions = memory["yt" + str(t)] ht_activated = memory["ht" + str(t)] forward_params_t = memory["params"+ str(t)] dLo = delta_cross_entropy(predictions,output_t[t]) #the loss derivative for that particular timestamp dprev_s, dU_t, dW_t, dV_t = single_backprop(embeddings[t],input_weights,internal_state_weights,output_weights,ht_activated,dLo,forward_params_t,diff_s,prev_s_t) prev_s_t = ht_activated prev = t-1 dLo = np.zeros((output_dim,1)) #here the loss deriative is turned to 0 as we do not require it for the turncated information. # the following code is for the trunated bptt and its for each time-stamp. for i in range(t-1,max(-1,t-bptt_truncate),-1): forward_params_t = memory["params" + str(i)] ht_activated = memory["ht" + str(i)] prev_s_i = np.zeros((hidden_dim,1)) if i == 0else memory["ht" + str(prev)] dprev_s, dU_i, dW_i, dV_i = single_backprop(embeddings[t] ,input_weights,internal_state_weights,output_weights,ht_activated,dLo,forward_params_t,dprev_s,prev_s_i) dU_t += dU_i #adding the previous gradients on lookback to the current time sequence dW_t += dW_i dV += dV_t dU += dU_t dW += dW_t return (dU, dW, dV)
权重更新
一旦使用反向传播计算了梯度,则更新权重势在必行,而这些是通过批量梯度下降法
defgd_step(learning_rate, dU,dW,dV, input_weights, internal_state_weights,output_weights ): input_weights -= learning_rate* dU internal_state_weights -= learning_rate * dW output_weights -=learning_rate * dV return input_weights,internal_state_weights,output_weights
训练序列
完成了上述所有步骤,就可以开始训练神经网络了。
用于训练的学习率是静态的,还可以使用逐步衰减等更改学习率的动态方法。
deftrain(T, embeddings,output_t,output_mapper,input_weights,internal_state_weights,output_weights,dU,dW,dV,prev_memory,learning_rate=0.001, nepoch=100, evaluate_loss_after=2): losses = [] for epoch in range(nepoch): if(epoch % evaluate_loss_after == 0): output_string,memory = full_forward_prop(T, embeddings ,input_weights,internal_state_weights,prev_memory,output_weights) loss = calculate_loss(output_mapper, output_string) losses.append(loss) time = datetime.now().strftime('%Y-%m-%d %H:%M:%S') print("%s: Loss after epoch=%d: %f" % (time,epoch, loss)) sys.stdout.flush() dU,dW,dV = rnn_backprop(embeddings,memory,output_t,dU,dV,dW,bptt_truncate,input_weights,output_weights,internal_state_weights) input_weights,internal_state_weights,output_weights= sgd_step(learning_rate,dU,dW,dV,input_weights,internal_state_weights,output_weights) return losses