
Flink 实时计算在微博的应用
微博介绍
数据计算平台介绍
Flink 在数据计算平台的典型应用
 GitHub 地址
GitHub 地址 一、微博介绍

二、数据计算平台介绍
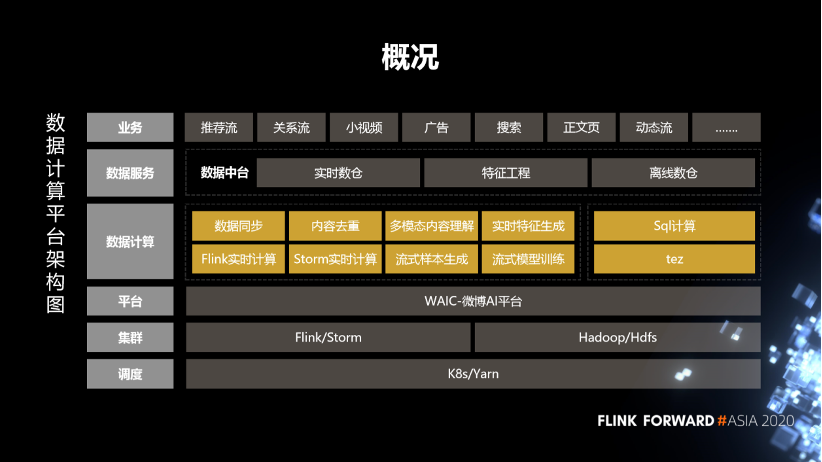
1. 数据计算平台概况
首先是调度,这块基于 K8s 和 Yarn 分别部署了实时数据处理的 Flink、Storm,以及用于离线处理的 SQL 服务。
在集群之上,我们部署了微博的 AI 平台,通过这个平台去对作业、数据、资源、样本等进行管理。
在平台之上我们构建了一些服务,通过服务化的方式去支持各个业务方。
实时计算这边的服务主要包括数据同步、内容去重、多模态内容理解、实时特征生成、实时样本拼接、流式模型训练,这些是跟业务关系比较紧密的服务。另外,还支持 Flink 实时计算和 Storm 实时计算,这些是比较通用的基础计算框架。 离线这部分,结合 Hive 的 SQL,SparkSQL 构建一个 SQL 计算服务,目前已经支持了微博内部绝大多数的业务方。
数据的输出是采用数仓、特征工程这些数据中台的组建,对外提供数据输出。整体上来说,目前我们在线跑的实时计算的作业将近 1000 多个,离线作业超过了 5000 多个,每天处理的数据量超过了 3 PB。
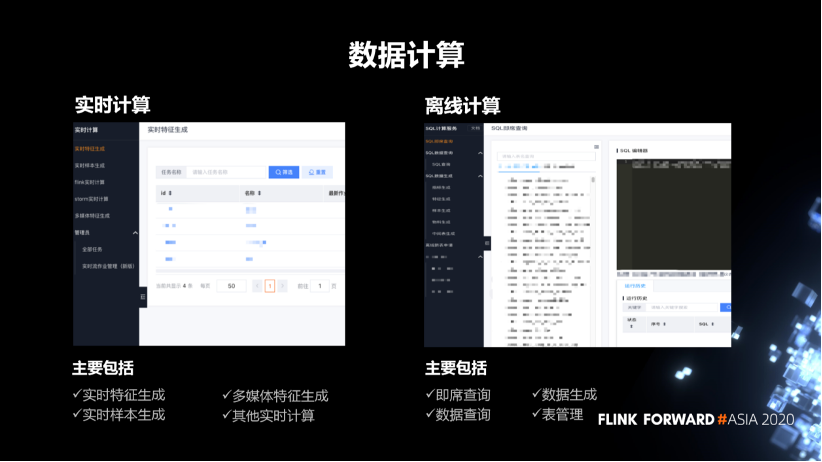
2. 数据计算
实时计算主要包括实时的特征生成,多媒体特征生成和实时样本生成,这些跟业务关系比较紧密。另外,也提供一些基础的 flink 实时计算和 storm 实时计算。
离线计算主要包括 SQL 计算。主要包括 SQL 的即席查询、数据生成、数据查询和表管理。表管理主要就是数仓的管理,包括表的元数据的管理,表的使用权限,还有表的上下游的血缘关系。
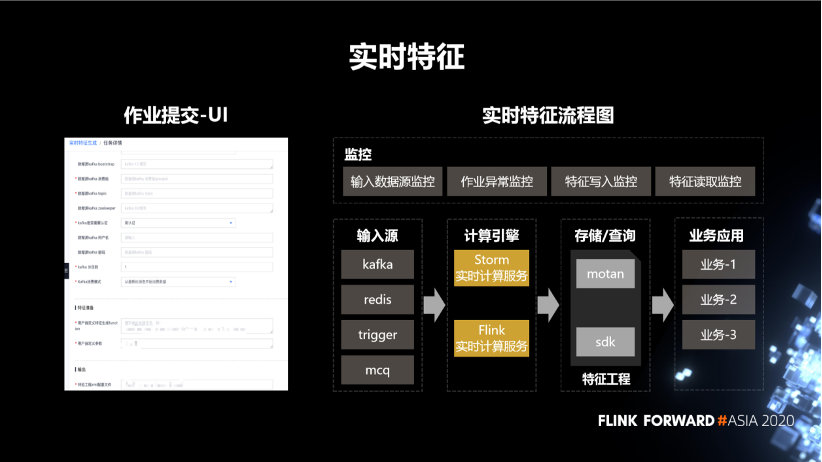
3. 实时特征
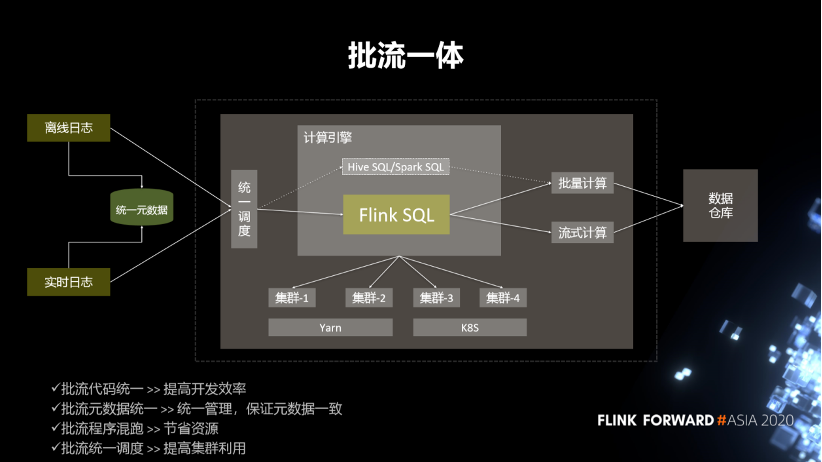
4. 流批一体
第一,批流代码统一,提高开发效率。
第二,批流元数据统一。统一管理,保证元数据一致。
第三,批流程序混跑,节省资源。
第四,批流统一调度,提高集群利用率。
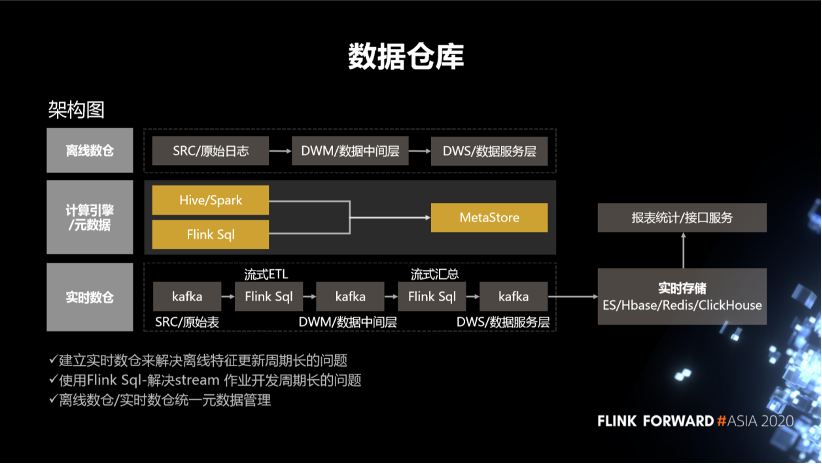
5. 数据仓库
针对离线仓库,我们把数据分成了三层,一个是原始日志,另外一个是中间层,还有一个是数据服务层。中间是元数据的统一,下边是实时数仓。
针对实时数仓,我们通过 FlinkSQL 对这些原始日志做流式的一个 ETL,再通过一个流式汇总将最终的数据结果写到数据的服务层,同时也会把它存储到各种实时存储,比如 ES、Hbase、Redis、ClickHouse 中去。我们可以通过实时存储对外提供数据的查询。还提供数据进一步数据计算的能力。也就是说,建立实时数仓主要是去解决离线特征生成的周期长的问题。另外就是使用 FlinkSQL 去解决 streaming 作业开发周期比较长的问题。其中的一个关键点还是离线数仓跟实时数仓的元数据的管理。
三、Flink 在数据计算平台的典型应用
1. 流式机器学习
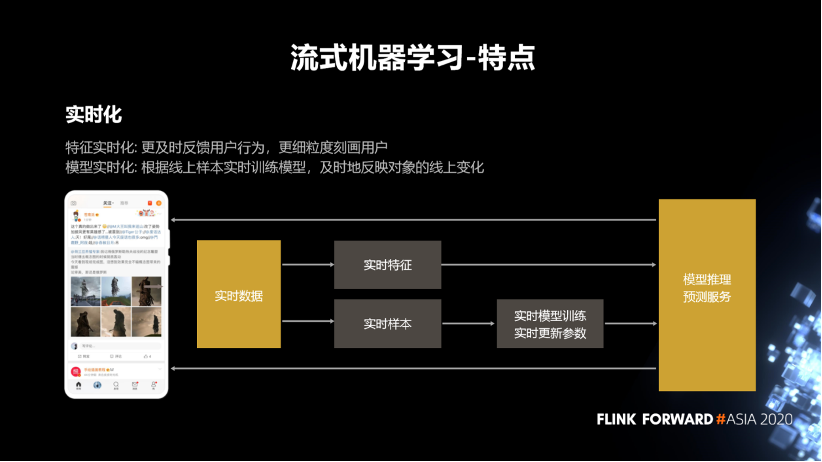
特征实时化主要是为了更及时的去反馈用户行为,更细粒度的去刻画用户。
模型实时化是要根据线上样本实时训练模型,及时反映对象的线上变化情况。
样本的规模大,目前的实时样本能达到百万级别的 qps。
模型的规模大。模型训练参数这块,整个框架会支持千亿级别的训练规模。
对作业的稳定性要求比较高。
样本的实时性要求高。
模型的实时性高。
平台业务需求多。
一个就是全链路,端到端的链路是比较长的。比如说,一个流式机器学习的流程会从日志收集开始,到特征生成,再到样本生成,然后到模型训练,最终到服务上线,整个流程非常长。任何一个环节有问题,都会影响到最终的用户体验。所以我们针对每一个环节都部署了一套比较完善的全链路的监控系统,并且有比较丰富的监控指标。
另外一个是它的数据规模大,包括海量的用户日志,样本规模和模型规模。我们调研了常用的实时计算框架,最终选择了 Flink 去解决这个问题。

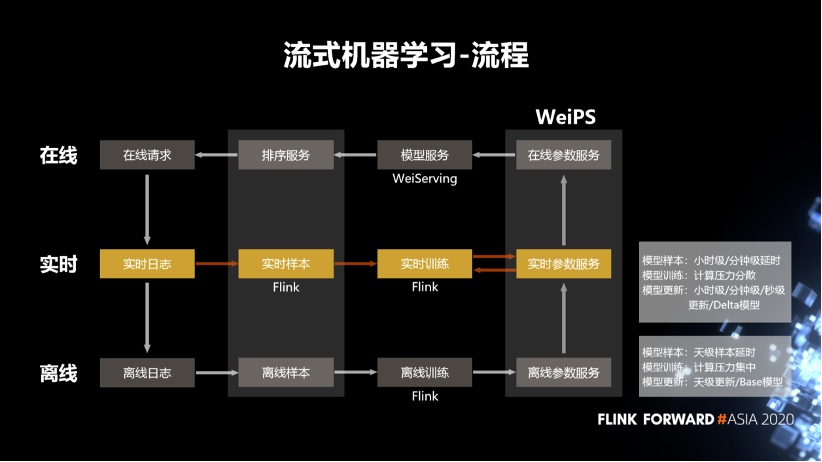
首先是离线训练,我们拿到离线日志,去离线的生成样本之后,通过Flink去读取样本,然后去做离线训练。训练完成之后把这些训练的结果参数保存在离线的参数服务器中。这个结果会作为模型服务的 Base 模型,用于实时的冷启动。
然后是实时的流式机器学习的流程。我们会去拉取实时的日志,比如说微博的发布内容,互动日志等。拉取这些日志之后,使用 Flink 去生成它的样本,然后做实时的训练。训练完成之后会把训练的参数保存在一个实时的参数服务器中,然后会定期的从实时的参数服务器同步到实时的参数服务器中。
最后是模型服务这一块,它会从参数服务中拉取到模型对应的那些参数,去推荐用户特征,或者说物料的特征。通过模型对用户和物料相关的特征、行为打分,然后排序服务会调取打分的结果,加上一些推荐的策略,去选出它认为最适合用户的这一条物料,并反馈给用户。用户在客户端产生一些互动行为之后,又发出新的在线请求,产生新的日志。所以整个流式学习的流程是一个闭环的流程。
离线的样本的延时和模型的更新是天级或者小时级,而流式则达到了小时级或者分钟级;
离线模型训练的计算压力是比较集中的,而实时的计算压力比较分散。
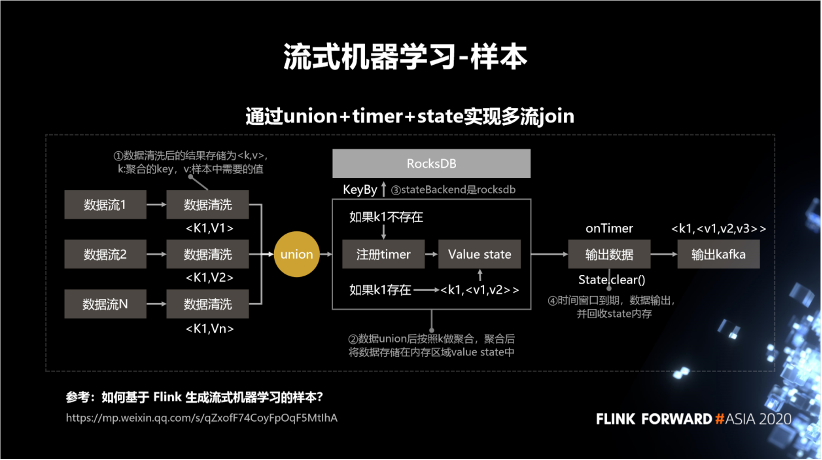
如果 k1 不存在,则注册 timer,再存到 state 中。
如果 k1 存在,就从 state 中把它给拿出来,更新之后再存进去。到最后它的 timer 到期之后,就会将这条数据输出,并且从 state 中清除掉。
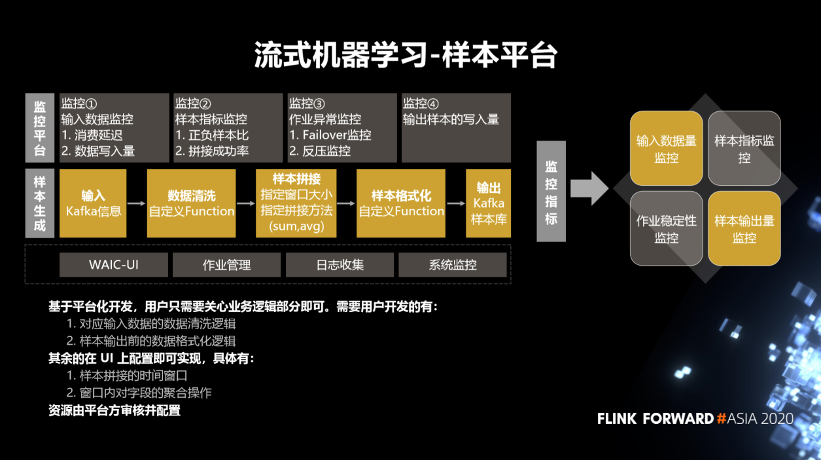
对应输入数据的数据清洗逻辑。
样本输出前的数据格式化逻辑。
样本拼接的时间窗口。
窗口内对字段的聚合操作。

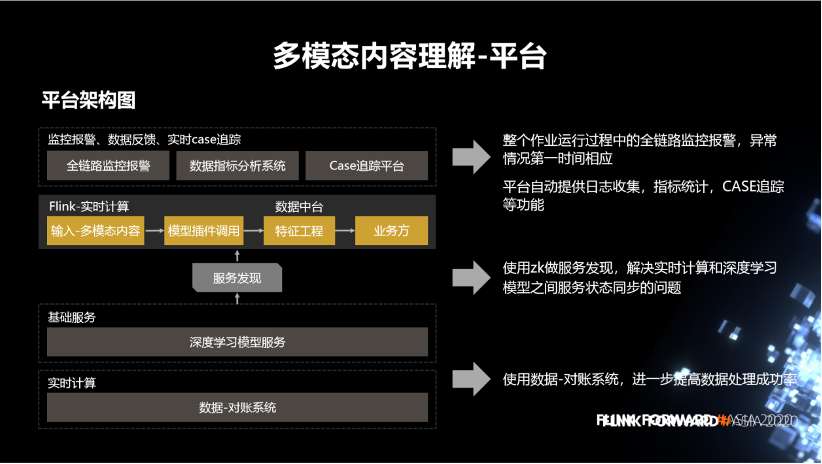
2. 多模态内容理解
图片这块包括,物体识别打标签、OCR、人脸、明星、颜值、智能裁剪。
视频这块包括版权检测、logo 识别。
音频这块有,语音转文本、音频的标签。
文本主要包括文本的分词、文本的时效性、文本的分类标签。


3. 内容去重服务

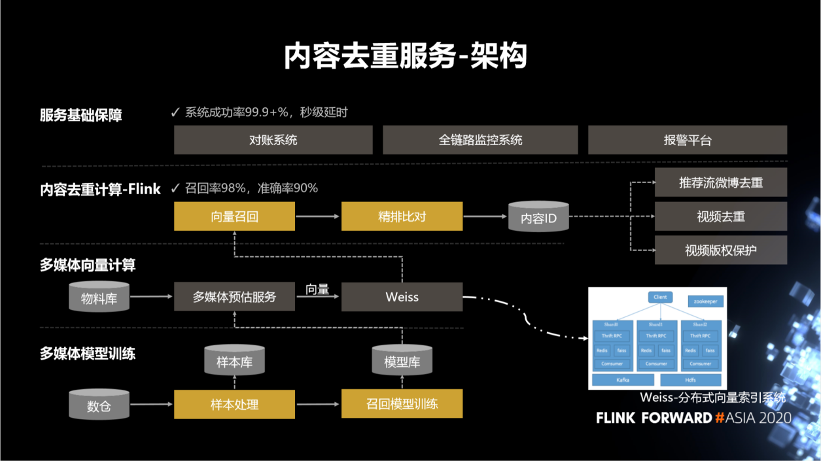
第一,支持视频版权 - 盗版视频识别 - 稳定性 99.99%,盗版识别率 99.99%。
第二,支持全站微博视频去重 - 推荐场景应用 - 稳定性 99.99%,处理延迟秒级。
第三,推荐流物料去重 - 稳定性 99%,处理延迟秒级,准确率达到 90%

评论