
Flink在实时在实时计算平台和实时数仓中的企业级应用小结
点击上方蓝色字体,选择“设为星标”
回复”资源“获取更多资源

大数据领域自 2010 年开始,以 Hadoop、Hive 为代表的离线计算开始进入各大公司的视野。大数据领域开始了如火如荼的发展。我个人在学校期间就开始关注大数据领域的技术迭代和更新,并且有幸在毕业后成为大数据领域的开发者。
Flink 实时计算
我是抖音主播,我想看带货销售情况的排行?我是运营,我想看到我们公司销售商品的 TOP10?我是开发,我想看到我们公司所有生产环境中服务器的运行情况?......
Flink 实时数据仓库

技术选型
实时计算引擎
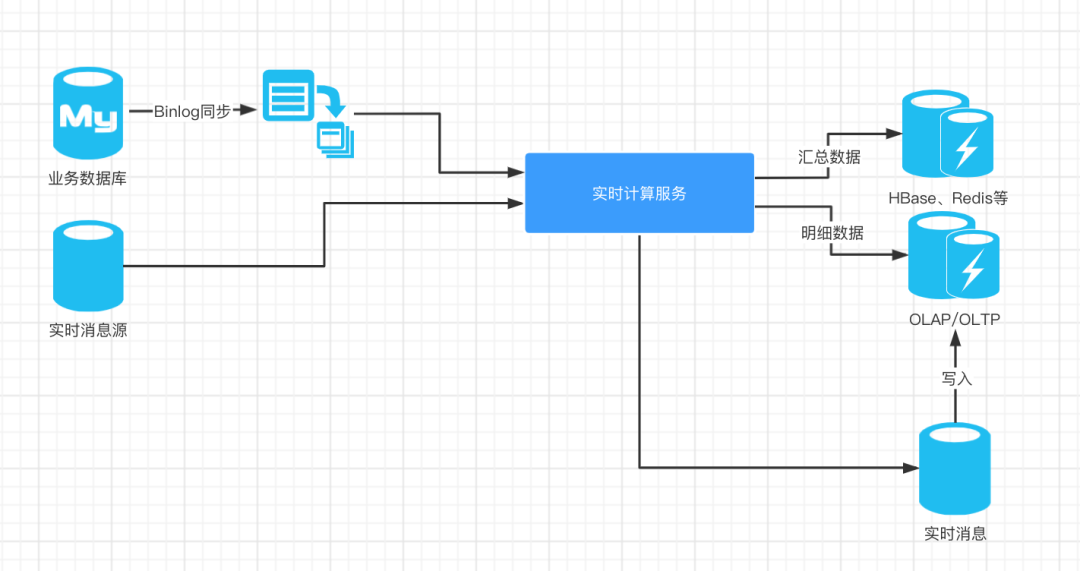

同步变异步
应用解耦
流量削峰
高吞吐:
可以满足每秒百万级别消息的生产和消费,并且可以通过横向扩展,保证数据处理能力可以得到线性扩展。
低延迟:
以时间复杂度为 O(1) 的方式提供消息持久化能力,即使对 TB 级以上数据也能保证常数时间复杂度的访问性能。
高容错:
Kafka 允许集群的节点出现失败。
可靠性:
消息可以根据策略进行磁盘的持久化,并且读写效率都很高。
生态丰富:
Kafka 周边生态极其丰富,与各个实时处理框架结合紧密。
强大的状态管理。
Flink 使用 State 存储中间状态和结果,并且有强大的容错能力;
非常丰富的 API。
Flink 提供了包含 DataSet API、DataStream API、Flink SQL 等等强大的API;
生态支持完善。
Flink 支持多种数据源(Kafka、MySQL等)和存储(HDFS、ES 等),并且和其他的大数据领域的框架结合完善;
批流一体。
Flink 已经在将流计算和批计算的 API 进行统一,并且支持直接写入 Hive。
高度汇总,高度汇总指标一般存储在 Redis、HBase 中供前端直接查询使用。
明细数据,在一些场景下,我们的运营和业务人员需要查询明细数据,有一些明细数据极其重要,比如双十一派送的包裹中会有一些丢失和破损。
实时消息,Flink 在计算完成后,有一个下游是发往消息系统,这里的作用主要是提供给其他业务复用;
另外,在一些情况下,我们计算好明细数据也需要再次经过消息系统才能落库,将原来直接落库拆成两步,方便我们进行问题定位和排查。
Hive、Hawq、Impala:
基于 SQL on Hadoop
Presto 和 Spark SQL 类似:
基于内存解析 SQL 生成执行计划
Kylin:
用空间换时间、预计算
Druid:
数据实时摄入加实时计算
ClickHouse:
OLAP 领域的 HBase,单表查询性能优势巨大
Greenpulm:
OLAP 领域的 PostgreSQL
Flink 实时数据仓库
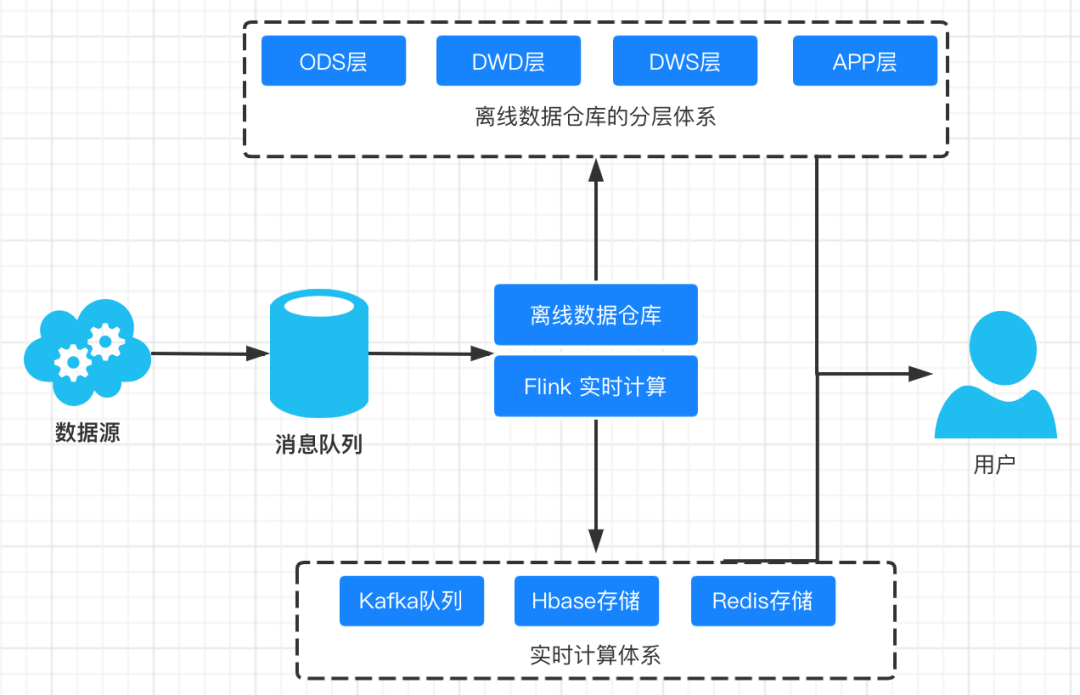
强一致性
自动故障转移和容错性
极高的读写 QPS,非常适合存储 K-V 形式的指标
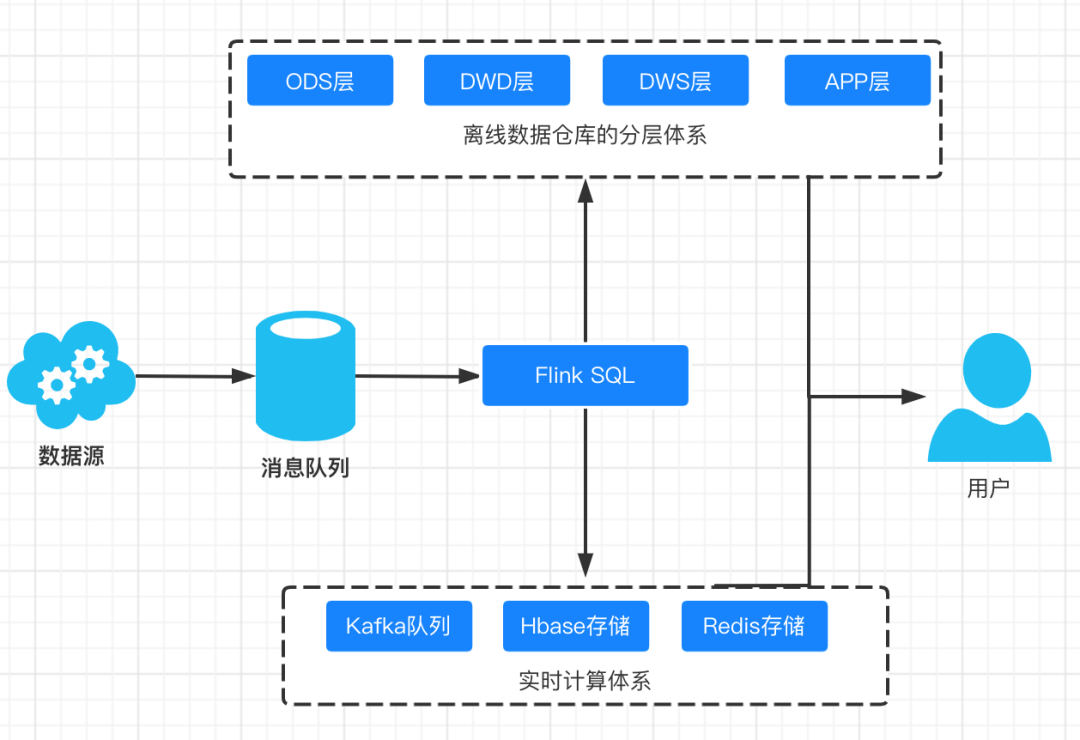
大厂的实时计算平台和实时数仓技术方案
作者的经验
数据源过多
数据源之间时间 GAP 巨大
离线数据和实时数据要求强一致性
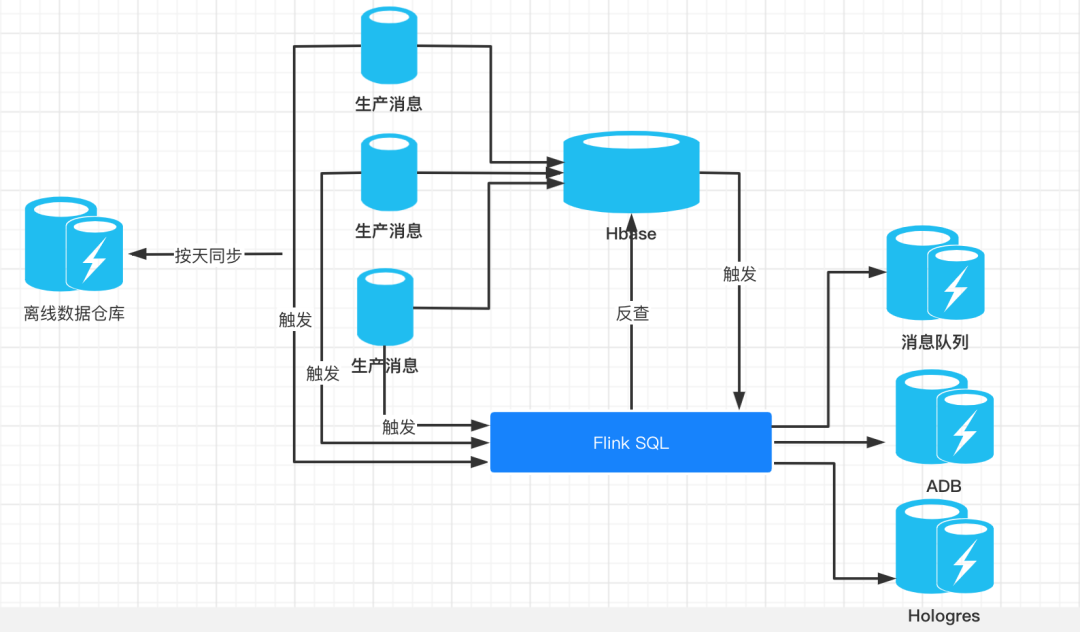
这套数据架构引入了 Hbase 作为中间存储,数据链路变长。导致运维成本大量增加,整个架构的实时性能受制于 Hbase 的变更信息能不能及时发送。
指标没有分层,会导致 ADB 和 Hologres 成为查询瓶颈。在这套数据架构中,我们完全抛弃了中间指标层,完全依赖 SQL 直接汇总查询。一方面得益于省略中间层后指标的准确性,另一方面因为 SQL 直接查询会对 ADB 有巨大的查询压力,使得 ADB 消耗了巨大的资源和成本。
腾讯看点的实时数据系统设计

数据采集层
实时数据仓库层
实时数据存储层
多核 CPU 并行计算
SIMD 并行计算加速
分布式水平扩展集群
稀疏索引、列式存储、数据压缩
聚合分析优化
过去 30 分钟内容的查询,99% 的请求耗时在1秒内
过去 24 小时内容的查询,90% 的请求耗时在5秒内,99% 的请求耗时在 10 秒内
阿里巴巴批流一体数据仓库建设
统一元数据管理
统一计算引擎
统一数据存储
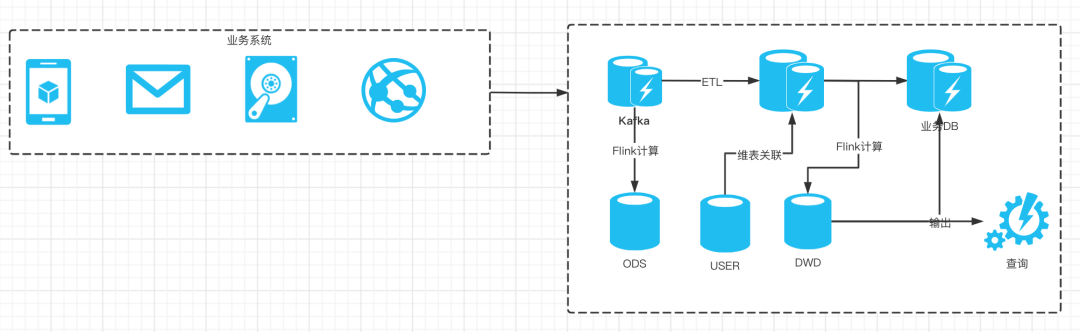
实战案例
架构设计
日志数据上报
日志数据清洗
实时计算程序
结果存储
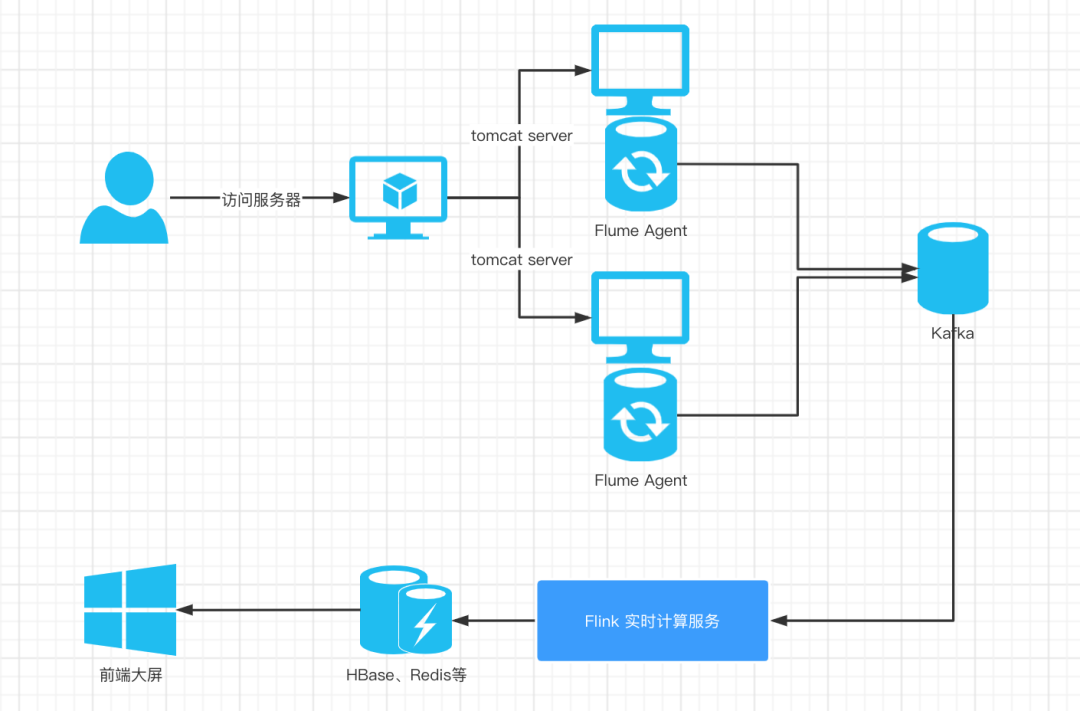
Flume 和 Kafka 整合和部署
Kafka 模拟数据生成和发送
Flink 和 Kafka 整合时间窗口设计
Flink 计算 PV、UV 代码实现
Flink 和 Redis 整合以及 Redis Sink 实现
Flume 和 Kafka 整合和部署
tar zxf apache-flume-1.8.0-bin.tar.gz
# 定义这个 agent 中各组件的名字a1.sources = r1a1.sinks = k1a1.channels = c1# source的配置,监听日志文件中的新增数据a1.sources.r1.type = execa1.sources.r1.command = tail -F /home/logs/access.log#sink配置,使用avro日志做数据的消费a1.sinks.k1.type = avroa1.sinks.k1.hostname = flumeagent03a1.sinks.k1.port = 9000#channel配置,使用文件做数据的临时缓存a1.channels.c1.type = filea1.channels.c1.checkpointDir = /home/temp/flume/checkpointa1.channels.c1.dataDirs = /home/temp/flume/data#描述和配置 source channel sink 之间的连接关系a1.sources.r1.channels = c1a1.sinks.k1.channel = c
$ flume-ng agent-c conf-n a1-f conf/log_kafka.conf >/dev/null 2>&1 &
定义这个 agent 中各组件的名字a1.sources = r1a1.sinks = k1a1.channels = c1#source配置a1.sources.r1.type = avroa1.sources.r1.bind = 0.0.0.0a1.sources.r1.port = 9000#sink配置a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSinka1.sinks.k1.topic = log_kafkaa1.sinks.k1.brokerList = 127.0.0.1:9092a1.sinks.k1.requiredAcks = 1a1.sinks.k1.batchSize = 20#channel配置a1.channels.c1.type = memorya1.channels.c1.capacity = 1000a1.channels.c1.transactionCapacity = 100#描述和配置 source channel sink 之间的连接关系a1.sources.r1.channels = c1a1.sinks.k1.channel = c1
$ flume-ng agent-c conf-n a1-f conf/flume_kafka.conf >/dev/null 2>&1 &
public class UserClick {private String userId;private Long timestamp;private String action;public String getUserId() {return userId;}public void setUserId(String userId) {this.userId = userId;}public Long getTimestamp() {return timestamp;}public void setTimestamp(Long timestamp) {this.timestamp = timestamp;}public String getAction() {return action;}public void setAction(String action) {this.action = action;}public UserClick(String userId, Long timestamp, String action) {this.userId = userId;this.timestamp = timestamp;this.action = action;}}enum UserAction{//点击CLICK("CLICK"),//购买PURCHASE("PURCHASE"),//其他OTHER("OTHER");private String action;UserAction(String action) {this.action = action;}}
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);// 检查点配置,如果要用到状态后端,那么必须配置env.setStateBackend(new MemoryStateBackend(true));Properties properties = new Properties();properties.setProperty("bootstrap.servers", "127.0.0.1:9092");properties.setProperty(FlinkKafkaConsumerBase.KEY_PARTITION_DISCOVERY_INTERVAL_MILLIS, "10");FlinkKafkaConsumer<String> consumer = new FlinkKafkaConsumer<>("log_user_action", new SimpleStringSchema(), properties);//设置从最早的offset消费consumer.setStartFromEarliest();DataStream<UserClick> dataStream = env.addSource(consumer).name("log_user_action").map(message -> {JSONObject record = JSON.parseObject(message);return new UserClick(record.getString("user_id"),record.getLong("timestamp"),record.getString("action"));}).returns(TypeInformation.of(UserClick.class));
SingleOutputStreamOperator<UserClick> userClickSingleOutputStreamOperator = dataStream.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<UserClick>(Time.seconds(30)) {@Overridepublic long extractTimestamp(UserClick element) {return element.getTimestamp();}});
dataStream.windowAll(TumblingProcessingTimeWindows.of(Time.days(1), Time.hours(-8))).trigger(ContinuousProcessingTimeTrigger.of(Time.seconds(20)))
userClickSingleOutputStreamOperator.keyBy(new KeySelector<UserClick, String>() {@Overridepublic String getKey(UserClick value) throws Exception {return DateUtil.timeStampToDate(value.getTimestamp());}}).window(TumblingProcessingTimeWindows.of(Time.days(1), Time.hours(-8))).trigger(ContinuousProcessingTimeTrigger.of(Time.seconds(20))).evictor(TimeEvictor.of(Time.seconds(0), true))...
public class DateUtil {public static String timeStampToDate(Long timestamp){ThreadLocal<SimpleDateFormat> threadLocal= ThreadLocal.withInitial(() -> new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"));String format = threadLocal.get().format(new Date(timestamp));return format.substring(0,10);}}
public class MyProcessWindowFunction extends ProcessWindowFunction<UserClick,Tuple3<String,String, Integer>,String,TimeWindow>{private transient MapState<String, String> uvState;private transient ValueState<Integer> pvState;public void open(Configuration parameters) throws Exception {super.open(parameters);uvState = this.getRuntimeContext().getMapState(new MapStateDescriptor<>("uv", String.class, String.class));pvState = this.getRuntimeContext().getState(new ValueStateDescriptor<Integer>("pv", Integer.class));}public void process(String s, Context context, Iterable<UserClick> elements, Collector<Tuple3<String, String, Integer>> out) throws Exception {Integer pv = 0;Iterator<UserClick> iterator = elements.iterator();while (iterator.hasNext()){pv = pv + 1;String userId = iterator.next().getUserId();uvState.put(userId,null);}pvState.update(pvState.value() + pv);Integer uv = 0;Iterator<String> uvIterator = uvState.keys().iterator();while (uvIterator.hasNext()){String next = uvIterator.next();uv = uv + 1;}Integer value = pvState.value();if(null == value){pvState.update(pv);}else {pvState.update(value + pv);}out.collect(Tuple3.of(s,"uv",uv));out.collect(Tuple3.of(s,"pv",pvState.value()));}}
userClickSingleOutputStreamOperator.keyBy(new KeySelector<UserClick, String>() {@Overridepublic String getKey(UserClick value) throws Exception {return value.getUserId();}}).window(TumblingProcessingTimeWindows.of(Time.days(1), Time.hours(-8))).trigger(ContinuousProcessingTimeTrigger.of(Time.seconds(20))).evictor(TimeEvictor.of(Time.seconds(0), true)).process(new MyProcessWindowFunction());
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-redis_2.11</artifactId><version>1.1.5</version></dependency>
public class MyRedisSink implements RedisMapper<Tuple3<String,String, Integer>>{/*** 设置redis数据类型*/public RedisCommandDescription getCommandDescription() {return new RedisCommandDescription(RedisCommand.HSET,"flink_pv_uv");}//指定keypublic String getKeyFromData(Tuple3<String, String, Integer> data) {return data.f1;}//指定valuepublic String getValueFromData(Tuple3<String, String, Integer> data) {return data.f2.toString();}}
...userClickSingleOutputStreamOperator.keyBy(new KeySelector<UserClick, String>() {@Overridepublic String getKey(UserClick value) throws Exception {return value.getUserId();}}).window(TumblingProcessingTimeWindows.of(Time.days(1), Time.hours(-8))).trigger(ContinuousProcessingTimeTrigger.of(Time.seconds(20))).evictor(TimeEvictor.of(Time.seconds(0), true)).process(new MyProcessWindowFunction()).addSink(new RedisSink<>(conf,new MyRedisSink()));...