Flink 在实时金融数据湖的应用
导读:本文由中原银行大数据平台研发工程师白学余分享,主要介绍实时金融数据湖在中原银行的应用。主要内容包括:
背景概况
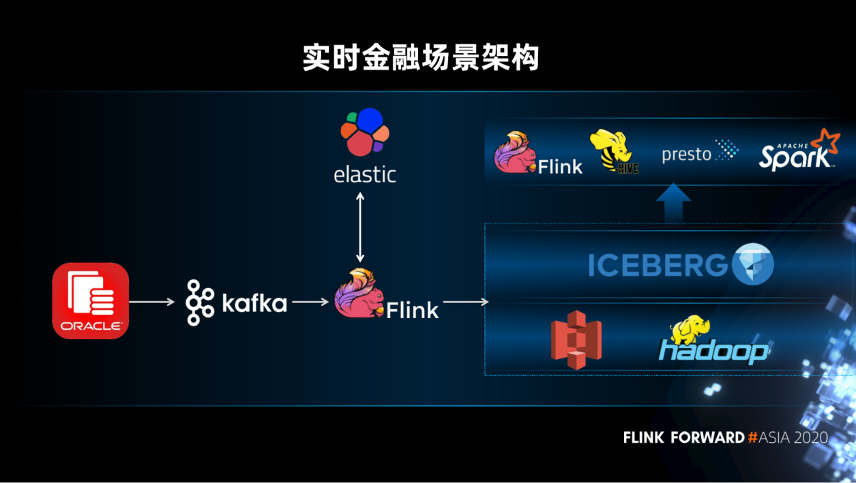
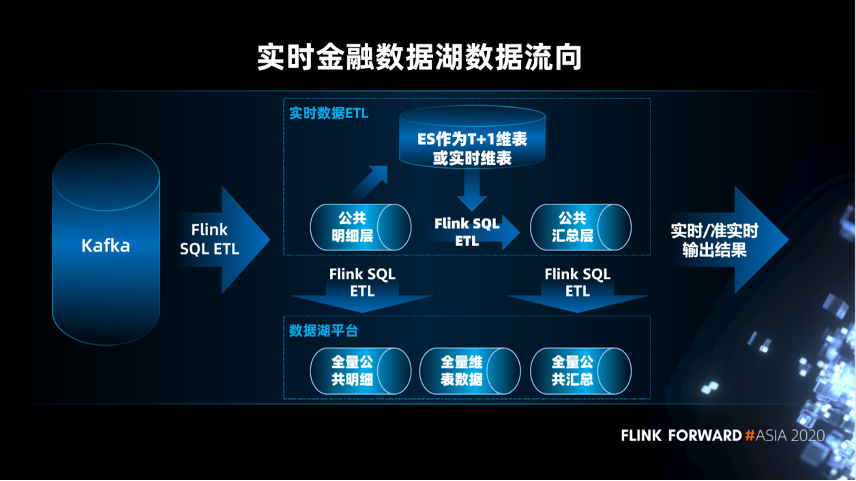
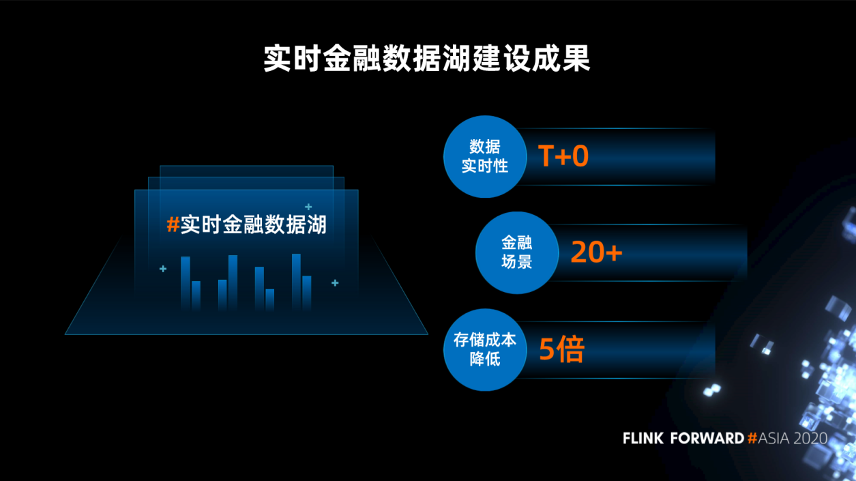
实时金融数据湖体系架构
场景实践


首先,传统的银行数据分析主要集中在银行的收入、成本、利润的分配和应对监管部门的监管。这些数据分析非常复杂,但也存在一定的规律,它属于财务数据分析。随着互联网金融的不断发展,银行的业务不断受到挤压,如果仍然将数据分析集中在收入、成本、分配及监管方面,已经不能满足业务的需求。如今,更好的了解客户,收集大量的数据,做更多有针对性的营销和决策分析是当务之急。因此,现在银行的业务分析决策由传统的财务分析逐步转向面向 KYC 的分析。
其次,传统的银行业务主要依靠业务人员进行决策以满足业务的发展需求。但是随着银行业务的不断发展,各种各样的应用产生大量的多类型数据。仅仅依靠业务人员去做决策,已无法满足业务的需求。当前面临的问题更加复杂,影响因素也日渐增多,需要用更全面、智能的技术方式来进行解决。因此,银行需要将传统的纯业务人员决策方式转变为越来越多依靠机器智能的决策方式。
■ 问题分析
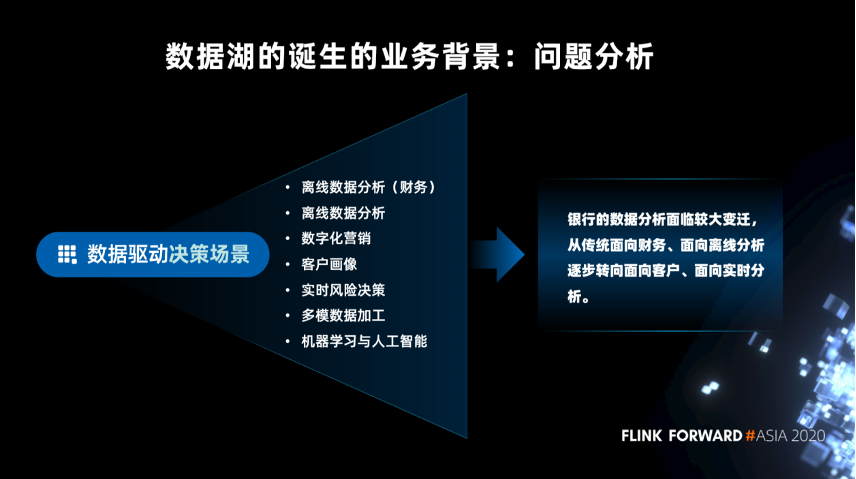
传统的面向财务分析离线数据分析
面向非财务的数据分析
面向事件或日志等频繁变更
实时性较高的数据分析
2. 数据湖诞生的技术背景

精准、规范
多层数据加工
口径统一
T+1 数据处理
具备较高的性能
经过长时间积累沉淀
适合财务分析
变更困难
单位存储成本较高
不适合海量日志、行为等变更频繁,实时性高的数据
半结构化数据和非结构化数据兼容差


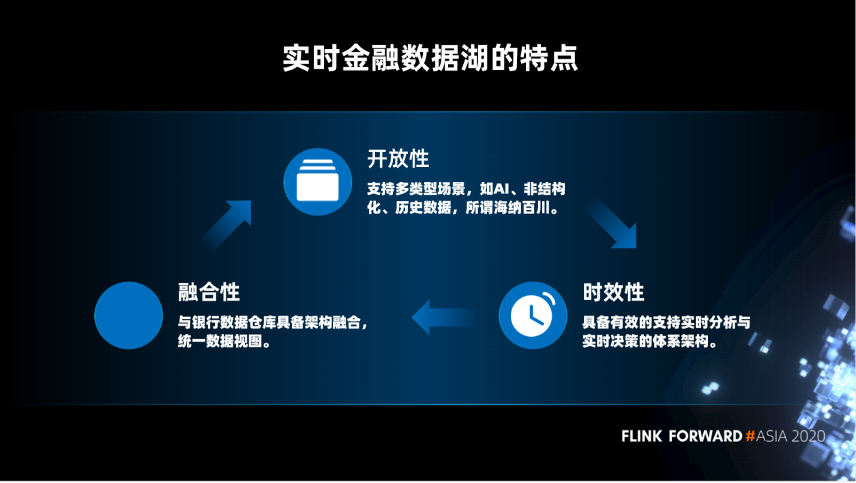
第一,开放性。支持多类型场景,如 AI、非结构化、历史数据,海纳百川。
第二,时效性。具备有效的支持实时分析与实时决策的体系架构。
第三,融合性。与银行数据仓库技术架构融合,统一数据视图。
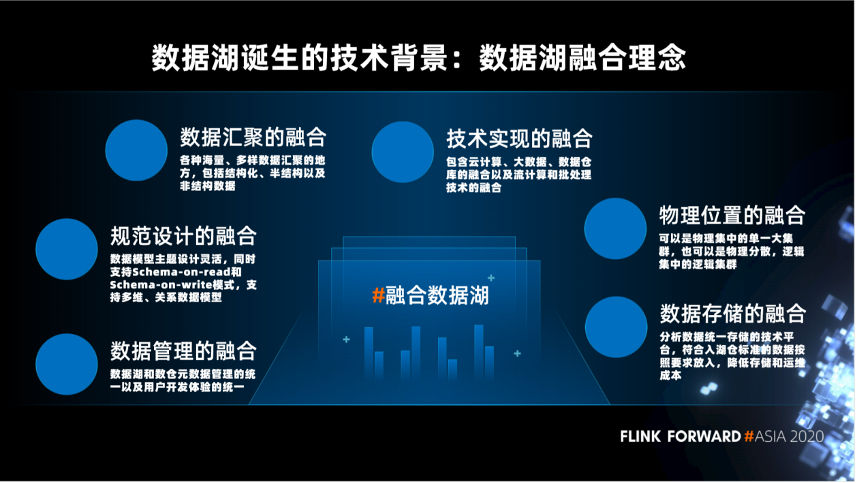
第一,数据汇聚的融合,各种海量、多样数据汇聚的地方,包括结构化、半结构以及非结构数据。
第二,技术实现的融合,包含云计算、大数据、数据仓库的融合以及流计算和批处理技术的融合。
第三,规范设计的融合,数据模型主题设计灵活,同时支持 Schema-on-read 和 Schema-on-write 模式,支持多维、关系数据模型。
第四,数据管理的融合,数据湖和数仓元数据管理的统一以及用户开发体验的统一。
第五,物理位置的融合,可以是物理集中的单一大集群,也可以是物理分散,逻辑集中的逻辑集群。
第六,数据存储的融合,分析数据统一存储的技术平台,符合入湖仓标准的数据按照要求放入,降低存储和运维成本。
体系架构
第一,数据源。不仅仅支持结构化数据,也支持半结构化数据和非结构化数据。
第二,统一数据接入。数据通过统一数据接入平台,按数据的不同类型进行智能的数据接入。
第三,数据存储。包括数据仓库和数据湖,实现冷热温智能数据分布。
第四,数据开发。包括任务开发,任务调度,监控运维,可视化编程。
第五,数据服务。包括交互式查询,数据 API,SQL 质量评估,元数据管理,血缘管理。
第六,数据应用。包括数字化营销,数字化风控,数据化运营,客户画像。

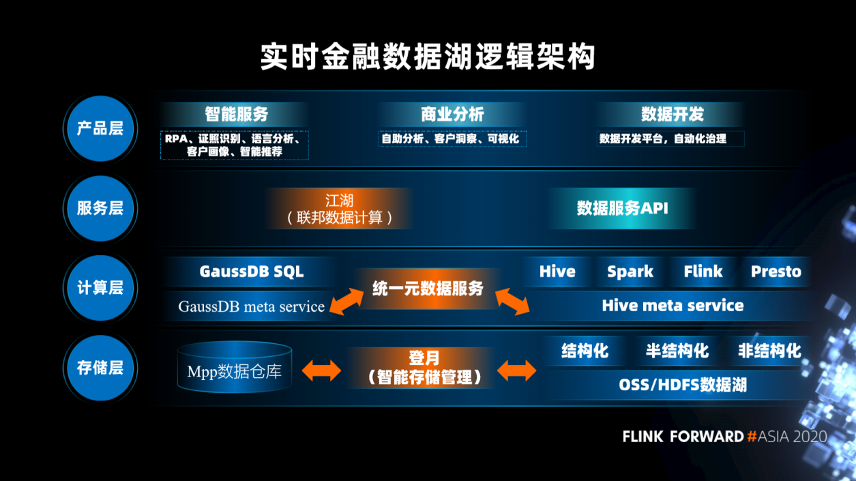
在存储层,有 MPP 数据仓库和基于 OSS/HDFS 的数据湖,可以实现智能存储管理。
在计算层,实现统一的元数据服务。
在服务层,有联邦数据计算和数据服务 API 两种方式。其中,联邦数据计算服务是一个联邦查询引擎,可以实现数据跨库查询,它依赖的就是统一元数据服务,查询的是数据仓库和数据湖中的数据。
在产品层,提供智能服务:包 RPA、证照识别、语言分析、客户画像、智能推荐。商业分析服务:包括自助分析、客户洞察、可视化。数据开发服务:包括数据开发平台,自动化治理。
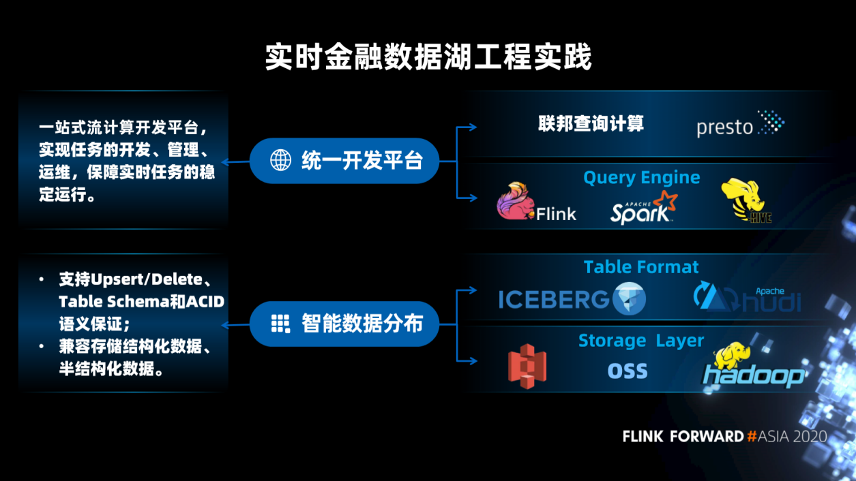
存储层和表结构层是数据智能分布的组成部分,支持 Upsert/Delete、Table Schema 和 ACID 的语义保证,并且它可以兼容存储半结构化数据和非结构化数据。
查询引擎层和联邦计算层是统一数据开发平台的一个组成部分。统一数据开发平台提供的是一站式的数据开发,可以实现实时数据任务的开发和离线数据任务的开发。
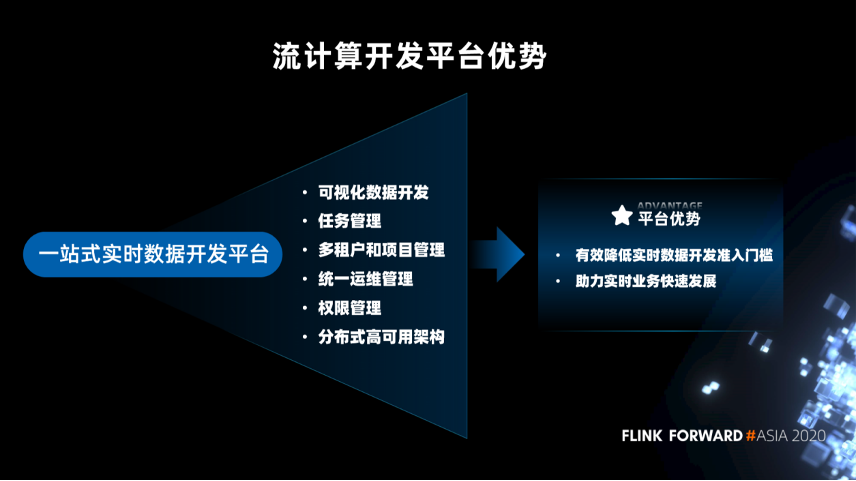

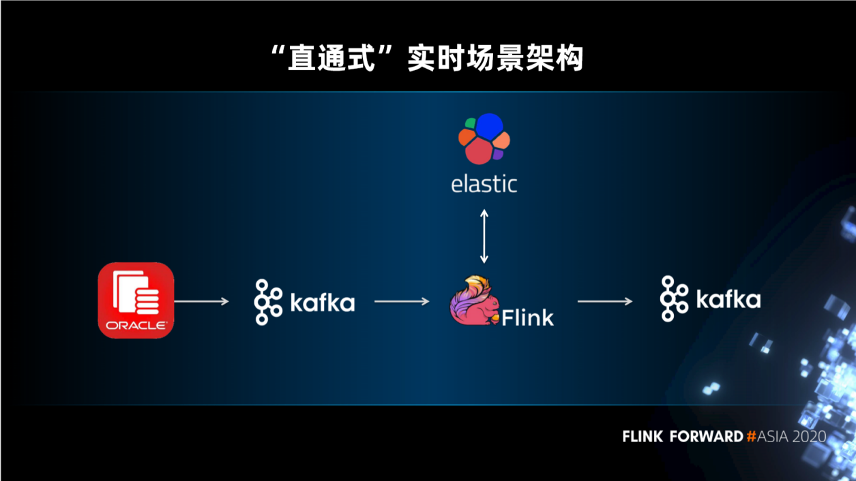
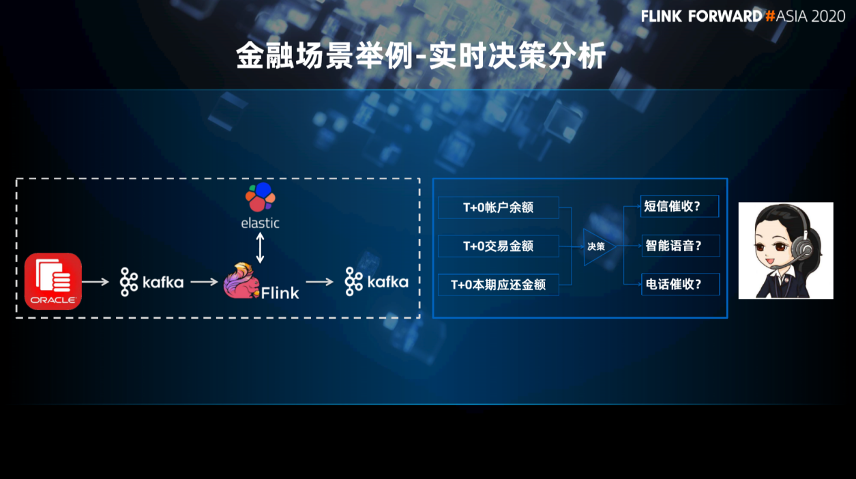
实时决策分析
实时 BI 分析


业务逻辑简单,Flink 实时读取 Kafka 中的事件数据和 Elastic 中的维表数据进行处理,处理的结果会直接发送给业务。
业务逻辑复杂,会进行分步处理,将中间结果先写到数据湖,再进行逐步的处理,得到最终的结果。然后最终的结果会通过查询引擎对接不同的应用。