
Flink 实践 | 贝壳基于 Flink 的实时计算演进之路
发展历程
平台建设
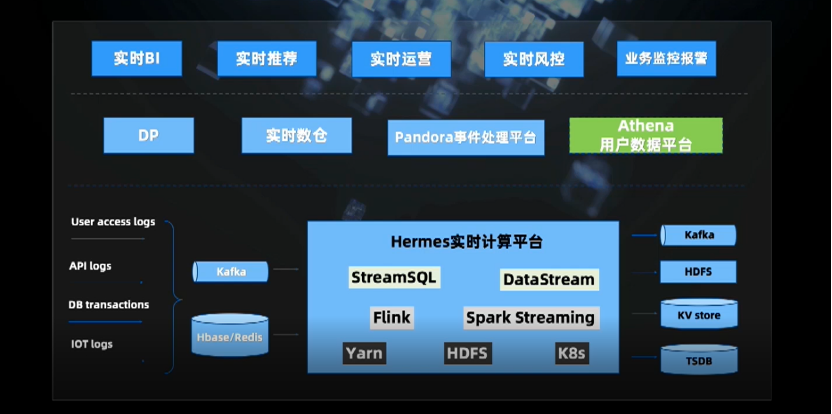
实时数仓及其应用场景
事件驱动场景
未来规划
 GitHub 地址
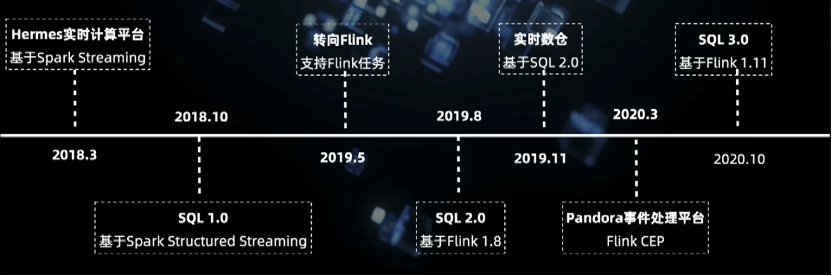
GitHub 地址 一、发展历程

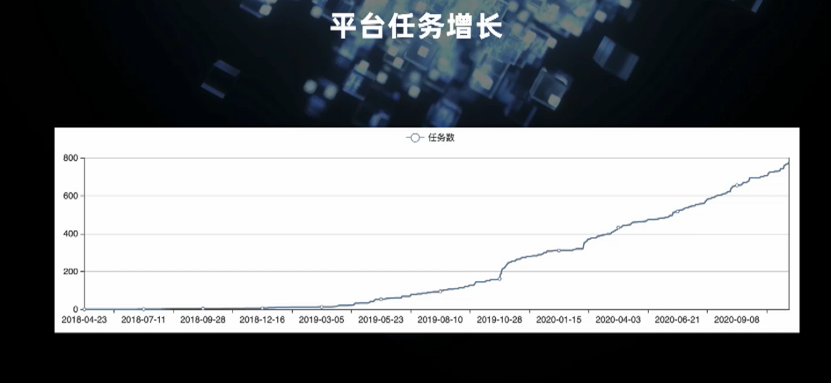
二、平台建设

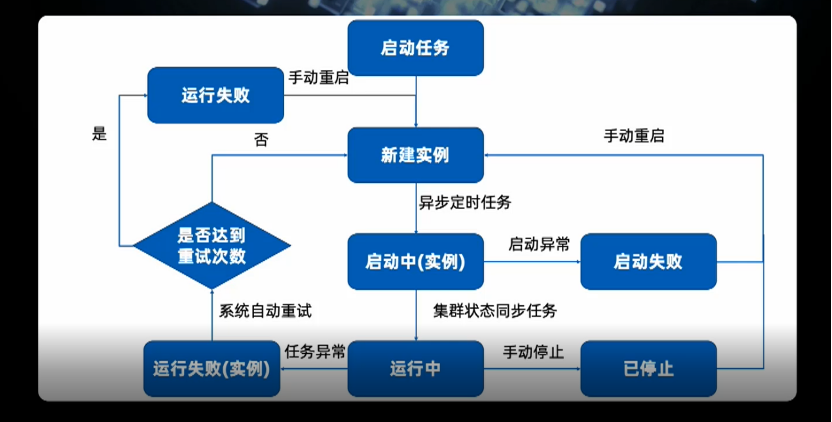
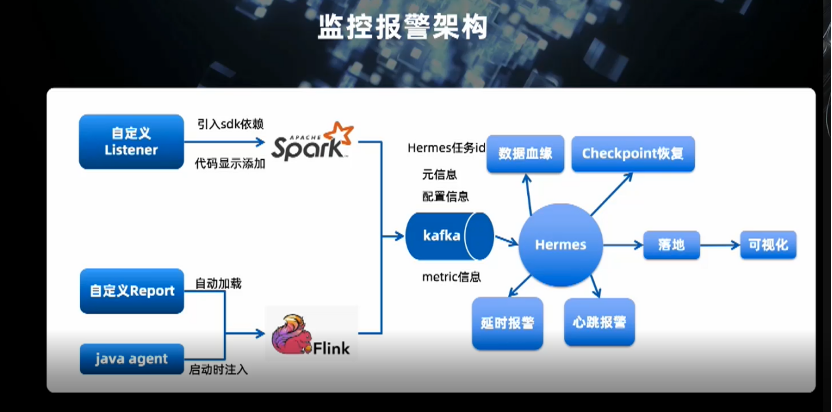
支持任务托管的基本能力,包括任务的编辑发布、版本管理、监控报警等;
支持多种语言的实时任务,包括对贝壳算法相关的 Python 实时任务的良好支持;
根据业务场景不同,支持多种业务类型,如自定义任务、模板任务及场景任务(SQL 任务),内部通用配置化任务,如分流合并操作。目前 SQL 任务在平台占比较高,我们的目标是 80%;
支持公共队列(针对较数据量小的需求),对于数据量大的需求,要有稳定的资源保证,我们可以提供专有队列,运行更为可靠。

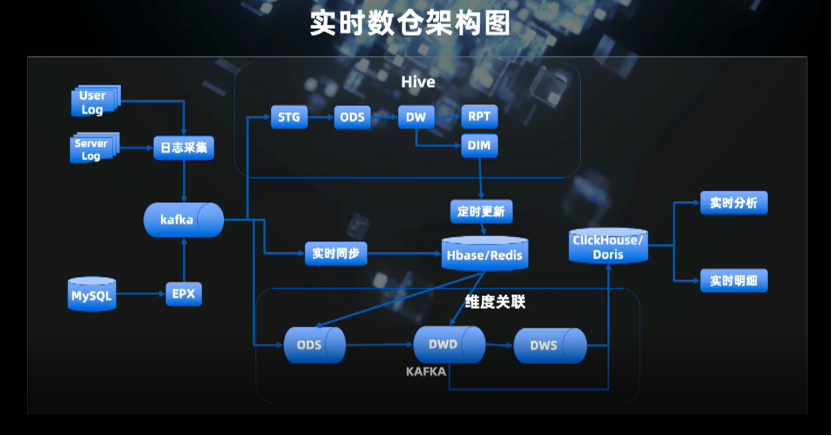
三、实时数仓
在实时侧,分层越少越好,否则中间环节越多,出问题的概率越大;
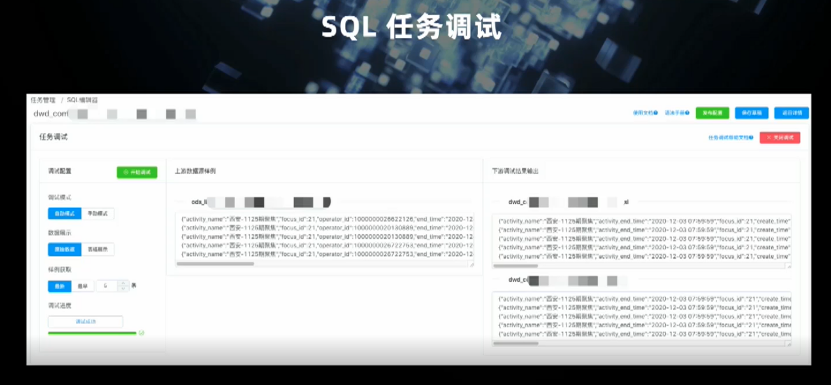
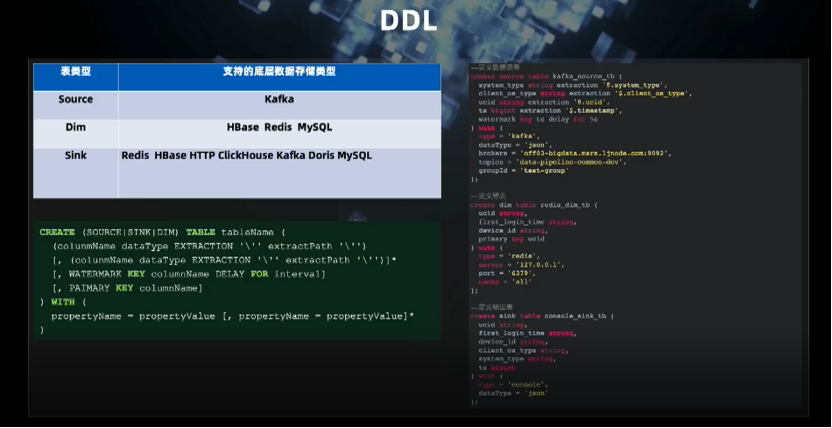
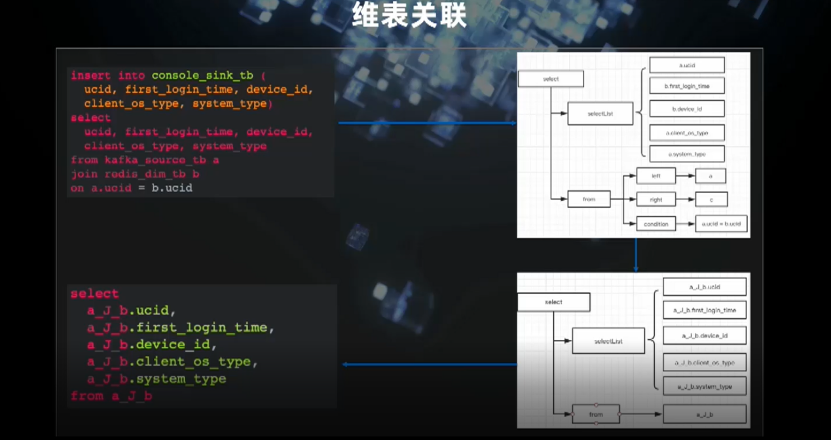
在 SQL 层面,支持标准的SQL语法,维表关联,提供图形化的SQL开发环境。另外还支持丰富的内置函数,并逐步完善支持用户自定义函数(UDF)的开发;
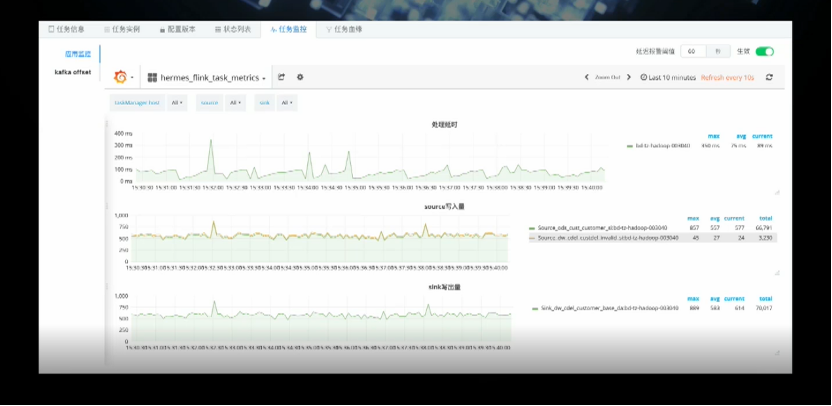
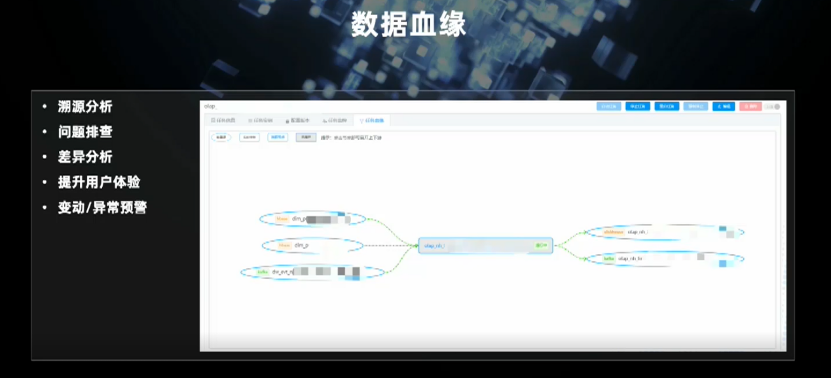
数据血缘方面,平台支持图形化展示和完善的链路分析,而且能实时看到数据流的运行情况并对异常进行标示;
最后是多源支持,对公司内部用到的各种存储做到了较好的支持。
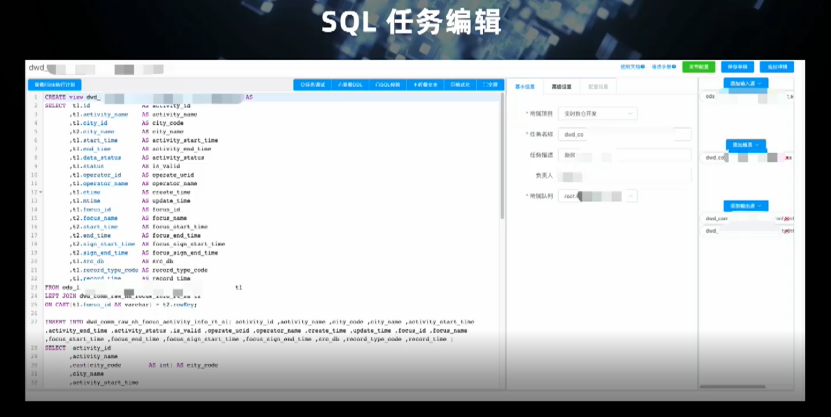
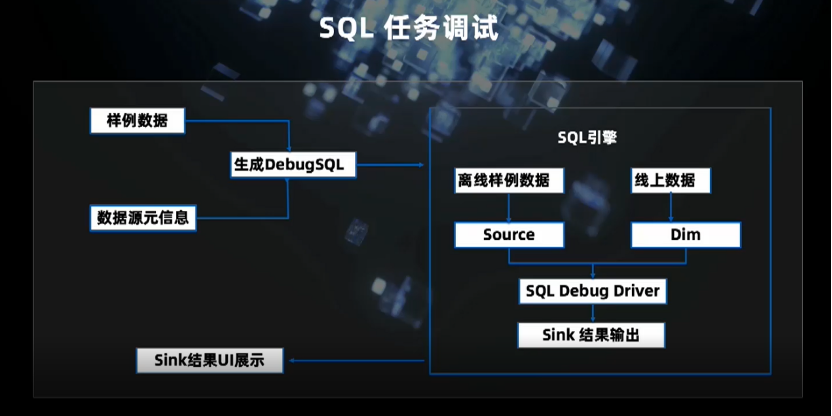
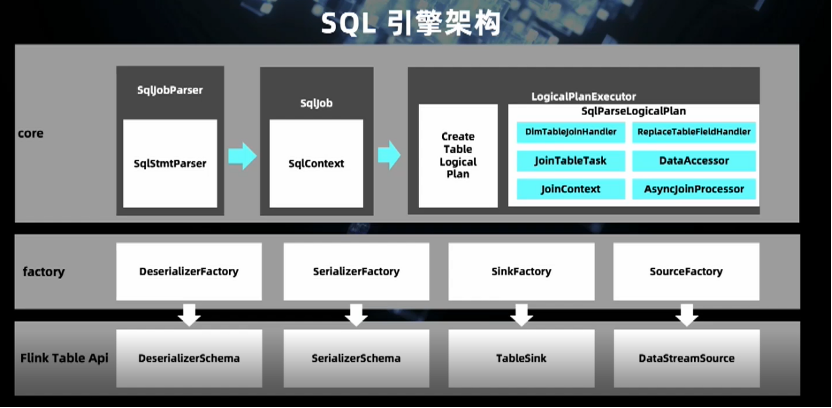
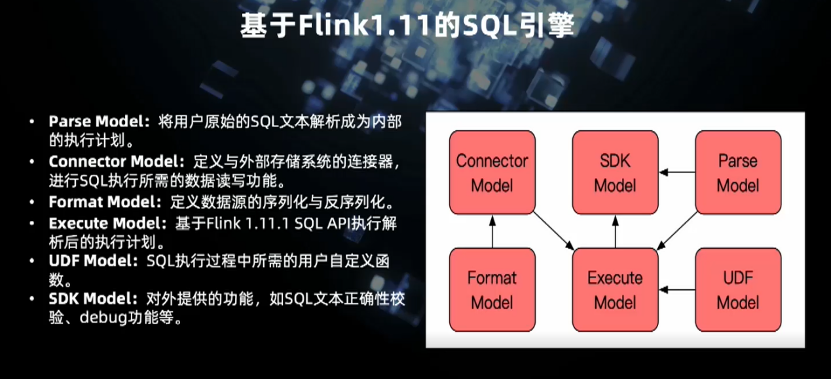
解析模块(Parse Model)将用户原始的 SQL 解析成内部的执行计划,完全依赖于 Flink SQL。Connector Model 完成目前 Flink 尚未支持的 Connector 开发。
Format Model 实现数据源字段的序列化和反序列化。
执行模块(Execute Model)基于 Flink1.11 SQL API 执行解析后的执行计划。
UDF 模块是专门处理 UDF 的解析,如参数调用的合法验证、权限验证、细致的数据权限限制。
SDK Model 是对外提供的标准化服务,如 SQL 文本开发的验证,debug 功能等。
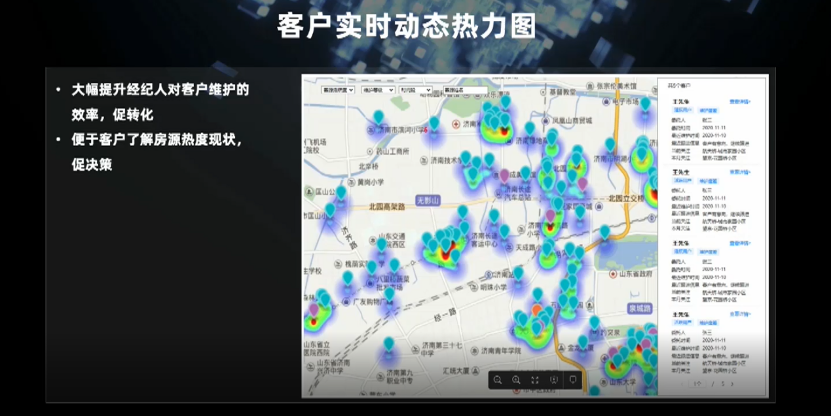
四、事件驱动
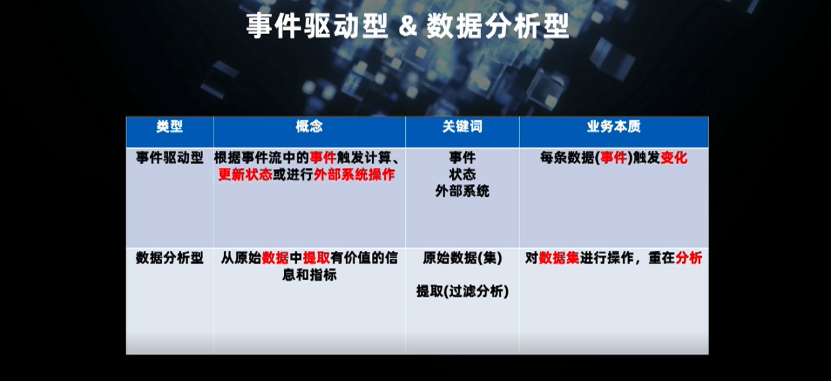
事件驱动是根据事件流中的事件实时触发外部计算和外部状态的更新,主要关注实时事件触发的外部变化,重在单独事件以及外部动作的触发。
数据分析型主要是从原始数据中提取有价值的信息,重在分析。

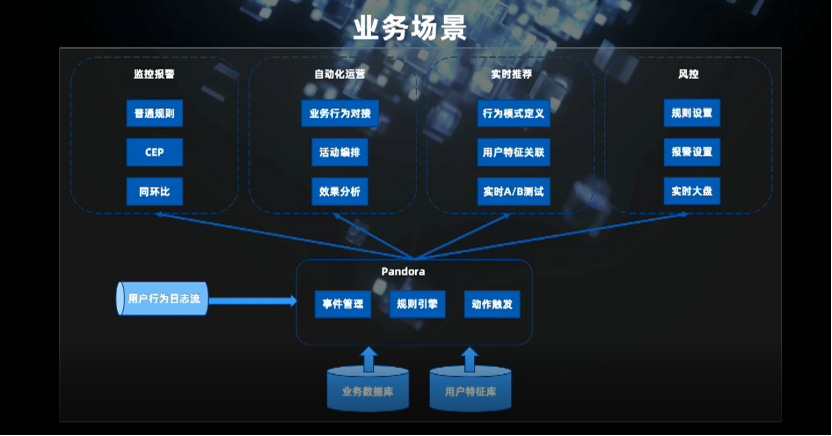
一是用户行为事件缺乏统一的抽象和管理,开发效率低,周期长,各部门存在重复建设;
二是规则逻辑与业务系统是耦合的,难以实现灵活的变化,对于复杂的规则或场景,业务方缺乏相关的技能和知识储备,如对 CEP 的支持;
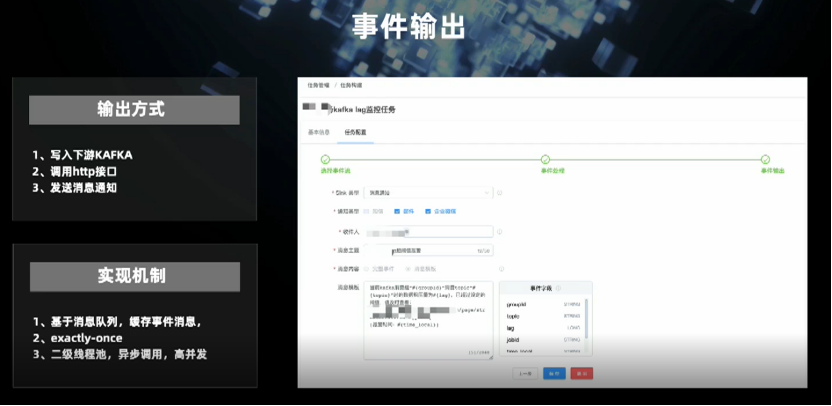
第三是缺乏统一的下游动作触发的配置。
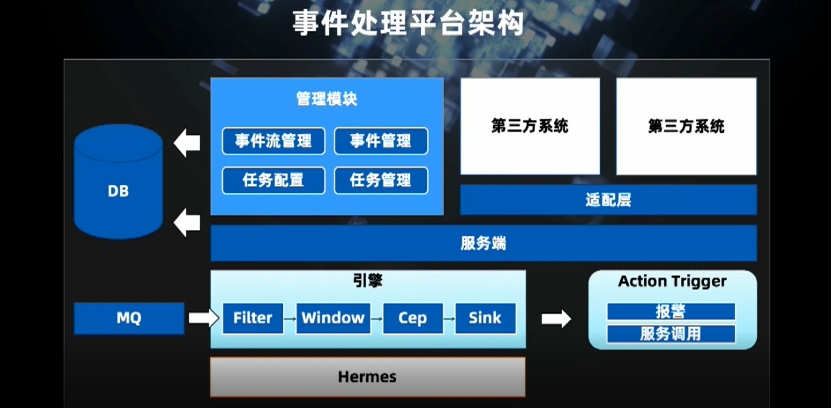
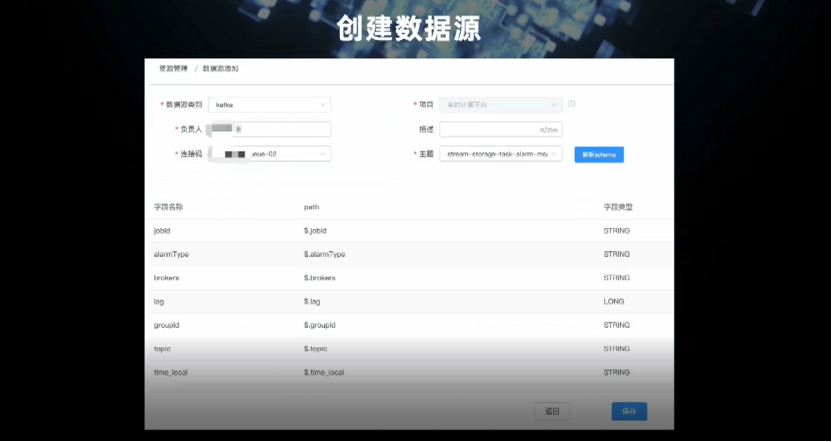
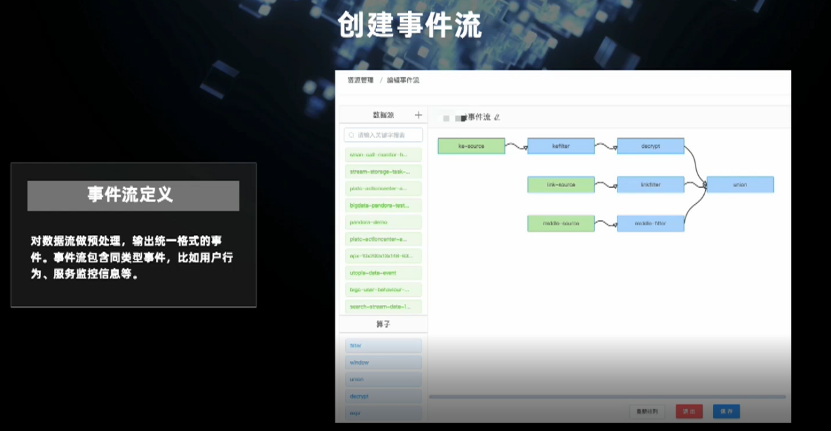
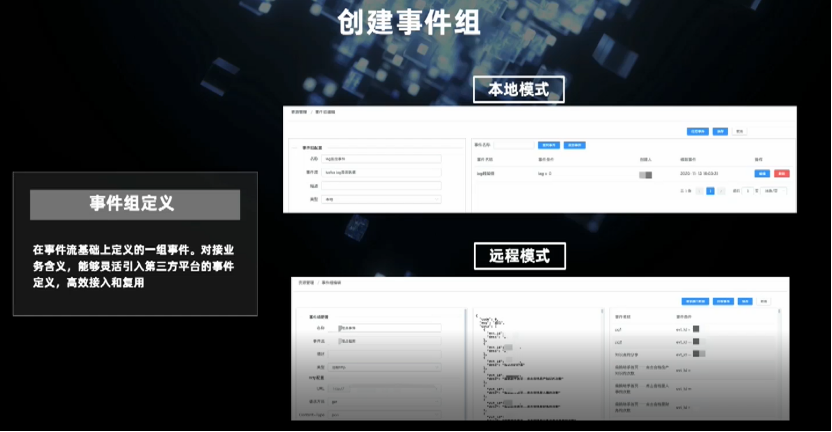
一是本地方式,即可以根据事件的各个字段和维度设定条件;
二是远程方式,这与我们的埋点系统(用户行为日志)直接连通,可以直接得到用户事件的定义。
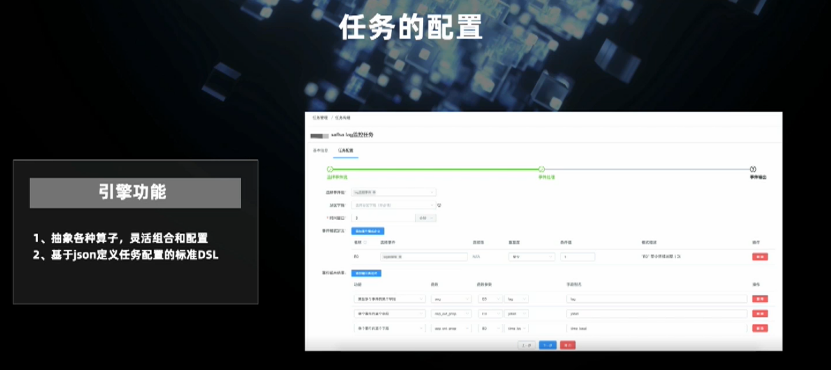
五、未来规划
更多 Flink 相关技术交流,可扫码加入社区钉钉大群~
 戳我,回顾作者分享视频!
戳我,回顾作者分享视频!