
实战 | flink sql 与微博热搜的碰撞!!!
1.序篇
通过本文你可以 get 到:
背景篇 定义篇-属于哪类特点的指标 数据应用篇-预期效果是怎样的 难点剖析篇-此类指标建设、保障的难点 数据建设篇-具体实现方案详述 数据服务篇-数据服务选型 数据保障篇-数据时效监控以及保障方案 效果篇-上述方案最终的效果 现状以及展望篇
2.背景篇
根据微博目前站内词条消费情况,计算 top 50 消费热度词条,每分钟更新一次,并且按照列表展现给用户。
3.定义篇-属于哪类特点的指标
这类指标可以统一划分到 topN 类别的指标中。即输入是具体词条消费日志,输出是词条消费排行榜。
4.数据应用篇-预期效果是怎样的
预期效果如下。
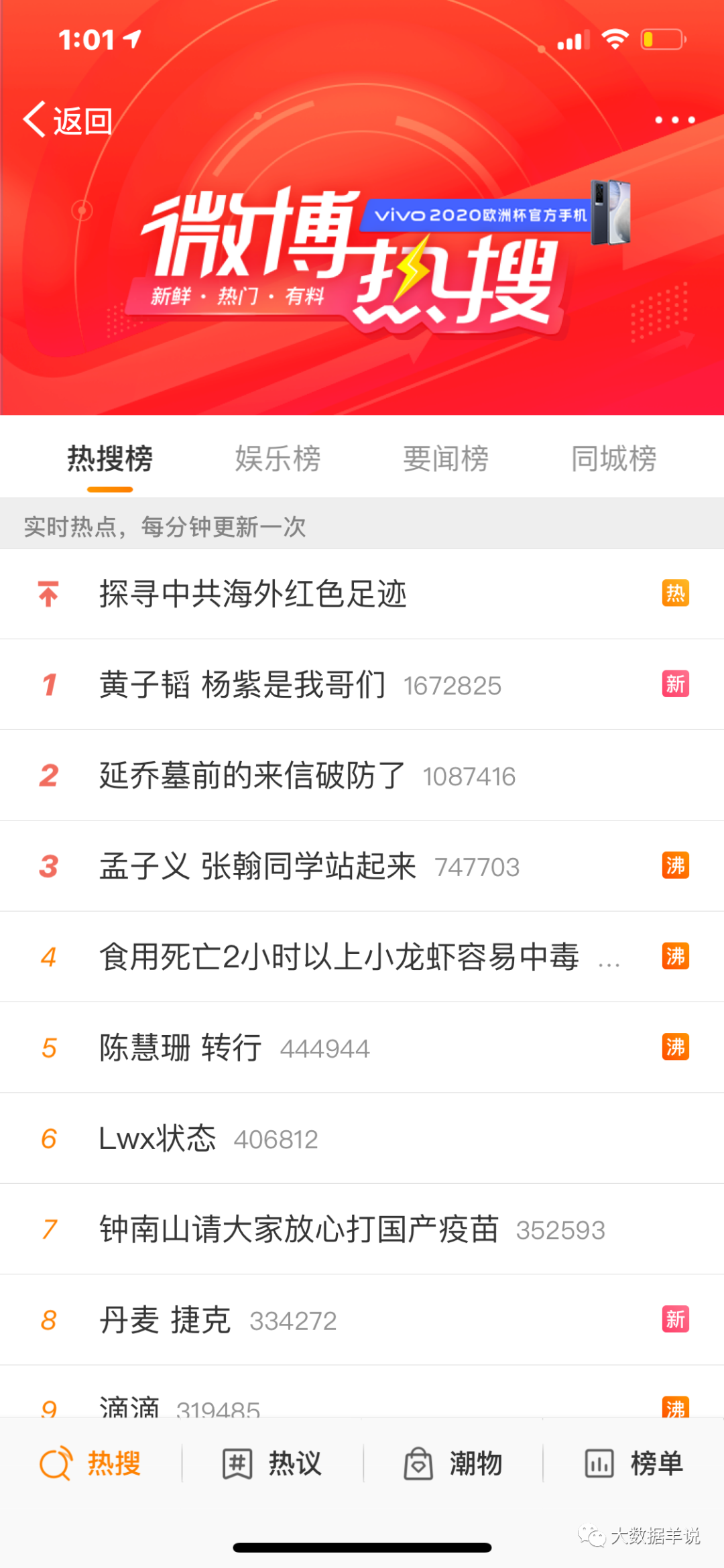
5.难点剖析篇-此类指标建设、保障的难点
5.1.数据建设
5.1.1.难点
榜单类的指标有一个特点,就是客户端获取到的数据必须是同一分钟当时的词条消费热度,这就要求我们产出的每一条数据需要包含 topN 中的所有数据。这样才能保障用户获取到的数据的一致性。 flink 任务大状态:词条多,状态大;词条具有时效性,所以对于低热词条需要进行删除 flink 任务大流量、高性能:数据源是全站的词条消费流量,得扛得住突发流量的暴揍
5.1.2.业界方案调研
5.1.2.1.Flink DataStream api 实时计算 topN 热榜
Flink DataStream api 实时计算topN热榜[1]
优点:可以按照用户自定义逻辑计算排名,基于 watermark 推动整个任务的计算,具备数据可回溯性。 缺点:开发成本高,而本期主要介绍 flink sql 的方案,这个方案可以供大家进行参考。 「结论:虽可实现,但并非 sql api 实现。」
5.1.2.2.Flink SQL api 实时计算 topN 热榜
Flink SQL TopN语句[2]
Flink SQL 功能解密系列 —— 流式 TopN 挑战与实现[3]
优点:用户理解、开发成本低 缺点:只有排名发生变化的词条才会输出,排名未发生变化数据不会输出(后续会在「数据建设」模块进行解释),不能做到每一条数据包含目前 topN 的所有数据的需求。 「结论:不满足需求。」
5.1.2.3.结论
我们需要制定自己的 flink sql 解决方案,以实现上述需求。这也是本节重点要讲述的内容,即在「数据建设篇-具体实现方案详述」详细展开。
5.2.数据保障
5.2.1.难点
flink 任务高可用 榜单数据可回溯性
5.2.2.业界方案调研
flink 任务高可用:宕机之后快速恢复;有异地多活热备链路可随时切换 榜单数据可回溯性:任务失败之后,按照词条时间数据的进行回溯
5.3.数据服务保障
5.3.1.难点
数据服务引擎高可用 数据服务 server 高可用
5.3.2.业界方案调研
数据服务引擎高可用:数据服务引擎本身的高可用,异地双活实现 数据服务 server 高可用:异地双活实现;上游不更新数据,数据服务 server 模块也能查询出上一次的结果进行展示,至少不会什么数据都展示不了
6.数据建设篇-具体实现方案详述
6.1.整体数据服务架构
首先,我们最初的方案是如下图所示,单机房的服务端,但是很明显基本没有高可用保障。我们本文主要介绍 flink sql 方案,所以下文先介绍 flink sql,后文 6.6 介绍各种高可用、高性能优化及保障。
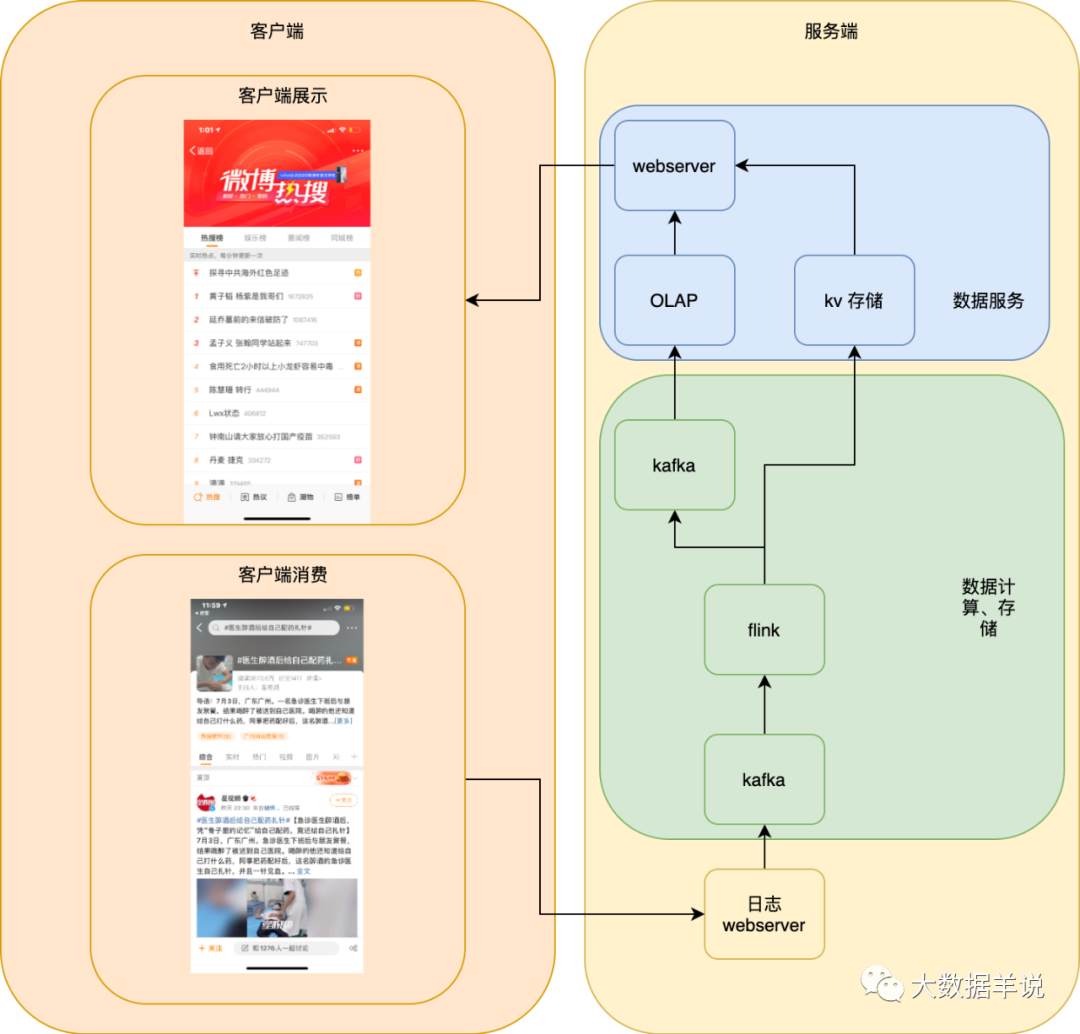
6.2.flink 方案设计
从本节开始,正式介绍 flink sql 相关的方案设计。
我们会从以下三个角度去介绍:
数据源:了解数据源的 schema 数据汇:从数据应用角度出发设计数据汇的 schema 数据建设:从数据源、数据汇从而推导出我们要实现的 flink sql 方案
6.3.数据源
数据源即安装在各位的手机微博客户端上报的用户消费明细日志,即用户消费一次某个词条,就会上报一条对应的日志。
6.3.1.schema
| 字段名 | 备注 |
|---|---|
| user_id | 消费词条的用户 |
| 热搜词条_name | 消费词条名称 |
| timestamp | 消费词条时间戳 |
| ... | ... |
6.4 数据汇
6.4.1.schema
最开始设计的 schema 如下:
| 字段名 | 字段类型 | 备注 |
|---|---|---|
| timestamp | bigint | 当前分钟词条时间戳 |
| 热搜词条_name | string | 词条名 |
| rn | bigint | 排名 1 - 50 |
但是排名展示时,需要将这一分钟的前 50 名的数据全部查询到展示。而 flink 任务输出排名数据到外部存储时,保障前 50 名的词条数据事务性的输出(要么同时输出到数据服务中,要么一条也不输出)是一件比较复杂事情。所以我们索性将前 50 名的数据全部收集到同一条数据当中,时间戳最新的一条数据就是最新的结果数据。
重新设计的 schema 如下:
| 字段名 | 字段类型 | 备注 |
|---|---|---|
| timestamp | bigint | 当前分钟词条时间戳 |
| 热搜榜单 | string | 热搜榜单,schema 如 {"排名第一的词条1" : "排名第一的词条消费量", "排名第二的词条1" : "排名第二的词条消费量", "排名第三的词条1" : "排名第三的词条消费量"...} 前 50 名 |
6.5.数据建设
6.5.1.方案1 - 内层 rownum + 外层自定义 udf
从排名的角度出发,自然可以想到 「rownum」 进行排名(阿里云也有对应的实现案例) 最终要把排行榜合并到一条数据进行输出,那就必然会涉及到「自定义 udf」 将排名数据进行合并
6.5.1.1.sql
INSERT INTO
target_db.target_table
SELECT
max(timestamp) AS timestamp,
热搜_top50_json(热搜词条_name, cnt) AS data -- 外层 udaf 将所有数据进行 merge
FROM
(
SELECT
热搜词条_name,
cnt,
timestamp,
row_number() over(
PARTITION by
热搜词条_name
ORDER BY
cnt ASC
) AS rn -- 内层 rownum 进行排名
FROM
(
SELECT
热搜词条_name,
count(1) AS cnt,
max(timestamp) AS timestamp
FROM
source_db.source_table
GROUP BY
热搜词条_name
-- 如果有热点词条导致数据倾斜,可以加一层打散层
)
)
WHERE
rn <= 100
GROUP BY
0;
6.5.1.2.udf
udaf 开发参考:https://www.alibabacloud.com/help/zh/doc-detail/69553.htm?spm=a2c63.o282931.b99.244.4ad11889wWZiHL
top50_udaf:作用是将已经经过上游处理的消费量排前 100 名词条拿到进行排序后,合并成一个 top50 排行榜 json 字符串产出。
Accumulator:由需求可以知道,当前 udaf 是为了计算前 50 名的消费词条,所以 Accumulator 应该存储截止当前时间按照消费 cnt 数排名的前 100 名的词条。我们由此就可以想到使用 「最小堆」 来当做 Accumulator,Accumulator 中只存储消费 cnt 前 100 的数据。
最小堆的实现:https://blog.csdn.net/jiutianhe/article/details/41441881
topN 设计伪代码如下:
public class 热搜_top50_json extends AggregateFunction<Map<String, Long>, TopN<Pair<String, Long>>> {
@Override
public TopN<Pair<String, Long>> createAccumulator() {
// 创建 acc -> 最小堆实现的 Top 50
}
@Override
public String getValue(TopN<Pair<String, Long>> acc) {
// 1.将最小堆 acc 中列表数据拿到
// 2.然后将列表按照从大到小进行排序
// 3.产出结果数据
}
public void accumulate(TopN<Pair<String, Long>> acc, String 词条名称, long cnt) {
// 1.获取到当前最小堆中的最小值
// 如果当前词条的消费量 cnt 小于最小堆的堆顶
// 则直接进行过滤
// 2.如果最小堆中不存在当前词条
// 则直接将当前词条放入最小堆中
// 3.如果最小堆中已经存在当前词条存在
// 那么将最小堆中这个词条的消费 cnt 与
// 当前词条的 cnt 作比较,将大的那个放入最小堆中
}
public void retract(TopN<Pair<String, Long>> acc, String id, long cnt) {
// 不需要实现 retract 方法
// 由于 topn 具有特殊性:即我们只取每一个词条的最大值
// 进行排名,所以可以不需要实现 retract 方法
// 比较排名都在 accumulate 方法中已经实现完成
}
}
❝Notes:
❞
上述 udf 最好设计成一个固定大小排行榜的 udf,比如一个 udf 实现类就只能用于处理一个固定大小的排行,防止用户进行】、
误用;sql 内层计算的排行榜大小一定要比 sql 外层(聚合)排行榜大小大。举反例:假如内层计算前 30 名,外层计算前 50 名,内层 A 分桶第 31 名可能比 B 分桶第 1 名的值还大,但是 A 桶的第 31 名就不会被输出。反之则正确。
6.5.1.3.flink-conf.yaml 参数配置
由于上述 sql 是在无限流上的操作,所以上游数据每更新一次都会向下游发送一次 retract 消息以及最新的数据的消息进行计算。
那么就会存在这样一个问题,即 source qps 为 x 时,任务内的吞吐就为 x * n 倍,sink qps 也为 x,这会导致性能大幅下降的同时也会导致输出结果数据量非常大。
而我们只需要每分钟更新一次结果即可,所以可以使用 flink sql 自带的 minibatch 参数来控制输出结果的频次。
minibatch 具体参考可参考下面两篇文章:
https://www.alibabacloud.com/help/zh/doc-detail/182012.htm?spm=a2c63.p38356.b99.288.698a785cSiDhEG https://www.jianshu.com/p/aa2e94628e24
table.exec.mini-batch.enabled : true
-- minibatch 是下面两个任意一个符合条件就会起触发计算
-- 60s 一次
table.exec.mini-batch.allow-latency : 60 s
-- 数量达到 10000000000 触发一次
-- 设置为 10000000000 是为了让上面的 allow-latency 触发,每 60s 输出一次来满足我们的需求
table.exec.mini-batch.size : 10000000000
状态过期,如果不设置的话,词条状态会越来越大,对非高热词条进行清除。
http://apache-flink.147419.n8.nabble.com/Flink-sql-state-ttl-td10158.html
-- 设置 1 天的 ttl,如果一天过后
-- 这个词条还没有更新,则直接删除
table.exec.state.ttl : 86400 s
6.5.2.方案2 - 自定义 udf
「自定义排名 udf」
6.5.2.1.sql
INSERT INTO target_db.target_table
SELECT
max(timestamp) AS timestamp,
-- udf 计算每一个分桶的前 100 名列表
热搜_top50_json(cast(热搜词条_name AS string), cnt) AS bucket_top100
FROM
(
SELECT
热搜词条_name AS 热搜词条_name,
count(1) AS cnt,
max(timestamp) AS timestamp
FROM
source_db.source_table
GROUP BY
热搜词条_name
-- 如果有热点词条导致数据倾斜
-- 可以加一层打散层
)
GROUP BY
0
-- 由于这里是 group by 0
-- 所以可能会到导致热点,所以如果需要也可以加一层打散层
-- 在内部先算 top50,在外层将内部分桶的 top50 榜单进行 merge
6.5.2.2.udf
此 udf 与 方案1 的 udf(见 6.5.1.2.udf) 完全相同。
6.5.2.3.flink-conf.yaml 参数配置
参数同 6.5.1.3 flink-conf.yaml 参数配置
6.6.高可用、高性能
6.6.1.整体高可用保障
异地双链路热备如下图:
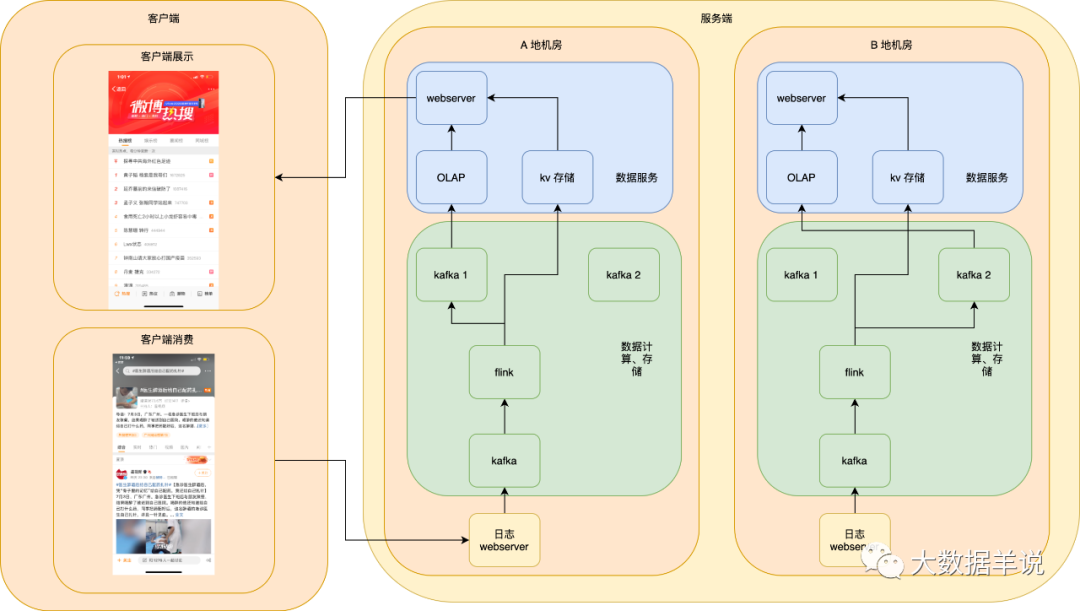
可能会发现图中有异地机房,但是我们目前只画出了 A 地区机房的数据链路,B 地区机房还没有画全,接着我们一步一步将这个图进行补全。
❝「Notes:」
「异地双机房只是双链路的热备的一种案例。如果有同城双机房、双集群也可进行同样的服务部署。」
「为什么说异地机房的保障能力 > 同城异地机房 > 同城同机房双集群容灾能力?」
「同城同机房:只要这个机房挂了,即使你有两套链路也没救。」「同城异地机房:很小几率情况会同城异地两个机房都挂了。。」「异地机房:几乎不可能同时异地两个机房都被炸了。。。」
❞
6.6.1.1.数据源日志高可用
数据源日志 server 服务高可用:异地机房,当一个机房挂了之后,在客户端可以自动将日志发送到另一个机房的 webserver 数据源日志 kafka 服务高可用:kafka 使用异地机房 topic,其实就是两个 topic,每个机房一个 topic,两个 topic 互为热备,producer 在向下游两个机房的 topic 写数据时,可以将 50% 的流量写入一个机房,另外 50% 的流量写入另一个机房,一旦一个机房的 kafka 集群宕机,则 producer 端可以自动将 100% 的流量切换到另一个机房的 kafka。
正常情况下如图所示:
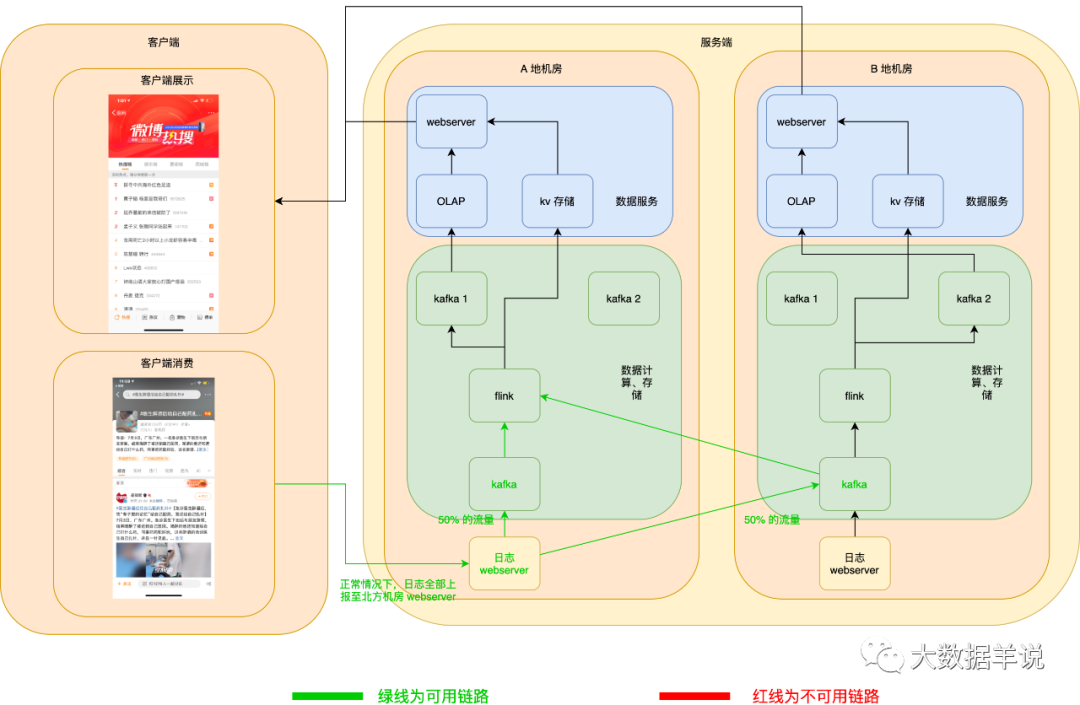
当发生 A 地机房 webserver 宕机时,客户端自动切换上报日志至 B 地机房 webserver。如下图所示:
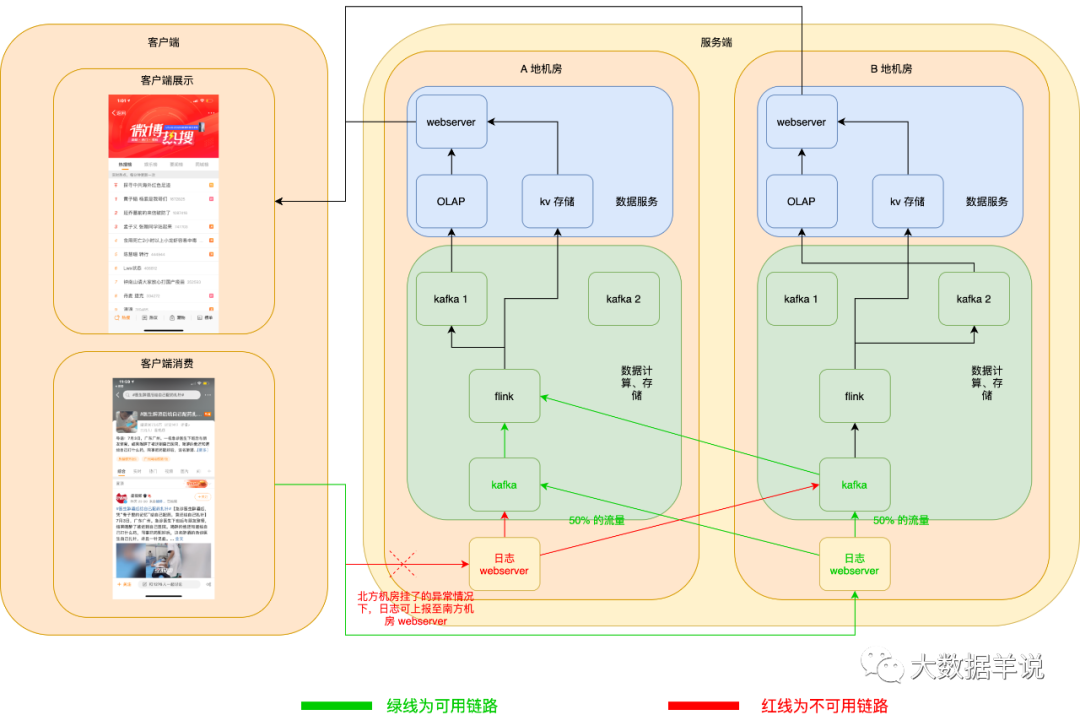
kafka 也相同。如下图所示:
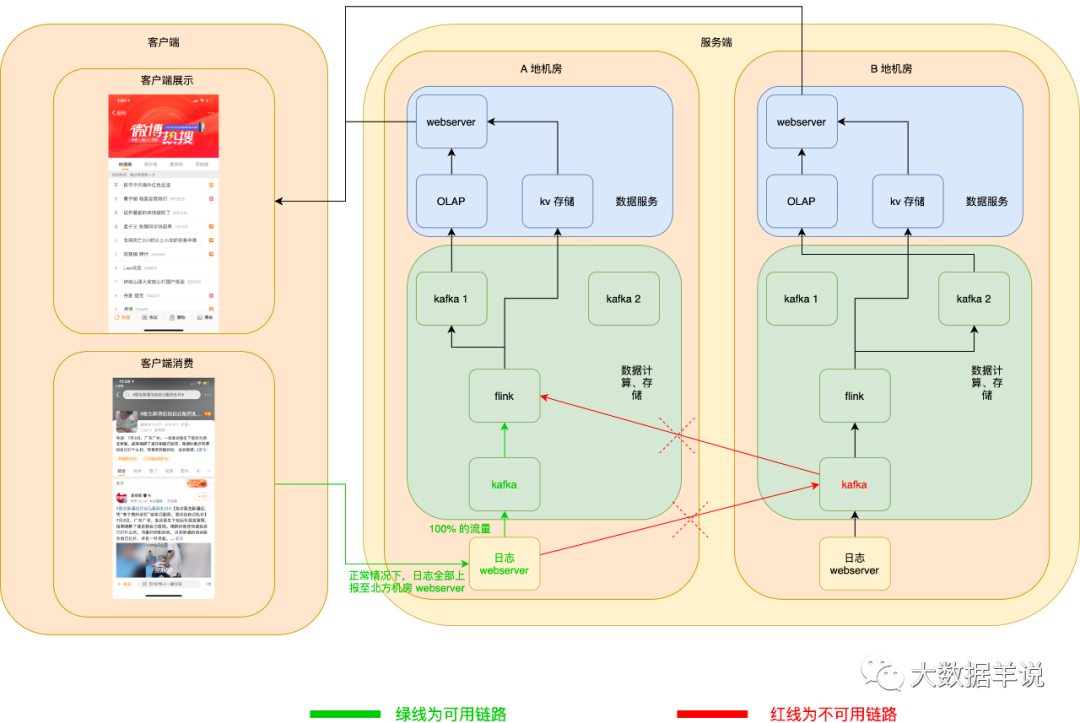
6.6.1.2.flink 任务高可用
flink 任务以 A 地机房做主链路,B 地机房启动相同的任务做热备双跑链路。
当 A 地机房 flink 任务宕机且无法恢复时,则 B 地机房的任务做热备替换。
正常情况下如图所示:
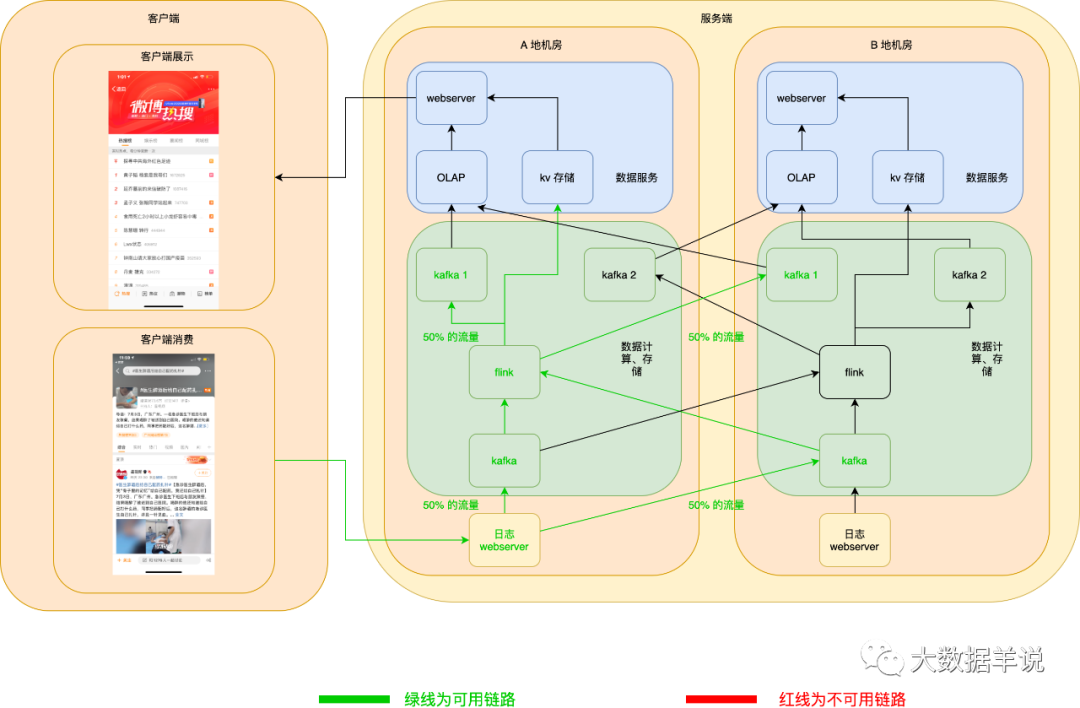
当 A 地机房 flink 任务宕机且无法恢复时,热备链路 flink 任务就可以顶上。如下图所示:

6.6.1.3.数据服务高可用
正常情况如下:
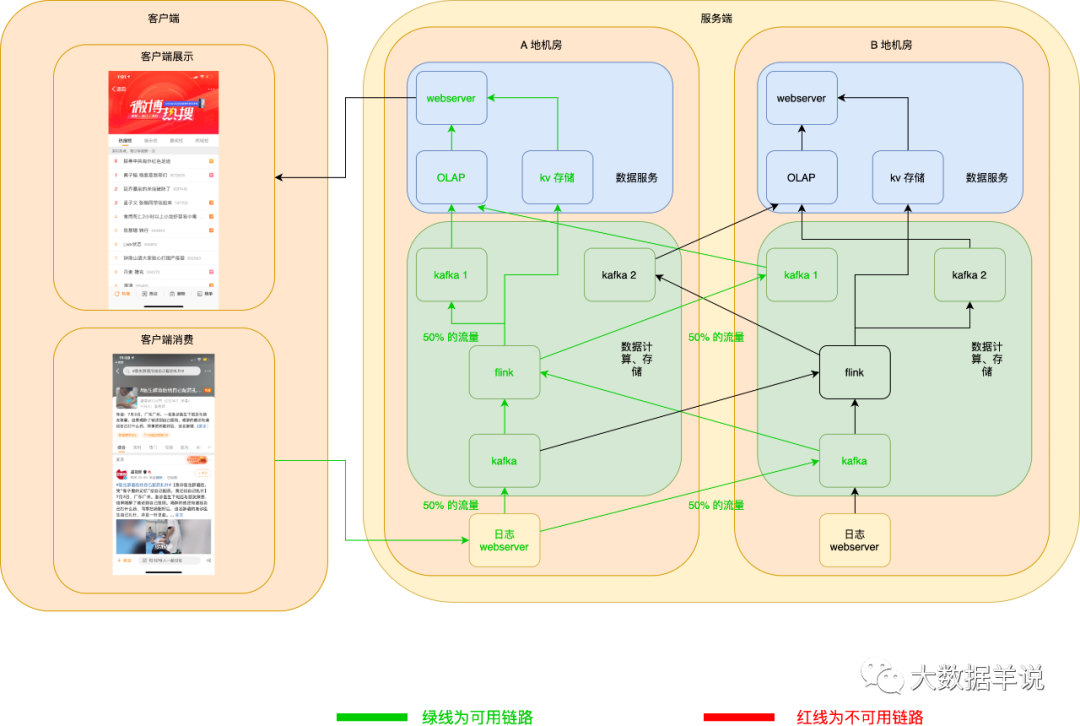
当 A 地 OLAP 或者 KV 存储挂了之后,webserver 可以自动切换至 B 地 OLAP 或者 KV 存储。如下图所示:
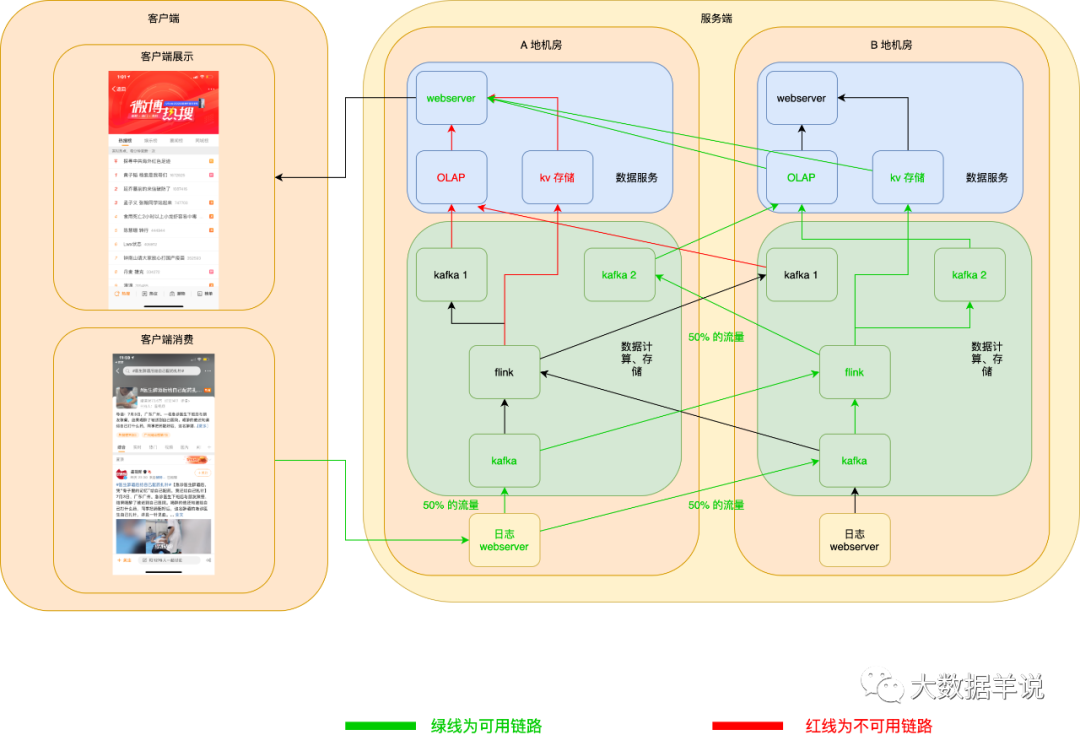
当 A 地 webserver 挂了之后,客户端可以自动拉取 B 地 webserver 数据,如下图所示:
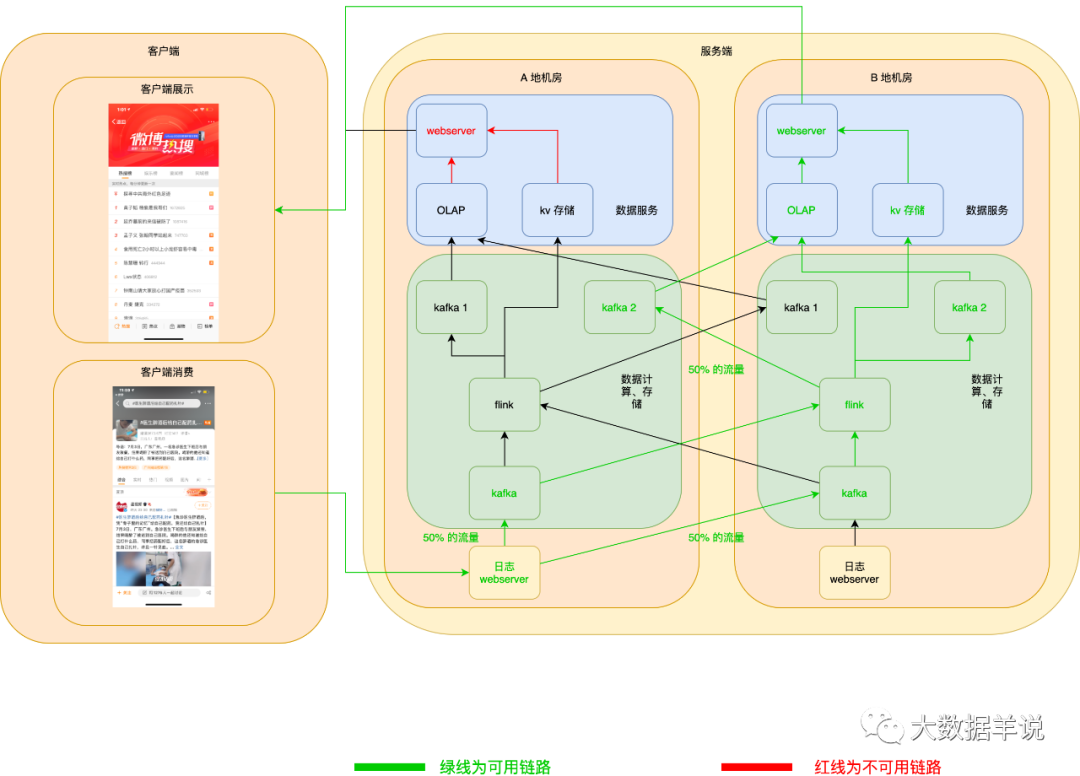
6.6.2.大流量、高性能
6.6.2.1.数据源
数据源、汇反序列化性能提升:静态反序列化性能 > 动态反序列化性能。举例 ProtoBuf。可以在 source 端先进行代码生成,然后用生成好的代码去反序列化源消息的性能会远好于使用 ProtoBuf Dynamic Message。flink 官方实现[4]
6.6.3.缩减状态大小
将状态中的 string 长度做映射之后变小 如果要计算 uv,可以将 string 类的 id 转换为 long 类型 rocksdb 增量 checkpoint,减小任务做 checkpoint 的压力
7.数据服务篇-数据服务选型
7.1.kv 存储
根据我们上述设计的数据汇 schema 来看,最适合存储引擎就是 kv 引擎,因为前端只需要展示最新的排行榜数据即可。所以我们可以使用 redis 等 kv 存储引擎来存储最新的数据。
7.2.OLAP
如果用户有需求需要记录上述数据的历史记录,我们也可以使用时序数据库或者 OLAP 引擎直接进行存储。
8.数据保障篇-数据时效监控以及保障方案
8.1.数据时效保障
见下文。

8.2.数据质量保障
数据质量保障篇楼主正在 gang...
9.效果篇-上述方案最终的效果
9.1.输出结果示例
{
"黄子韬 杨紫是我哥们": 1672825,
"延乔墓前的来信破防了": 1087416,
"孟子义 张翰同学站起来": 747703
// ...
}
9.2.应用产品示例
10.现状以及展望篇
虽然上述 udf 是通用的 udf,但是是否能够脱离自定义 udf,直接计算出 top 50 的值?
我目前的一个想法就是将结果 schema 拍平。举例:
| 字段名 | 字段类型 | 备注 |
|---|---|---|
| timestamp | bigint | 当前分钟事件时间戳 |
| 热搜词条_1 | string | 第一名的热搜词条名称 |
| 热搜词条_2 | string | 第二名的热搜词条名称 |
| 热搜词条_3 | string | 第三名的热搜词条名称 |
| 热搜词条_4 | string | 第四名的热搜词条名称 |
| 热搜词条_5 | string | 第五名的热搜词条名称 |
| ... | ... | ... |
| 热搜词条_n | string | 第 n 名的词条名称 |
每一次输出都将目前每一个排名的数据产出。但是目前在 flink sql 的实现思路上不太明了。