
效率神器-快速定位最慢的代码
天下武功,唯快不破。
编程也不例外,你的代码跑的快,你能快速找出代码慢的原因,你的码功就高。
今天分享一个超级实用的 Python 性能分析工具 pyinstrument ,可以快速找到代码运行最慢的部分,帮助提高代码的性能。支持 Python 3.7+ 且能够分析异步代码,仅需一条命令即可显示具体代码的耗时。经常写 Python 的小伙伴一定要用一下。
安装
pip install pyinstrument
简单的使用
在程序的开始,启动 pyinstrument 的 Profiler,结束时关闭 Profiler 并打印分析结果如下:
from pyinstrument import Profiler
profiler = Profiler()
profiler.start()
# 这里是你要分析的代码
profiler.stop()
profiler.print()
比如这段代码 123.py,我们可以清楚的看到是列表推导式比较慢:
from pyinstrument import Profiler
profiler = Profiler()
profiler.start()
# 这里是你要分析的代码
a = [i for i in range(100000)]
b = (i for i in range(100000))
profiler.stop()
profiler.print()
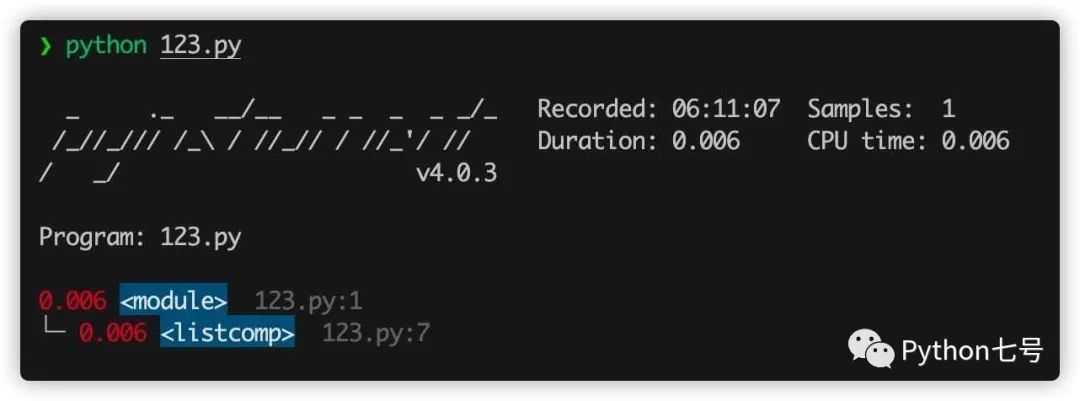
上述分析需要修改源代码,如果你使用命令行工具,就不需要修改源代码,只需要执行 pyinstrument xxxx.py 即可:
比如有这样一段排序的程序 c_sort.py:
import sys
import time
import numpy as np
arr = np.random.randint(0, 10, 10)
def slow_key(el):
time.sleep(0.01)
return el
arr = list(arr)
for i in range(10):
arr.sort(key=slow_key)
print(arr)
这段代码里面故意放了一句 time.sleep(0.01) 来延迟性能,看看 pyinstrument 能否识别,命令行执行 pyinstrument c_sort.py:
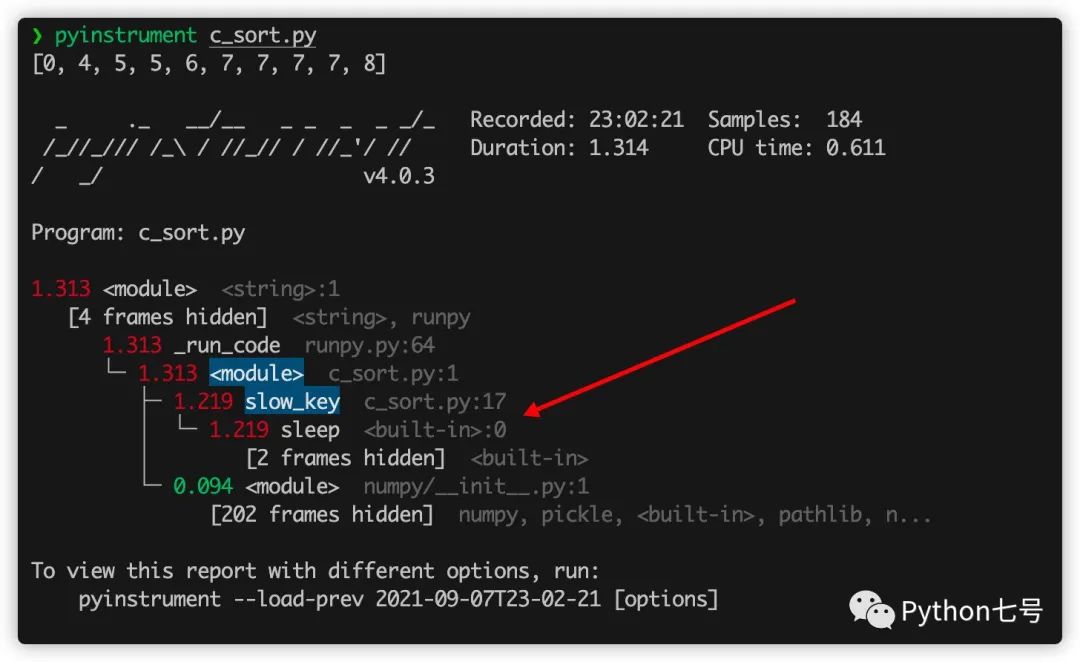
从结果来看,程序运行了 1.313 秒,而 sleep 就运行了 1.219 秒,很明显是瓶颈,现在我们把它删除,再看看结果:
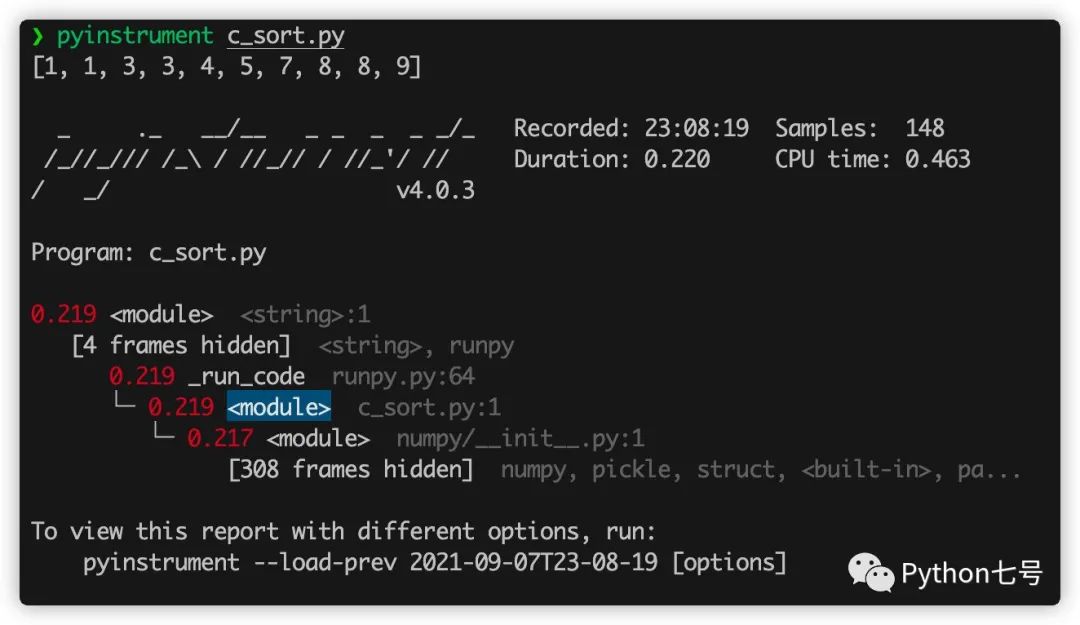
删除之后,性能最慢的就是 numpy 模块的初始化代码 __init__.py了,不过这些代码不是自己写的,而且并不是特别慢,就不需要去关心了。
分析 Flask 代码
Web 应用也可以使用这个来找出性能瓶颈,比如 flask,只需要在请求之前记录时间,在请求之后统计时间,只需要在 flask 的请求拦截器里面这样写:
from flask import Flask, g, make_response, request
app = Flask(__name__)
@app.before_request
def before_request():
if "profile" in request.args:
g.profiler = Profiler()
g.profiler.start()
@app.after_request
def after_request(response):
if not hasattr(g, "profiler"):
return response
g.profiler.stop()
output_html = g.profiler.output_html()
return make_response(output_html)
假如有这样一个 API:
@app.route("/dosomething")
def do_something():
import requests
requests.get("http://google.com")
return "Google says hello!"
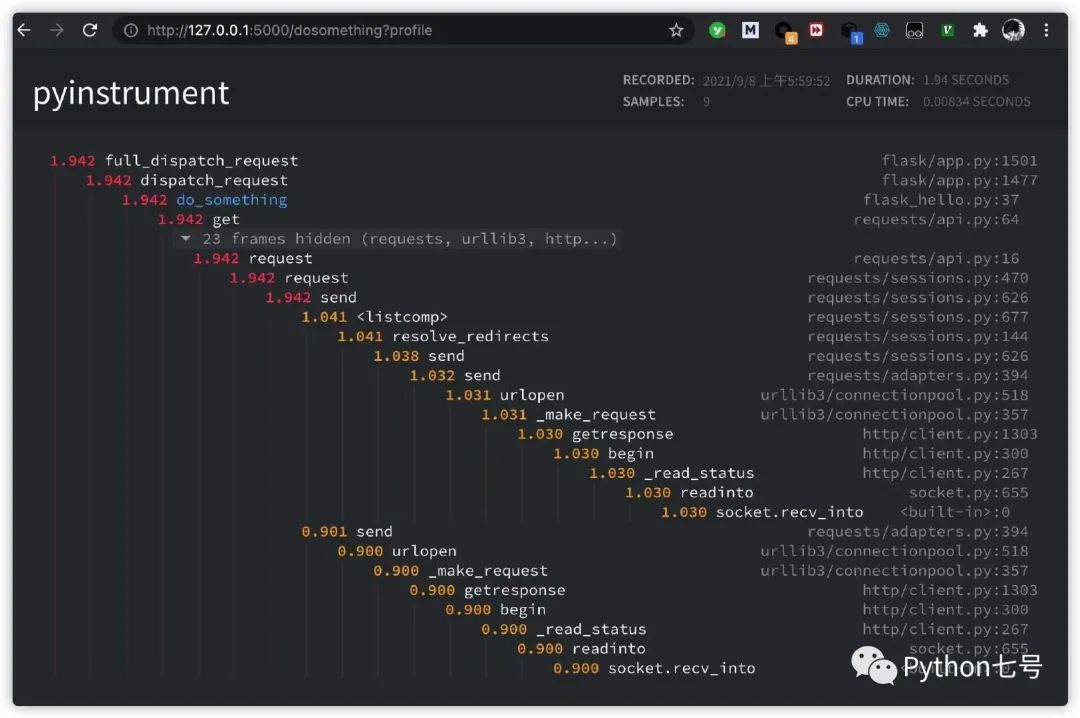
为了测试这个 API 的瓶颈,我们可以在 url 上加一个参数 profile 就可以:http://127.0.0.1:5000/dosomething?profile,哪一行代码执行比较慢,结果清晰可见:
分析 Django 代码
分析 Django 代码也非常简单,只需要在 Django 的配置文件的 MIDDLEWARE 中添加
"pyinstrument.middleware.ProfilerMiddleware",
然后就可以在 url 上加一个参数 profile 就可以:
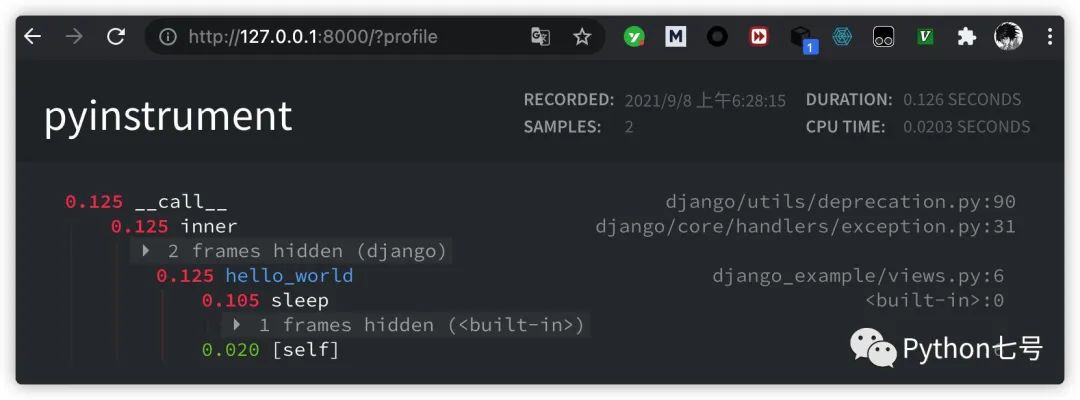
如果你不希望所有人都能看到,只希望管理员可以看到,settings.py 可以添加这样的代码:
def custom_show_pyinstrument(request):
return request.user.is_superuser
PYINSTRUMENT_SHOW_CALLBACK = "%s.custom_show_pyinstrument" % __name__
如果不想通过 url 后面加参数的方式查看性能分析,可以在 settings.py 文件中添加:
PYINSTRUMENT_PROFILE_DIR = 'profiles'
这样,每次访问一次 Django 接口,就会将分析结果以 html 文件形式保存在 项目目录下的 profiles 文件夹中。
分析异步代码
简单的异步代码分析:
async_example_simple.py:
import asyncio
from pyinstrument import Profiler
async def main():
p = Profiler()
with p:
print("Hello ...")
await asyncio.sleep(1)
print("... World!")
p.print()
asyncio.run(main())
复杂一些的异步代码分析:
import asyncio
import time
import pyinstrument
def do_nothing():
pass
def busy_wait(duration):
end_time = time.time() + duration
while time.time() < end_time:
do_nothing()
async def say(what, when, profile=False):
if profile:
p = pyinstrument.Profiler()
p.start()
busy_wait(0.1)
sleep_start = time.time()
await asyncio.sleep(when)
print(f"slept for {time.time() - sleep_start:.3f} seconds")
busy_wait(0.1)
print(what)
if profile:
p.stop()
p.print(show_all=True)
loop = asyncio.get_event_loop()
loop.create_task(say("first hello", 2, profile=True))
loop.create_task(say("second hello", 1, profile=True))
loop.create_task(say("third hello", 3, profile=True))
loop.run_forever()
loop.close()
工作原理
Pyinstrument 每 1ms 中断一次程序,并在该点记录整个堆栈。它使用 C 扩展名和 PyEval_SetProfile 来做到这一点,但只每 1 毫秒读取一次读数。你可能觉得报告的样本数量有点少,但别担心,它不会降低准确性。默认间隔 1ms 是记录堆栈帧的下限,但如果在单个函数调用中花费了很长时间,则会在该调用结束时进行记录。如此有效地将这些样本“打包”并在最后记录。
Pyinstrument 是一个统计分析器,并不跟踪,它不会跟踪您的程序进行的每个函数调用。相反,它每 1 毫秒记录一次调用堆栈。与其他分析器相比,统计分析器的开销比跟踪分析器低得多。
比如说,我想弄清楚为什么 Django 中的 Web 请求很慢。如果我使用 cProfile,我可能会得到这个:
151940 function calls (147672 primitive calls) in 1.696 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 1.696 1.696 profile:0(<code object <module> at 0x1053d6a30, file "./manage.py", line 2>)
1 0.001 0.001 1.693 1.693 manage.py:2(<module>)
1 0.000 0.000 1.586 1.586 __init__.py:394(execute_from_command_line)
1 0.000 0.000 1.586 1.586 __init__.py:350(execute)
1 0.000 0.000 1.142 1.142 __init__.py:254(fetch_command)
43 0.013 0.000 1.124 0.026 __init__.py:1(<module>)
388 0.008 0.000 1.062 0.003 re.py:226(_compile)
158 0.005 0.000 1.048 0.007 sre_compile.py:496(compile)
1 0.001 0.001 1.042 1.042 __init__.py:78(get_commands)
153 0.001 0.000 1.036 0.007 re.py:188(compile)
106/102 0.001 0.000 1.030 0.010 __init__.py:52(__getattr__)
1 0.000 0.000 1.029 1.029 __init__.py:31(_setup)
1 0.000 0.000 1.021 1.021 __init__.py:57(_configure_logging)
2 0.002 0.001 1.011 0.505 log.py:1(<module>)
看完是不是还是一脸懵逼,通常很难理解您自己的代码如何与这些跟踪相关联。Pyinstrument 记录整个堆栈,因此跟踪昂贵的调用要容易得多。它还默认隐藏库框架,让您专注于影响性能的应用程序/模块:
_ ._ __/__ _ _ _ _ _/_ Recorded: 14:53:35 Samples: 131
/_//_/// /_\ / //_// / //_'/ // Duration: 3.131 CPU time: 0.195
/ _/ v3.0.0b3
Program: examples/django_example/manage.py runserver --nothreading --noreload
3.131 <module> manage.py:2
└─ 3.118 execute_from_command_line django/core/management/__init__.py:378
[473 frames hidden] django, socketserver, selectors, wsgi...
2.836 select selectors.py:365
0.126 _get_response django/core/handlers/base.py:96
└─ 0.126 hello_world django_example/views.py:4
最后的话
本文分享了 pyinstrument 的用法,有了这个性能分析神器,以后优化代码可以节省很多时间了,这样的效率神器很值得分享,毕竟人生苦短,能多点时间干点有意思的不香么?如果觉得对你有用,还请关注、点赞、在看支持。
关注我,每天学习一个 Python 小技术。