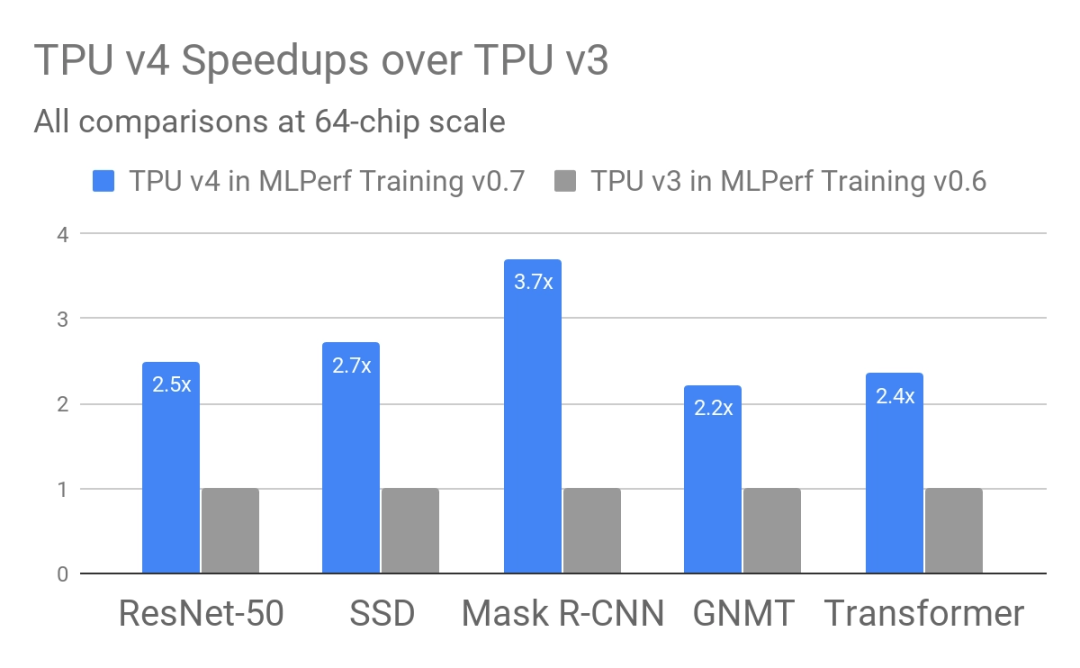
Google第四代TPU 细节曝光!MLPerf榜单决战英伟达A100新智元关注共 2560字,需浏览 6分钟 ·2020-07-30 16:06 新智元报道 来源:venturebeat编辑: 白峰、梦佳【新智元导读】Google 今天分享了第四代 TPU 芯片的细节,据官方介绍,该芯片主要用于训练人工智能模型,平均性能是上一代的2.7倍。 2018年,谷歌在其年度 I/O 开发者大会上宣布了第三代产品,在今天上午刚刚揭开了第四代TPU产品的神秘面纱,该产品目前尚处于研发阶段。 MLPerf 最新发布的一套人工智能性能基准指标显示,第四代 TPU集群大幅超越了第三代 TPU的能力,甚至在目标检测、图像分类、自然语言处理、机器翻译和推荐基准等方面,部分能力超越了英伟达最新发布的 A100。 MLPerf是致力于机器学习硬件、软件和服务的训练和推理性能测试的组织,在AI业界颇受芯片巨头的关注。MLPerf组织囊括了该行业中的70多个知名企业和机构,包括英特尔、英伟达、Google、亚马逊、阿里巴巴和百度、微软、斯坦福大学在内。 谷歌第四代 TPU 的平均性能是上一代2.7 倍没有最强,只有更强! 谷歌称其第四代 TPU 提供的每秒浮点运算次数是第三代 TPU 的两倍多,第三代 TPU 的每秒矩阵乘法相当于1万亿次浮点运算。 在内存带宽方面,也表现出了「显著」的增长,芯片从内存中获取数据进行处理的速度、执行专门计算的能力都有所提高。谷歌表示,总体而言,第四代 TPU 的性能在去年的 MLPerf 基准测试中比第三代 TPU 的性能平均提高了2.7倍。 TPU是谷歌在2015年推出的神经网络专用芯片,为优化自身的TensorFlow机器学习框架而打造,跟GPU不同,谷歌TPU是一种ASIC芯片方案,属于专门定制的芯片,研发成本极高。 谷歌的处理器是专门为加速人工智能而开发的应用集成电路(asic)。它们是液体冷却的,可以插入服务器机架; 可以提供高达100petaflops 的计算能力; 还可以支持谷歌产品,如谷歌搜索、谷歌照片、谷歌翻译、谷歌助理、谷歌邮箱和谷歌云计算人工智能API。 谷歌人工智能软件工程师 Naveen Kumar 在一篇博客文章中写道: 「这表明我们致力于推进机器学习研究和工程的规模化,并通过谷歌开源软件、谷歌产品和谷歌云将这些进步传递给用户」。「机器学习模型的快速训练对于研究和工程团队来说至关重要,意味着团队可以提供以前无法实现的新产品、服务和研究突破。」 ImageNet图像分类任务,256个TPU1.82分钟完成训练今年的 MLPerf 结果显示,谷歌的第四代TPU几乎无可挑剔。在一个图像分类任务中,用 ImageNet 数据集训练ResNet-50 v1.5达到75.90% 的准确率,256个第四代 TPUs 可以在1.82分钟内完成。 这个速度是什么概念,几乎相当于768个英伟达 A100显卡和192 个AMD Epyc 7742 CPU 内核(1.06分钟)和512个华为 ai 优化的 ascen910芯片与128个英特尔至强铂金8168内核(1.56分钟)的速度。 第四代TPU的训练时间为0.48分钟,打败了第三代TPU,但这或许只是因为第三代是4096个TPU串联的原因。 第四代 TPU 在运行 Mask R-CNN 模型时获得了最强的效果,Mask R-CNN 模型是用于自动驾驶等领域的图像分割 AI,其训练速度是第三代TPU的 3.7 倍。 目标检测任务四代TPU略微领先在 MLPerf 的「重量级」目标检测类别中,第四代 TPU略微领先。一个参考模型(Mask R-CNN)用 COCO 语料库在256个第四代TPU上进行9.95分钟的训练,接近512个第三代TPU的时间(8.13分钟)。 在WMT 英德翻译数据集上训练 Transformer 模型,256个第四代 TPU 在0.78分钟内完成。4,096个第三代 TPU要发花费 0.35分钟,480个 Nvidia A100(外加256个 AMD Epyc 7742 CPU 内核)要花费0.62分钟。 第四代TPU在维基百科等大型语料库上训练 BERT 模型时也表现良好。使用256个第四代 TPU的训练时间为1.82分钟,仅比使用4096个第三代 TPUs 的0.39分钟稍慢。同时,使用 Nvidia 硬件0.81分钟就能完成训练,但需要2048块 A100卡和512块 AMD Epyc 7742 CPU 内核。 最新的 MLPerf ,包括新的和修改过的基准测试--推荐系统和强化学习,对于 TPU来说是喜忧参半。 由64个第四代 TPU 组成的集群在推荐任务中表现良好,花了1.12分钟在 Criteo AI 实验室的 1TB 点击率日志数据集训练了一个模型,而八块 Nvidia A100卡和两块 AMD Epyc 7742 CPU 核心用了3.33分钟才完成训练。 但英伟达在强化学习方向上取得了领先,用256块 A100卡和64块 AMD Epyc 7742 CPU 核心,用了29.7分钟,成功训练了一款简化版围棋模型,获胜率达到50% ,而256个第四代 TPU一共花了150.95分钟。 需要注意的一点是,Nvidia 的硬件基准是 Facebook 的 PyTorch 框架和 Nvidia 自己的框架,而不是 Google 的 TensorFlow,第三代和第四代的 TPU 都使用了 TensorFlow、 JAX 和 Lingvo。虽然这可能对结果有些影响,但在基准测试中还是能看出第四代 TPU 有着明显优势。参考链接:https://venturebeat.com/2020/07/29/google-claims-its-new-tpus-are-2-7-times-faster-than-the-previous-generation/ 浏览 52点赞 评论 收藏 分享 手机扫一扫分享分享 举报 评论图片表情视频评价全部评论推荐 英伟达:下一代GPU细节曝光本文转自“英伟达:下一代GPU细节曝光”。Nvidia 正在准备该公司的 GeForce RTX 50 系列 (Blackwell) 产品,以与最好的显卡相竞争。著名硬件泄密者 @kopite7kimi 声称,根据他的信息,Blackwell系列的内存接口配置不会与Ada Lovelace系列有太大谷歌训练BERT只用23秒,英伟达A100打破八项AI性能纪录,最新MLPerf榜单出炉极市平台0英伟达RTX 3080 Ti遭曝光,预计5月初上市雷锋网0NeurIPS 2021:英伟达EditGAN机器学习与生成对抗网络0英伟达调整的思考公众号改版,及时收到文章推送需要给公众号加星。大家可以点击页面上方蓝色字【京北夜光】,进入公众号首页,点右上角“...”,点下方“设为星标”。坚持复盘总结分享不容易,点右上角点个在看并分享到朋友圈,看完顺手点个点赞和在看,算是个认可,感谢。本文首发于公众号(建议关注):近期NV高点回调,主要系黄仁勋英伟达,GPU大招来袭!智能计算芯世界0挑战 Google TPU,AI 芯片新玩家面临哪些难题?雷锋网05300亿NLP模型“威震天-图灵”发布,由4480块A100训练,微软英伟达联合出品视学算法0英伟达的AI太强了!公众号CVer0英伟达内网遭黑客攻击芯智讯0点赞 评论 收藏 分享 手机扫一扫分享分享 举报



 下载APP
下载APP