
谷歌训练BERT只用23秒,英伟达A100打破八项AI性能纪录,最新MLPerf榜单出炉
加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~

在距离推出不到一个月的时间里,内置超过 2000 块英伟达 A100 GPU 的全新 DGX SuperPOD 服务器就在各项针对大规模计算性能的 MLPerf 基准测试中取得了优异成绩。
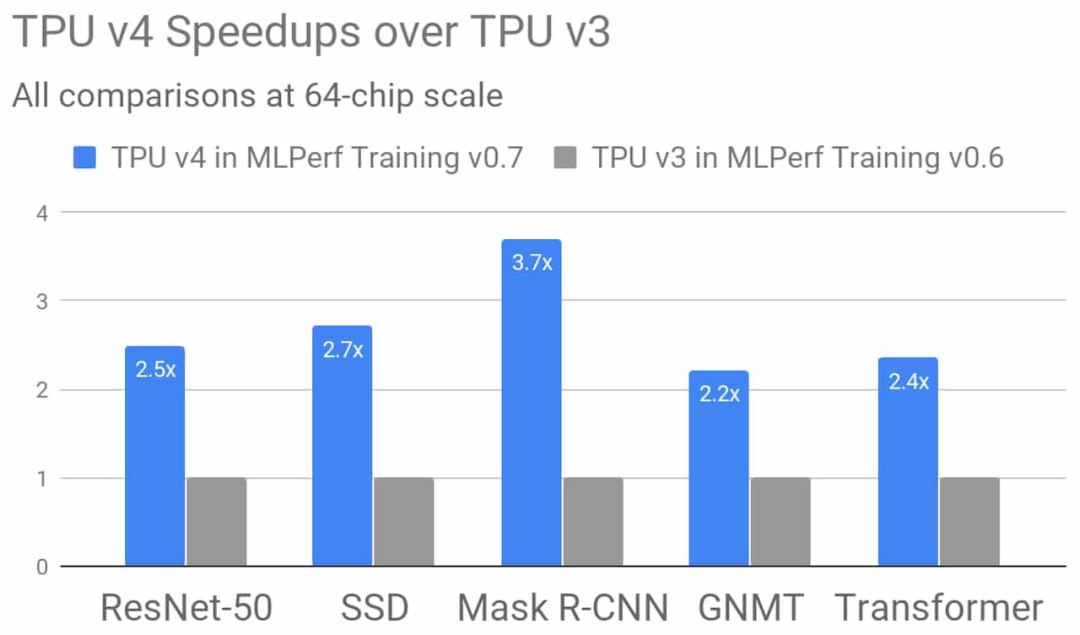
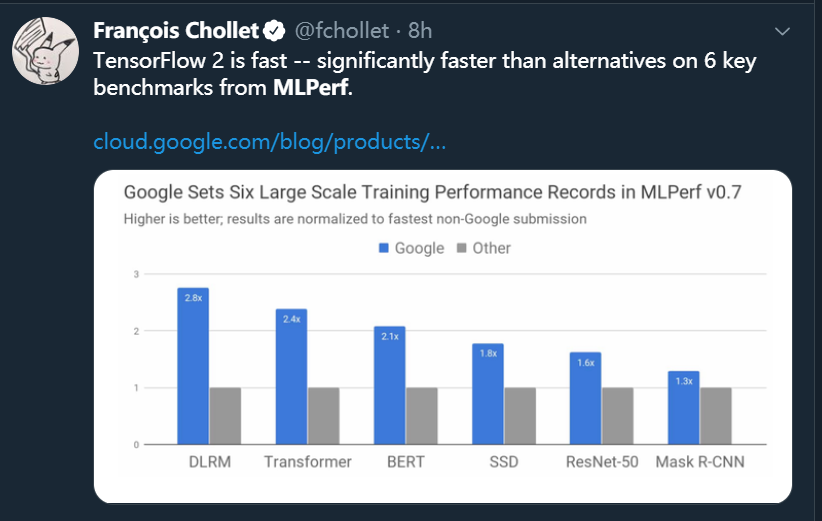
在今天官方发布的 MLPerf 第三批 AI 训练芯片测试结果中,英伟达 A100 Tensor Core GPU 在全部八项基准测试中展现了最快性能。在实现总体最快的大规模解决方案方面,利用 HDR InfiniBand 实现多个 DGX A100 系统互联的服务器集群 DGX SuperPOD 系统也同样创造了业内最优性能。
行业基准测试组织 MLPerf 于 2018 年 5 月由谷歌、百度、英特尔、AMD、哈佛和斯坦福大学共同发起,目前已成为机器学习领域芯片性能的重要参考标准。此次结果已是英伟达在 MLPerf 训练测试中连续第三次展现了最强性能。早在 2018 年 12 月,英伟达就曾在 MLPerf 训练基准测试中创下了六项纪录,次年 7 月英伟达再次创下八项纪录。
最新版的 MLPerf 基准测试包含 8 个领域的 8 项测试,分别为目标检测(light-weight、heavy-weight)、翻译(recurrent、non-recurrent)、NLP、推荐系统、强化学习,参与测试的模型包括 SSD、Mask R-CNN、NMT、BERT 等。MLPerf 在强化学习测试中使用了 Mini-go 和全尺寸 19×19 围棋棋盘。该测试是本轮最复杂的测试,内容涵盖从游戏到训练的多项操作。


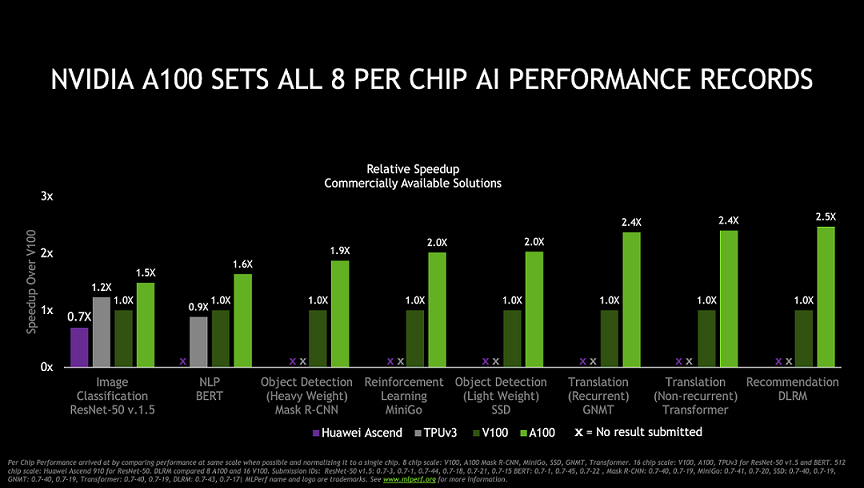
英伟达 A100 在 MLPerf 单卡性能名列前茅的全部八项测试,最新的 MLPerf 榜单中还有华为昇腾 910 的成绩。
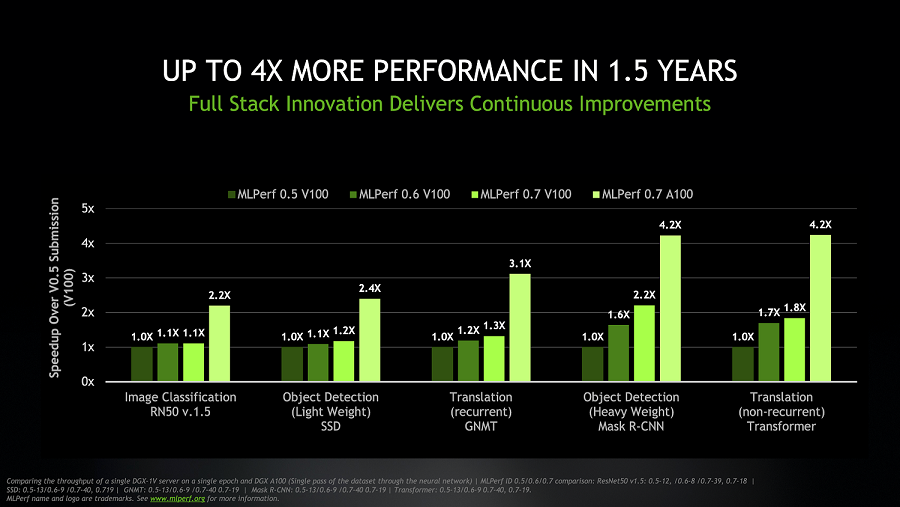

程序员大神,谷歌 AI 负责人 Jeff Dean 说道:「我们需要更大的基准测试,因为现在训练 ResNet-50、BERT、Transformer、SSD 这种模型只需要不到 30 秒了。」
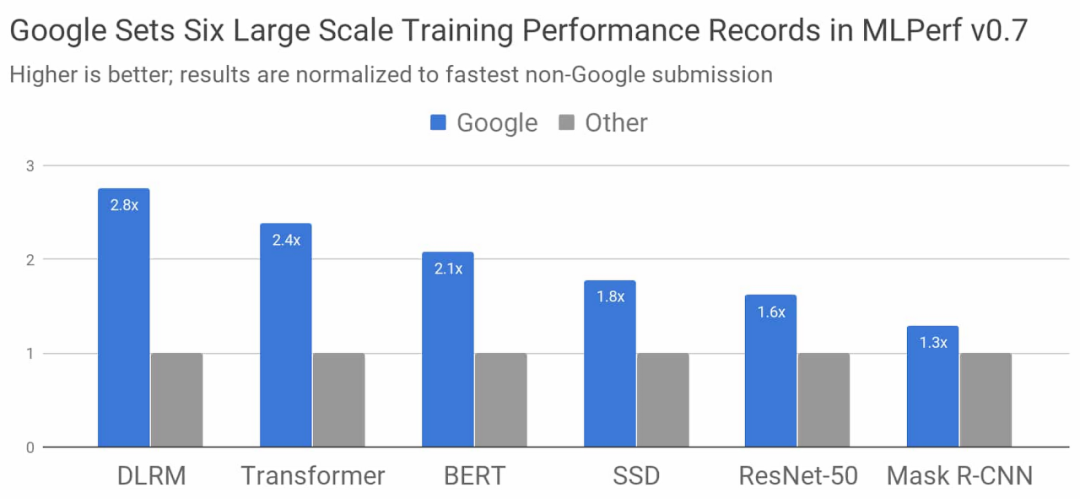
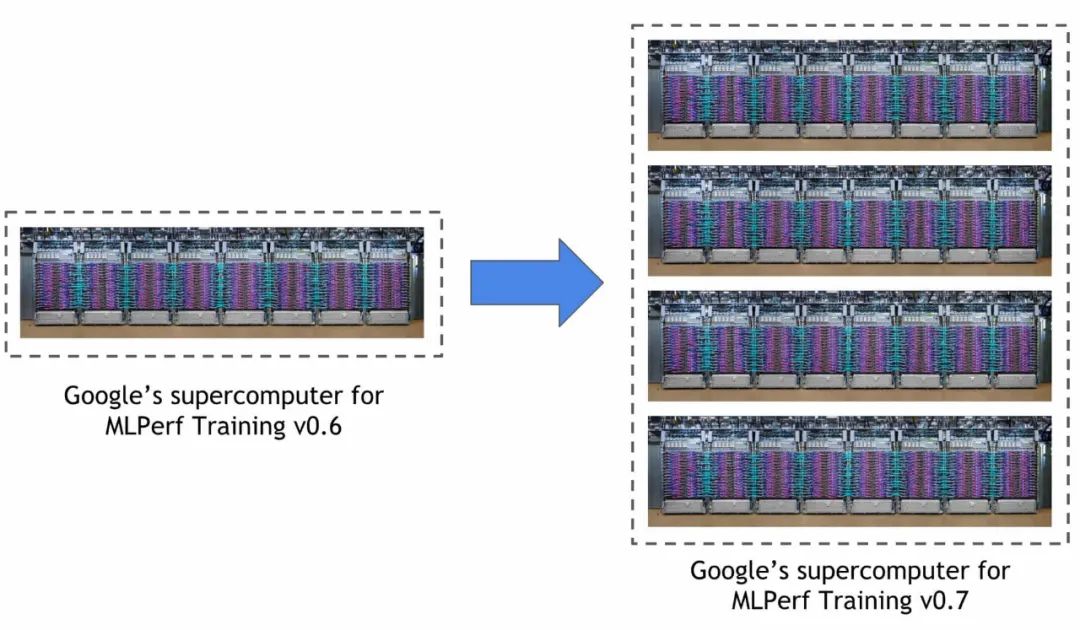
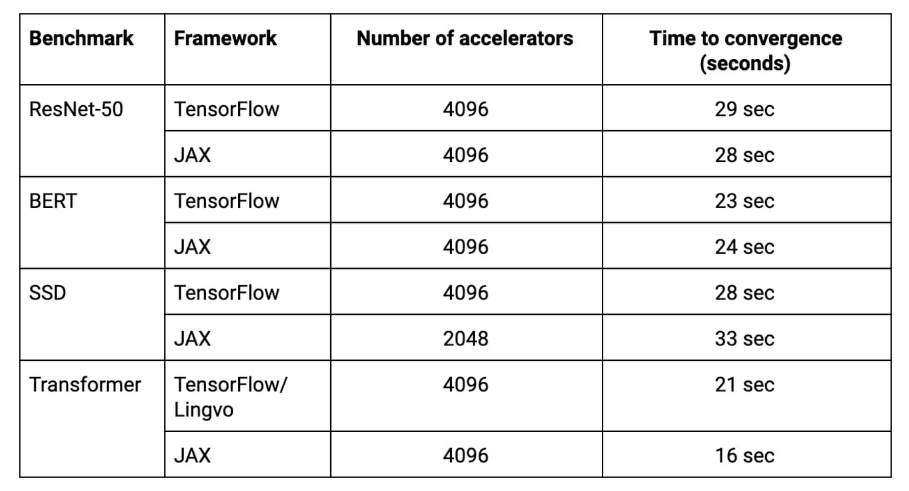
在谷歌最新的 ML 超级计算机上,上述所有模型的训练都可以在 33 秒内完成。

https://cloud.google.com/blog/products/ai-machine-learning/google-breaks-ai-performance-records-in-mlperf-with-worlds-fastest-training-supercomputer https://blogs.nvidia.com/blog/2020/07/29/mlperf-training-benchmark-records/? utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+nvidiablog+%28The+NVIDIA+Blog%29 https://mlperf.org/training-results-0-7
推荐阅读
