
PyTorch 单机多卡操作总结:分布式DataParallel,混合精度,Horovod)

极市导读
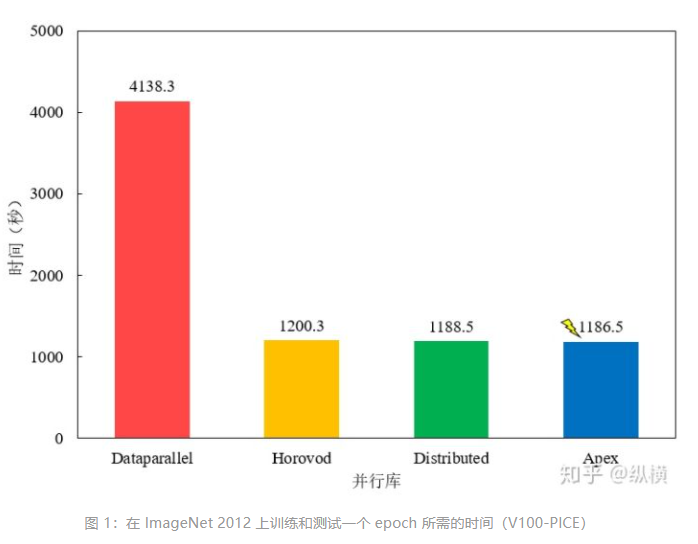
本文介绍了数种实现单机多卡操作的方法,含有大量代码,并给出了实践中作者踩过的坑及其解决方案。>>加入极市CV技术交流群,走在计算机视觉的最前沿
1. 先问两个问题
参与训练的 GPU 有哪些,device_ids=gpus。 用于汇总梯度的 GPU 是哪个,output_device=gpus[0] 。
model = nn.DataParallel(model.cuda(), device_ids=gpus, output_device=gpus[0])
# main.py
import torch
import torch.distributed as dist
gpus = [0, 1, 2, 3]
torch.cuda.set_device('cuda:{}'.format(gpus[0]))
train_dataset = ...
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=...)
model = ...
model = nn.DataParallel(model.to(device), device_ids=gpus, output_device=gpus[0])
optimizer = optim.SGD(model.parameters())
for epoch in range(100):
for batch_idx, (data, target) in enumerate(train_loader):
images = images.cuda(non_blocking=True)
target = target.cuda(non_blocking=True)
...
output = model(images)
loss = criterion(output, target)
...
optimizer.zero_grad()
loss.backward()
optimizer.step()
稍微解释几句:model.to(device)将模型迁移到GPU里面,images.cuda,target.cuda把数据迁移到GPU里面。
nn.DataParallel(model.to(device), device_ids=gpus, output_device=gpus[0])包装模型。
在每个训练批次(batch)中,因为模型的权重都是在一个进程上先算出来,然后再把他们分发到每个GPU上,所以网络通信就成为了一个瓶颈,而GPU使用率也通常很低。 除此之外,nn.DataParallel 需要所有的GPU都在一个节点(一台机器)上,且并不支持 Apex 的 混合精度训练。
2. 使用 torch.distributed 加速并行训练:
2.1 介绍
DistributedDataParallel 解决 DataParallel 速度慢,GPU 负载不均衡的问题,目前已经很成熟了。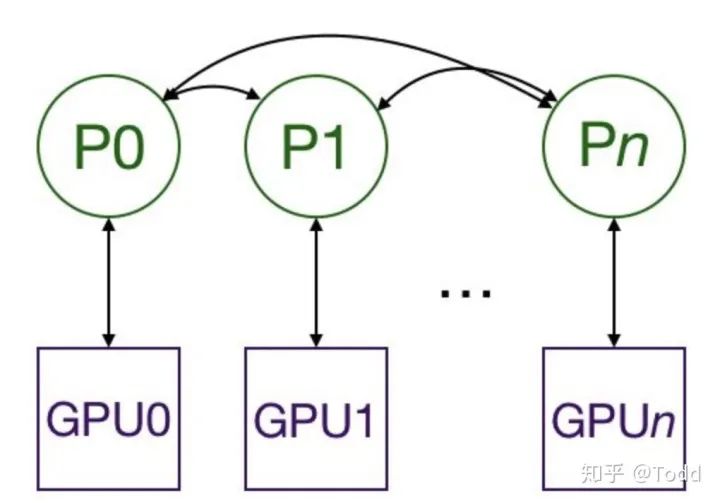
在喂数据的时候,一个batch被分到了好几个进程,每个进程在取数据的时候要确保拿到的是不同的数据( DistributedSampler);要告诉每个进程自己是谁,使用哪块GPU( args.local_rank);在做BatchNormalization的时候要注意同步数据。
2.2 使用方式
2.2.1 启动方式的改变
评论