
PyTorch 单机多卡操作总结:分布式DataParallel,混合精度,Horovod)
导读
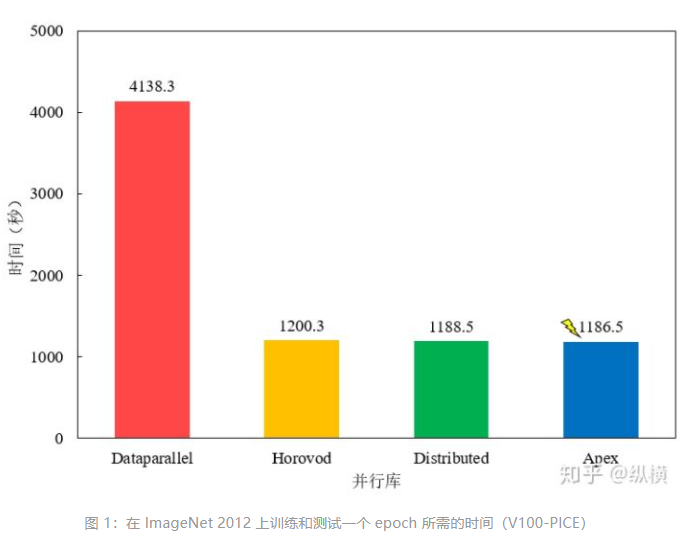
本文介绍了数种实现单机多卡操作的方法,含有大量代码,并给出了实践中作者踩过的坑及其解决方案。
1. 先问两个问题
参与训练的 GPU 有哪些,device_ids=gpus。 用于汇总梯度的 GPU 是哪个,output_device=gpus[0] 。
model = nn.DataParallel(model.cuda(), device_ids=gpus, output_device=gpus[0])
# main.py
import torch
import torch.distributed as dist
gpus = [0, 1, 2, 3]
torch.cuda.set_device('cuda:{}'.format(gpus[0]))
train_dataset = ...
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=...)
model = ...
model = nn.DataParallel(model.to(device), device_ids=gpus, output_device=gpus[0])
optimizer = optim.SGD(model.parameters())
for epoch in range(100):
for batch_idx, (data, target) in enumerate(train_loader):
images = images.cuda(non_blocking=True)
target = target.cuda(non_blocking=True)
...
output = model(images)
loss = criterion(output, target)
...
optimizer.zero_grad()
loss.backward()
optimizer.step()
稍微解释几句:model.to(device)将模型迁移到GPU里面,images.cuda,target.cuda把数据迁移到GPU里面。
nn.DataParallel(model.to(device), device_ids=gpus, output_device=gpus[0])包装模型。
在每个训练批次(batch)中,因为模型的权重都是在一个进程上先算出来,然后再把他们分发到每个GPU上,所以网络通信就成为了一个瓶颈,而GPU使用率也通常很低。 除此之外,nn.DataParallel 需要所有的GPU都在一个节点(一台机器)上,且并不支持 Apex 的 混合精度训练。
2. 使用 torch.distributed 加速并行训练:
2.1 介绍
DistributedDataParallel 解决 DataParallel 速度慢,GPU 负载不均衡的问题,目前已经很成熟了。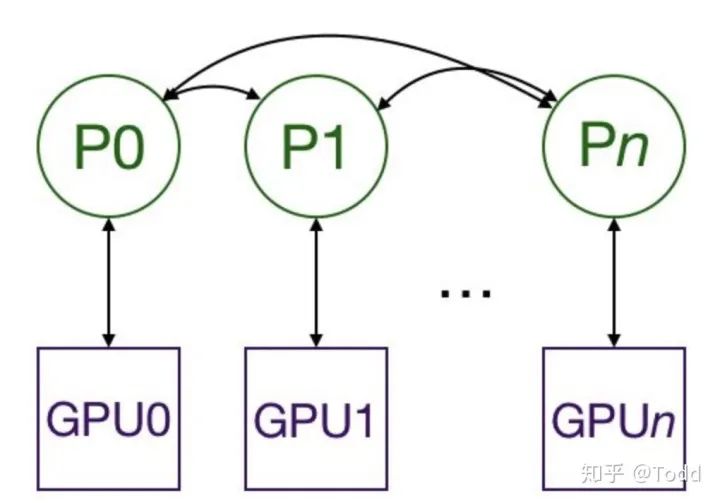
在喂数据的时候,一个batch被分到了好几个进程,每个进程在取数据的时候要确保拿到的是不同的数据( DistributedSampler);要告诉每个进程自己是谁,使用哪块GPU( args.local_rank);在做BatchNormalization的时候要注意同步数据。
2.2 使用方式
2.2.1 启动方式的改变
torch.distributed.launch 用于启动文件,所以我们运行训练代码的方式就变成了这样:CUDA_VISIBLE_DEVICES=0,1,2,3 python \-m torch.distributed.launch \--nproc_per_node=4 main.py--nproc_per_node 参数用于指定为当前主机创建的进程数,由于我们是单机多卡,所以这里node数量为1,所以我们这里设置为所使用的GPU数量即可。2.2.2 初始化
local_rank 来告诉我们当前进程使用的是哪个GPU,用于我们在每个进程中指定不同的device:def parse():
parser = argparse.ArgumentParser()
parser.add_argument('--local_rank', type=int, default=0,help='node rank for distributed training')
args = parser.parse_args()
return args
def main():
args = parse()
torch.cuda.set_device(args.local_rank)
torch.distributed.init_process_group(
'nccl',
init_method='env://'
)
device = torch.device(f'cuda:{args.local_rank}')
...
2.2.3 DataLoader
data loader 的时候需要使用到 torch.utils.data.distributed.DistributedSampler 这个特性:train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=..., sampler=train_sampler)
2.2.4 模型的初始化
nn.DataParallel 的方式一样,我们对于模型的初始化也是简单的一句话就行了model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank])2.2.5 同步BN
apex 中看到这一功能。# main.py
import torch
import argparse
import torch.distributed as dist
parser = argparse.ArgumentParser()
parser.add_argument('--local_rank', default=-1, type=int,
help='node rank for distributed training')
args = parser.parse_args()
dist.init_process_group(backend='nccl')
torch.cuda.set_device(args.local_rank)
train_dataset = ...
#每个进程一个sampler
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=..., sampler=train_sampler)
model = ...
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank])
optimizer = optim.SGD(model.parameters())
for epoch in range(100):
for batch_idx, (data, target) in enumerate(train_loader):
images = images.cuda(non_blocking=True)
target = target.cuda(non_blocking=True)
...
output = model(images)
loss = criterion(output, target)
...
optimizer.zero_grad()
loss.backward()
optimizer.step()
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 main.py
3. 使用 apex 再加速(混合精度训练、并行训练、同步BN):
3.1 介绍
Volta结构的GPU,目前只有Tesla V100和TITAN V系列支持。内存占用更少:这个是显然可见的,通用的模型 fp16 占用的内存只需原来的一半。memory-bandwidth 减半所带来的好处:
模型占用的内存更小,训练的时候可以用更大的batchsize。 模型训练时,通信量(特别是多卡,或者多机多卡)大幅减少,大幅减少等待时间,加快数据的流通。 计算更快:
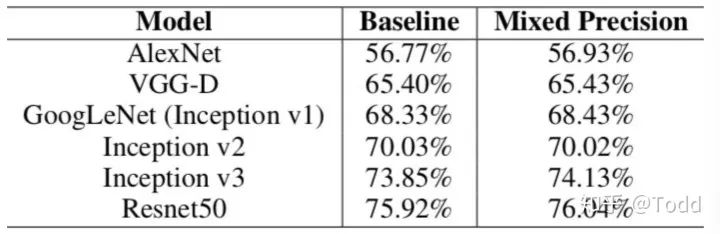
目前的不少GPU都有针对 fp16 的计算进行优化。论文指出:在近期的GPU中,半精度的计算吞吐量可以是单精度的 2-8 倍;从下图我们可以看到混合精度训练几乎没有性能损失。
3.2 使用方式
3.2.1 混合精度
amp.initialize 包装模型和优化器,apex 就会自动帮助我们管理模型参数和优化器的精度了,根据精度需求不同可以传入其他配置参数。from apex import amp
model, optimizer = amp.initialize(model, optimizer, opt_level='O1')
O0:纯FP32训练,可以作为accuracy的baseline; O1:混合精度训练(推荐使用),根据黑白名单自动决定使用FP16(GEMM, 卷积)还是FP32(Softmax)进行计算。 O2:“几乎FP16”混合精度训练,不存在黑白名单,除了Batch norm,几乎都是用FP16计算。 O3:纯FP16训练,很不稳定,但是可以作为speed的baseline;
3.2.2 并行训练
from apex import amp
from apex.parallel import DistributedDataParallel
model, optimizer = amp.initialize(model, optimizer, opt_level='O1')
model = DistributedDataParallel(model, delay_allreduce=True)
# 反向传播时需要调用 amp.scale_loss,用于根据loss值自动对精度进行缩放
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
3.2.3 同步BN
from apex.parallel import convert_syncbn_model
from apex.parallel import DistributedDataParallel
# 注意顺序:三个顺序不能错
model = convert_syncbn_model(UNet3d(n_channels=1, n_classes=1)).to(device)
model, optimizer = amp.initialize(model, optimizer, opt_level='O1')
model = DistributedDataParallel(model, delay_allreduce=True)
# main.py
import torch
import argparse
import torch.distributed as dist
from apex.parallel import convert_syncbn_model
from apex.parallel import DistributedDataParallel
parser = argparse.ArgumentParser()
parser.add_argument('--local_rank', default=-1, type=int,
help='node rank for distributed training')
args = parser.parse_args()
dist.init_process_group(backend='nccl')
torch.cuda.set_device(args.local_rank)
train_dataset = ...
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=..., sampler=train_sampler)
model = ...
#同步BN
model = convert_syncbn_model(model)
#混合精度
model, optimizer = amp.initialize(model, optimizer)
#分布数据并行
model = DistributedDataParallel(model, device_ids=[args.local_rank])
optimizer = optim.SGD(model.parameters())
for epoch in range(100):
for batch_idx, (data, target) in enumerate(train_loader):
images = images.cuda(non_blocking=True)
target = target.cuda(non_blocking=True)
...
output = model(images)
loss = criterion(output, target)
optimizer.zero_grad()
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
optimizer.step()
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 main.py
4 多卡训练时的数据记录(TensorBoard、torch.save)
4.1 记录Loss曲线
def reduce_tensor(tensor: torch.Tensor) -> torch.Tensor:
rt = tensor.clone()
distributed.all_reduce(rt, op=distributed.reduce_op.SUM)
rt /= distributed.get_world_size()#总进程数
return rt
# calculate loss
loss = criterion(predict, labels)
reduced_loss = reduce_tensor(loss.data)
train_epoch_loss += reduced_loss.item()
注意在写入TensorBoard的时候只让一个进程写入就够了:
# TensorBoard
if args.local_rank == 0:
writer.add_scalars('Loss/training', {
'train_loss': train_epoch_loss,
'val_loss': val_epoch_loss
}, epoch + 1)
4.2 torch.save
# Save checkpoint
checkpoint = {
'model': model.state_dict(),
'optimizer': optimizer.state_dict(),
'amp': amp.state_dict()
}
torch.save(checkpoint, 'amp_checkpoint.pt')
...
# Restore
model = ...
optimizer = ...
checkpoint = torch.load('amp_checkpoint.pt')
model, optimizer = amp.initialize(model, optimizer, opt_level=opt_level)
model.load_state_dict(checkpoint['model'])
optimizer.load_state_dict(checkpoint['optimizer'])
amp.load_state_dict(checkpoint['amp'])
# Continue training
...
5 多卡后的 batch_size 和 learning_rate 的调整
6 完整代码示例(Apex混合精度的Distributed DataParallel,用来训练3D U-Net的)
import os
import datetime
import argparse
from tqdm import tqdm
import torch
from torch import distributed, optim
from torch.utils.data import DataLoader
#每个进程不同sampler
from torch.utils.data.distributed import DistributedSampler
from torch.utils.tensorboard import SummaryWriter
#混合精度
from apex import amp
#同步BN
from apex.parallel import convert_syncbn_model
#Distributed DataParallel
from apex.parallel import DistributedDataParallel
from models import UNet3d
from datasets import IronGrain3dDataset
from losses import BCEDiceLoss
from eval import eval_net
train_images_folder = '../../datasets/IronGrain/74x320x320/train_patches/images/'
train_labels_folder = '../../datasets/IronGrain/74x320x320/train_patches/labels/'
val_images_folder = '../../datasets/IronGrain/74x320x320/val_patches/images/'
val_labels_folder = '../../datasets/IronGrain/74x320x320/val_patches/labels/'
def parse():
parser = argparse.ArgumentParser()
parser.add_argument('--local_rank', type=int, default=0)
args = parser.parse_args()
return args
def main():
args = parse()
#设置当前进程的device,GPU通信方式为NCCL
torch.cuda.set_device(args.local_rank)
distributed.init_process_group(
'nccl',
init_method='env://'
)
#制作Dataset和sampler
train_dataset = IronGrain3dDataset(train_images_folder, train_labels_folder)
val_dataset = IronGrain3dDataset(val_images_folder, val_labels_folder)
train_sampler = DistributedSampler(train_dataset)
val_sampler = DistributedSampler(val_dataset)
epochs = 100
batch_size = 8
lr = 2e-4
weight_decay = 1e-4
device = torch.device(f'cuda:{args.local_rank}')
#制作DataLoader
train_loader = DataLoader(train_dataset, batch_size=batch_size, num_workers=4,
pin_memory=True, sampler=train_sampler)
val_loader = DataLoader(val_dataset, batch_size=batch_size, num_workers=4,
pin_memory=True, sampler=val_sampler)
#3步曲:同步BN,初始化amp,DistributedDataParallel封装
net = convert_syncbn_model(UNet3d(n_channels=1, n_classes=1)).to(device)
optimizer = optim.Adam(net.parameters(), lr=lr, weight_decay=weight_decay)
net, optimizer = amp.initialize(net, optimizer, opt_level='O1')
net = DistributedDataParallel(net, delay_allreduce=True)
scheduler = optim.lr_scheduler.MultiStepLR(optimizer, milestones=[25, 50, 75], gamma=0.2)
criterion = BCEDiceLoss().to(device)
if args.local_rank == 0:
print(f'''Starting training:
Epochs: {epochs}
Batch size: {batch_size}
Learning rate: {lr}
Training size: {len(train_dataset)}
Validation size: {len(val_dataset)}
Device: {device.type}
''')
writer = SummaryWriter(
log_dir=f'runs/irongrain/unet3d_32x160x160_BS_{batch_size}_{datetime.datetime.now()}'
)
for epoch in range(epochs):
train_epoch_loss = 0
with tqdm(total=len(train_dataset), desc=f'Epoch {epoch + 1}/{epochs}', unit='img') as pbar:
images = None
labels = None
predict = None
# train
net.train()
for batch_idx, batch in enumerate(train_loader):
images = batch['image']
labels = batch['label']
images = images.to(device, dtype=torch.float32)
labels = labels.to(device, dtype=torch.float32)
predict = net(images)
# calculate loss
# reduce不同进程的loss
loss = criterion(predict, labels)
reduced_loss = reduce_tensor(loss.data)
train_epoch_loss += reduced_loss.item()
# optimize
optimizer.zero_grad()
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
optimizer.step()
scheduler.step()
# set progress bar
pbar.set_postfix(**{'loss (batch)': loss.item()})
pbar.update(images.shape[0])
train_epoch_loss /= (batch_idx + 1)
# eval
val_epoch_loss, dice, iou = eval_net(net, criterion, val_loader, device, len(val_dataset))
# TensorBoard
if args.local_rank == 0:
writer.add_scalars('Loss/training', {
'train_loss': train_epoch_loss,
'val_loss': val_epoch_loss
}, epoch + 1)
writer.add_scalars('Metrics/validation', {
'dice': dice,
'iou': iou
}, epoch + 1)
writer.add_images('images', images[:, :, 0, :, :], epoch + 1)
writer.add_images('Label/ground_truth', labels[:, :, 0, :, :], epoch + 1)
writer.add_images('Label/predict', torch.sigmoid(predict[:, :, 0, :, :]) > 0.5, epoch + 1)
if args.local_rank == 0:
torch.save(net, f'unet3d-epoch{epoch + 1}.pth')
def reduce_tensor(tensor: torch.Tensor) -> torch.Tensor:
rt = tensor.clone()
distributed.all_reduce(rt, op=distributed.reduce_op.SUM)
rt /= distributed.get_world_size()#进程数
return rt
if __name__ == '__main__':
main()
7 单机多卡正确打开方式Horovod
兼容TensorFlow、Keras和PyTorch机器学习框架。 使用Ring-AllReduce算法,对比Parameter Server算法,有着无需等待,负载均衡的优点。 实现简单,五分钟包教包会。(划重点)
import tensorflow as tf
import horovod.tensorflow as hvd
# 1. 初始化horovod
hvd.init()
# 2. 给当前进程分配对应的gpu,local_rank()返回的是当前是第几个进程
config = tf.ConfigProto()
config.gpu_options.visible_device_list = str(hvd.local_rank())
# 3. Scale学习率,封装优化器
opt = tf.train.AdagradOptimizer(0.01 * hvd.size())
opt = hvd.DistributedOptimizer(opt)
# 4. 定义初始化的时候广播参数的hook,这个是为了在一开始的时候同步各个gpu之间的参数
hooks = [hvd.BroadcastGlobalVariablesHook(0)]
# 搭建model,定义loss
loss = ...
train_op = opt.minimize(loss)
# 5. 只保存一份ckpt就行
checkpoint_dir = '/tmp/train_logs' if hvd.rank() == 0 else None
# 7. 用MonitoredTrainingSession实现初始化,读写ckpt
with tf.train.MonitoredTrainingSession(checkpoint_dir=checkpoint_dir,
config=config,
hooks=hooks) as mon_sess:
while not mon_sess.should_stop():
# Perform synchronous training.
mon_sess.run(train_op)
tensorflow_mnist.py:https://github.com/horovod/horovod/blob/master/examples/tensorflow_mnist.pyCUDA_VISIBLE_DEVICES=6,7 horovodrun -np 2 -H localhost:2 python tensorflow_mnist.py
-np指的是进程的数量。[1,0] :INFO:tensorflow:loss = 0.13126025, step = 300 (0.191 sec)
[1,1]:INFO:tensorflow:loss = 0.01396352, step = 310 (0.177 sec)
[1,0]:INFO:tensorflow:loss = 0.063738815, step = 310 (0.182 sec)
[1,1]:INFO:tensorflow:loss = 0.044452004, step = 320 (0.215 sec)
[1,0]:INFO:tensorflow:loss = 0.028987963, step = 320 (0.212 sec)
[1,0]:INFO:tensorflow:loss = 0.09094897, step = 330 (0.206 sec)
[1,1]:INFO:tensorflow:loss = 0.11366991, step = 330 (0.210 sec)
[1,0]:INFO:tensorflow:loss = 0.08559138, step = 340 (0.200 sec)
[1,1]:INFO:tensorflow:loss = 0.037002128, step = 340 (0.201 sec)
[1,0]:INFO:tensorflow:loss = 0.15422738, step = 350 (0.181 sec)
[1,1]:INFO:tensorflow:loss = 0.06424393, step = 350 (0.179 sec)
PyTorch
DP和DDP了。import torch
import horovod.torch as hvd
# 1. 初始化horovod
hvd.init()
# 2. 给当前进程分配对应的gpu,local_rank()返回的是当前是第几个进程
torch.cuda.set_device(hvd.local_rank())
# Define dataset...
train_dataset = ...
# 3. 用DistributedSampler给各个worker分数据
train_sampler = torch.utils.data.distributed.DistributedSampler(
train_dataset, num_replicas=hvd.size(), rank=hvd.rank())
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=..., sampler=train_sampler)
# Build model...
model = ...
model.cuda()
# 4. 封装优化器
optimizer = optim.SGD(model.parameters())
optimizer = hvd.DistributedOptimizer(optimizer, named_parameters=model.named_parameters())
# 5. 初始化的时候广播参数,这个是为了在一开始的时候同步各个gpu之间的参数
hvd.broadcast_parameters(model.state_dict(), root_rank=0)
# 训练
for epoch in range(100):
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % args.log_interval == 0:
print('Train Epoch: {} [{}/{}]\tLoss: {}'.format(
epoch, batch_idx * len(data), len(train_sampler), loss.item()))
8 把踩过的一些坑和解决办法列举在这,以避免大家以后重复踩坑
往期精彩:
喜欢您就点个在看!
评论