
PyTorch混合精度训练:每个人必须要知道的事情
 点蓝色字关注“机器学习算法工程师”
点蓝色字关注“机器学习算法工程师”
设为星标,干货直达!
现代神经网络的有效训练通常依赖于使用较低精度的数据类型。在A100 GPU 上,采用float16的矩阵乘法和卷积的峰值性能要比float32快 16 倍。由于 float16 和 bfloat16 数据类型的大小只有 float32 的一半,因此它们可以将带宽受限内核的性能提高一倍,并减少训练网络所需的内存,从而允许更大的模型、更大的批次或更大的输入。使用像 torch.amp(Automated Mixed Precision)这样的模块可以轻松获得较低精度数据类型的速度和内存使用优势,同时保持网络的收敛行为。
更快和使用更少的内存总是有利的——深度学习从业者可以测试更多的模型架构和超参数,并且可以训练更大、更强大的模型。训练非常大的模型,例如 Narayanan 等人描述的模型(https://arxiv.org/pdf/2104.04473.pdf)和布朗等人提出的模型(GPT-3,https://arxiv.org/pdf/2005.14165.pdf,即使使用专家手写优化也需要数以千计的 GPU 进行训练),在不使用混合精度的情况下是不可行的。
我们之前的文章(https://pytorch.org/blog/accelerating-training-on-nvidia-gpus-with-pytorch-automatic-mixed-precision/,https://docs.nvidia.com/deeplearning/performance/mixed-precision-training/index.html,https://developer.nvidia.com/automatic-mixed-precision)讨论过混合精度技术,如果您不熟悉混合精度,这篇博文是对这些技术的总结和介绍。
混合精度训练实践
混合精度训练技术——使用较低精度的 float16 或 bfloat16 数据类型以及 float32 数据类型——具有广泛的适用性和有效性。请参阅图 1 以了解以混合精度成功训练的模型结构(包括图像,语音以及文本等各个领域),图 2 和图 3 是使用 torch.amp 的示例加速对比。
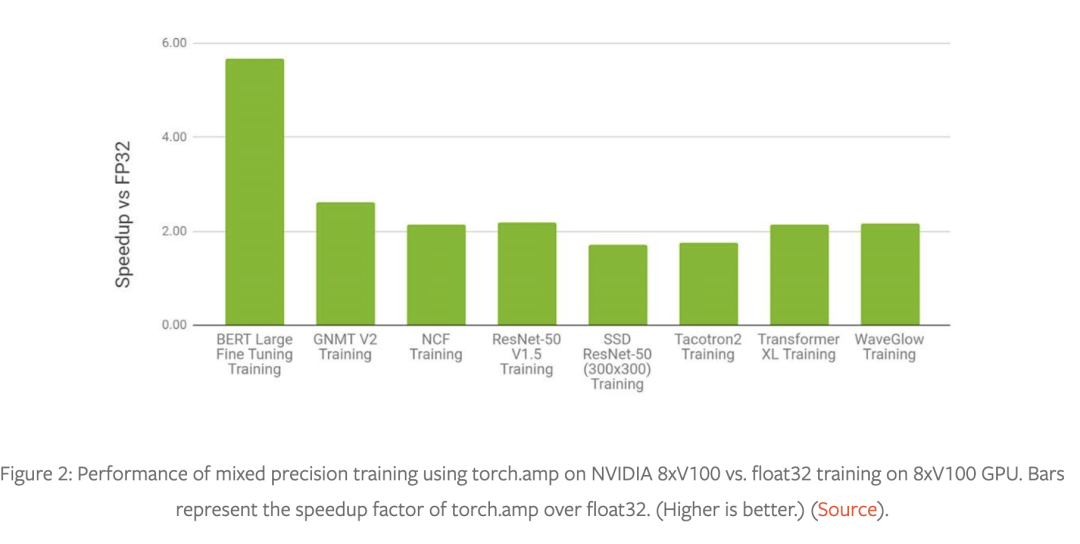
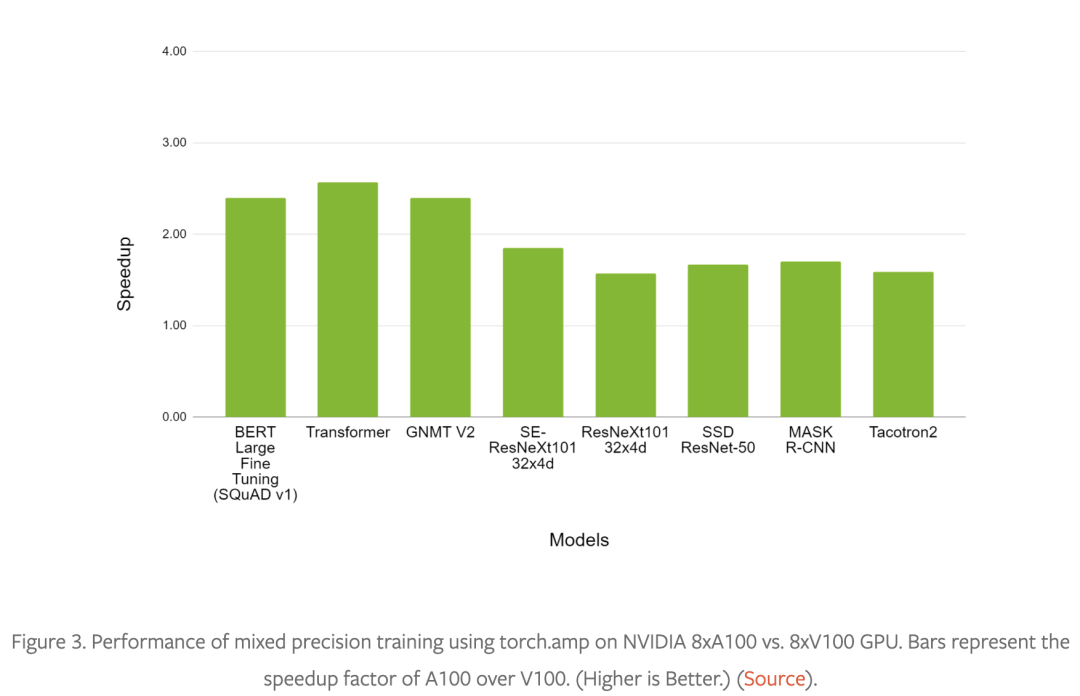
有关更多示例混合精度工作负载,请参阅 NVIDIA 深度学习示例存储库(https://github.com/NVIDIA/DeepLearningExamples)。
在 3D 医学图像分析、凝视估计、视频合成、条件 GAN 和卷积 LSTM 中可以看到类似的性能图表。黄等人的对比实验(https://pytorch.org/blog/accelerating-training-on-nvidia-gpus-with-pytorch-automatic-mixed-precision/)表明混合精度训练在 V100 GPU 上比 float32 快 1.5 到 5.5 倍,在 A100 GPU 上可以再快 1.3 到 2.5 倍。在非常大的网络上,对混合精度的需求更加明显。https://arxiv.org/pdf/2104.04473.pdf这个报告称在 1024 个 A100 GPU(批量大小为 1536)上训练 GPT-3 175B 需要 34 天,但使用 float32 估计需要一年多的时间!
使用torch.amp进行混合精度训练
Torch.amp 在 PyTorch 1.6 中引入,使用 float16 或 bfloat16 类型可以轻松利用混合精度训练。有关更多详细信息,请参阅此博客文章(https://pytorch.org/blog/accelerating-training-on-nvidia-gpus-with-pytorch-automatic-mixed-precision/)、教程(https://pytorch.org/tutorials/recipes/recipes/amp_recipe.html)和文档(https://pytorch.org/docs/master/amp.html)。下面显示了将具有渐变缩放功能的 AMP 应用到网络的示例。
import torch
# Creates once at the beginning of training
scaler = torch.cuda.amp.GradScaler()
for data, label in data_iter:
optimizer.zero_grad()
# Casts operations to mixed precision
with torch.amp.autocast(device_type=“cuda”, dtype=torch.float16):
loss = model(data)
# Scales the loss, and calls backward()
# to create scaled gradients
scaler.scale(loss).backward()
# Unscales gradients and calls
# or skips optimizer.step()
scaler.step(optimizer)
# Updates the scale for next iteration
scaler.update()
选择正确的方法
使用 float16 或 bfloat16 的开箱即用混合精度训练可有效加速许多深度学习模型的收敛,但某些模型可能需要更仔细的数值精度管理。以下是一些选项:
完整的 float32 精度。默认情况下,浮点张量和模块在 PyTorch 中以 float32 精度创建,但这是一个历史性的产物,不能代表训练大多数现代深度学习网络,网络很少需要这么高的数值精度。
启用 TensorFloat32 (TF32) 模式。在 Ampere 和更高版本的 CUDA 设备上,矩阵乘法和卷积可以使用 TensorFloat32 (TF32) 模式进行更快但精度稍低的计算。有关更多详细信息,请参阅使用 NVIDIA TF32 Tensor Cores 博客文章(https://developer.nvidia.com/blog/accelerating-ai-training-with-tf32-tensor-cores/)加速 AI 训练。默认情况下,PyTorch 为卷积启用 TF32 模式,但不为矩阵乘法启用,除非网络需要完整的 float32 精度,否则我们建议也为矩阵乘法启用此设置(有关如何执行此操作,请参阅此处的文档:https://pytorch.org/docs/master/generated/torch.set_float32_matmul_precision)。它可以显着加快计算速度,而数值精度的损失通常可以忽略不计。
将 torch.amp 与 bfloat16 或 float16 一起使用。这两种低精度浮点数据类型通常都比较快,但有些网络可能只收敛于其中一个。如果网络需要更高的精度,则可能需要使用 float16,如果网络需要更大的动态范围,则可能需要使用 bfloat16,其动态范围等于 float32。例如,如果观察到溢出,那么我们建议尝试 bfloat16。
还有比这里介绍的更高级的选项,例如仅对模型的一部分使用 torch.amp 的自动铸造,或直接管理混合精度。这些主题在很大程度上超出了本博文的范围,但请参阅下面的“最佳实践”部分。
最佳实践
我们强烈建议在训练网络时尽可能将混合精度与 torch.amp 或 TF32 模式(在 Ampere 和更高版本的 CUDA 设备上)结合使用。但是,如果其中一种方法不起作用,我们建议以下方法:
高性能计算 (HPC) 应用程序、回归任务和生成网络可能只需要完整的 float32 IEEE 精度即可按预期收敛。
尝试有选择地应用 torch.amp。特别是,我们建议首先在从 torch.linalg 模块执行操作的区域或在进行预处理或后处理时禁用它。这些操作通常特别敏感。请注意,TF32 模式是一个全局开关,不能在网络区域有选择地使用。首先启用 TF32 以检查网络运营商是否对该模式敏感,否则禁用它。
如果您在使用 torch.amp 时遇到类型不匹配,我们不建议您在开始时插入手动转换。此错误表明网络出现问题,通常值得首先调查。
通过实验确定您的网络是否对格式的范围和/或精度敏感。例如,在 float16 中微调 bfloat16 预训练模型很容易在 float16 中遇到范围问题,因为在 bfloat16 中训练的范围可能很大,因此如果模型是在 bfloat16 中训练的,用户应该坚持使用 bfloat16 微调。
有关更多详细信息,请参阅 AMP 教程(https://pytorch.org/tutorials/recipes/recipes/amp_recipe.html),使用 Tensor Cores 训练神经网络(https://nvlabs.github.io/eccv2020-mixed-precision-tutorial/),并参阅 PyTorch 开发讨论中的“浮点精度的更多深入细节”一文(https://dev-discuss.pytorch.org/t/more-in-depth-details-of-floating-point-precision/654)。
总结
混合精度训练是在现代硬件上训练深度学习模型的重要工具,随着较低精度操作和 float32 之间的性能差距在新硬件上不断扩大,它在未来将变得更加重要,如图 5 所示。
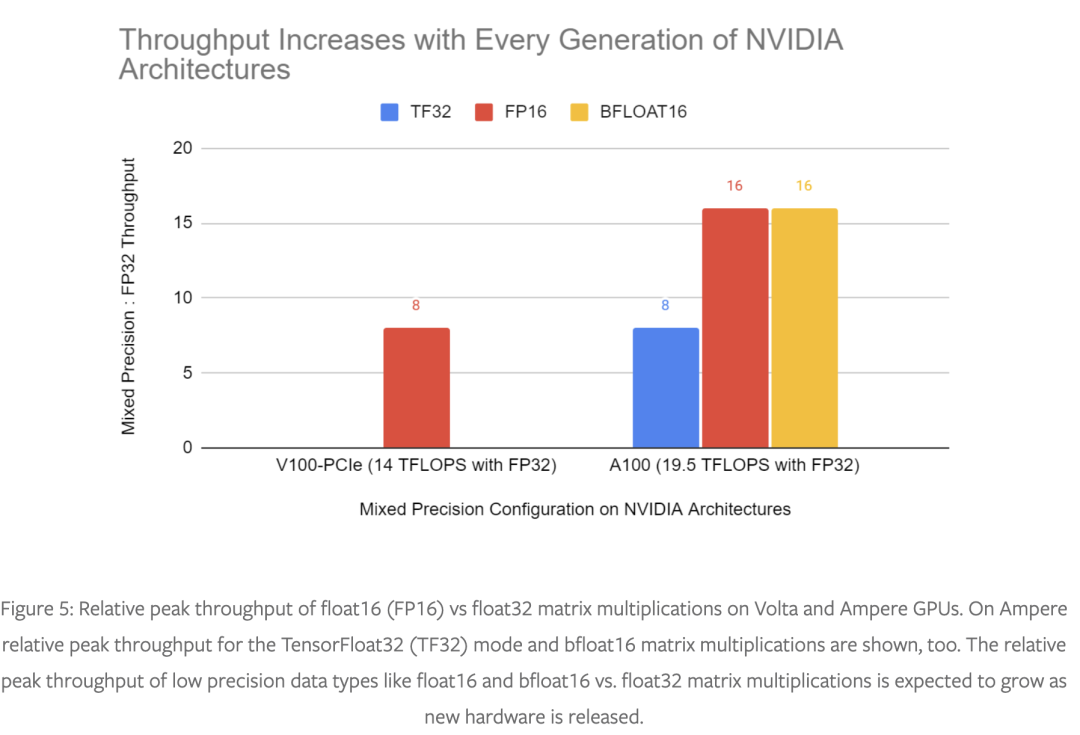
PyTorch 的 torch.amp 模块可以轻松开始使用混合精度,我们强烈建议使用它来加快训练速度并减少内存使用量。torch.amp 支持 float16 和 bfloat16 混合精度。仍然有一些网络很难以混合精度进行训练,对于这些网络,我们建议在 Ampere 和更高版本的 CUDA 硬件上尝试 TF32 加速矩阵乘法。网络很少对精度如此敏感,以至于每次操作都需要完整的 float32 精度。
本文翻译自:https://pytorch.org/blog/what-every-user-should-know-about-mixed-precision-training-in-pytorch/
推荐阅读
辅助模块加速收敛,精度大幅提升!移动端实时的NanoDet-Plus来了!
机器学习算法工程师
一个用心的公众号
