
扛鼎之作!Twitter 图机器学习大牛发表160页论文:以几何学视角统一深度学习

导语:近日,帝国理工学院教授、Twitter 首席科学家 Michael Bronstein 发表了一篇长达160页的论文(或者说书籍),试图从对称性和不变性的视角从几何上统一CNNs、GNNs、LSTMs、Transformers等典型架构,构建深度学习的“爱尔兰根纲领”!本文是Michael Bronstein对论文的精华介绍。
「几何深度学习」试图从对称性和不变性的视角从几何上统一多种机器学习问题。这些原理不仅为卷积神经网络的性能突破和最近大热的图神经网络奠定了基础,也提供了一种原理性的方法来构建针对具体问题的新型归纳偏置。

1872 年 10 月,位于德国巴伐利亚城的埃尔兰根大学任命了一位年轻的教授。按照惯例,这位教授需要提出一项初始研究项目,而他提出的项目名称似乎有些乏味——「近期几何学研究的比较综述」。这位教授就是年仅 23 岁的 Felix Klein,他的这项初始工作就是数学史上鼎鼎大名的「爱尔兰根纲领」。

19 世纪,几何学蓬勃发展,该领域的学者硕果累累。在欧氏几何提出近两千年后,彭色列首次构建了射影几何,高斯、波尔约、罗巴切夫斯基提出了双曲几何,黎曼提出了椭圆几何,这说明我们可以建立一个由各种几何学组成的完整体系。然而,这些方向迅速分化为各个独立的研究领域。于是,那个时期的许多数学家纷纷思考,不同的几何学分支相互之间有何关系,究竟应该如何「定义」几何?
Klein 突破性地提出将几何定义为对不变性的研究,即研究在某类变换下保持不变的结构(对称性)。Klein 通过群论形式化定义了这种变换,并且使用群及其子群的层次对由它们产生的不同几何进行分类。因此,刚性运动群产生了传统的欧氏几何,而仿射或射影变换分别产生了仿射几何和射影几何。值得一提的是,爱尔兰根纲领仅仅局限于齐次空间,最初并不适用于黎曼几何。
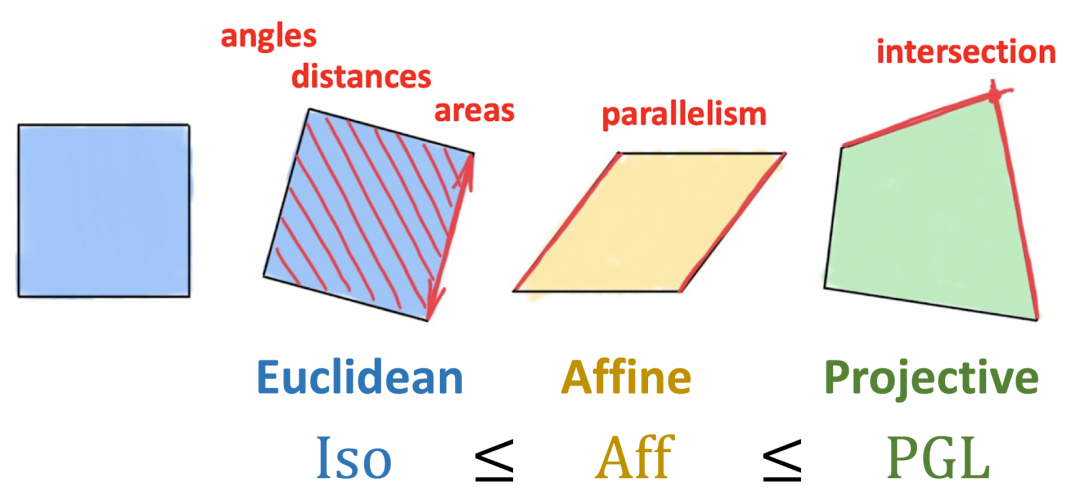
图 2:Klein 的爱尔兰根纲领将几何学定义为研究在某类变换下保持不变的性质。我们通过保持面积、距离、角度、平行结构不变的刚性变换(建模为等距群)定义 2 维欧氏几何。仿射变换将保持平行结构,但并不能保证距离或面积不变。射影变换的不变性最弱,只保持交点和交比不变,对应于以上三种变换中最大的群。因此,Klein 认为射影几何是最为通用的。
爱尔兰根纲领对几何学和数学的影响是极为深远的,其影响也延伸到了其它领域(尤其是物理学),对对称性的思考使我们可以从第一性原理出发导出守恒定律(例如,举世闻名的「诺特定理」)。数十年后,人们通过规范不变性的概念(于 1954 年由杨振宁和米尔斯提出的广义形式)证明这一基本原理成功地统一了除引力之外的所有自然基本力。这就是所谓的标准模型,它描述了我们目前所知道的所有物理知识。
正如诺贝尔奖获得者、物理学家 Philip Anderson 所言:
“it is only slightly overstating the case to say that physics is the study of symmetry.’’
稍显夸张地说,物理学就是对对称性的研究。
我们认为,当下的深度(表征)学习研究领域的情况与 19 世纪的几何学研究是相似的:一方面,深度学习在过去十年间为数据科学领域带来了一场革命,它使许多之前被认为无法实现的任务成为了可能——无论是计算机视觉、语音识别、自然语言翻译或围棋游戏中都是如此。另一方面,我们现在拥有了各种适用于不同数据的神经网络架构,但是却很少发展出统一的原理。因此,我们很难理解不同方法之间的关系,这不可避免地使我们对相同的概念进行重复开发。

图注:现代的深度学习——有各种各样的架构,但是缺乏统一的原理。
与 Klein 的爱尔兰根纲领相类似,Michael Bronstein 等人在论文「Geometric deep learning: going beyond Euclidean data」(https://arxiv.org/abs/1611.08097)中引入了「几何深度学习」的概念,作为近期从几何学的角度将机器学习统一起来的尝试的总称。这样做有两个目的:首先,它提出了一个通用的数学框架,从而推导出当下最成功的神经网络架构;其次,它给出了一种有建设性的过程,以一种有条理的方法构建未来的框架。

图注:多层感知机是一种只包含一个隐层的通用近似器。他们可以表征阶跃函数的组合,从而以任意的精度近似任意的连续函数。
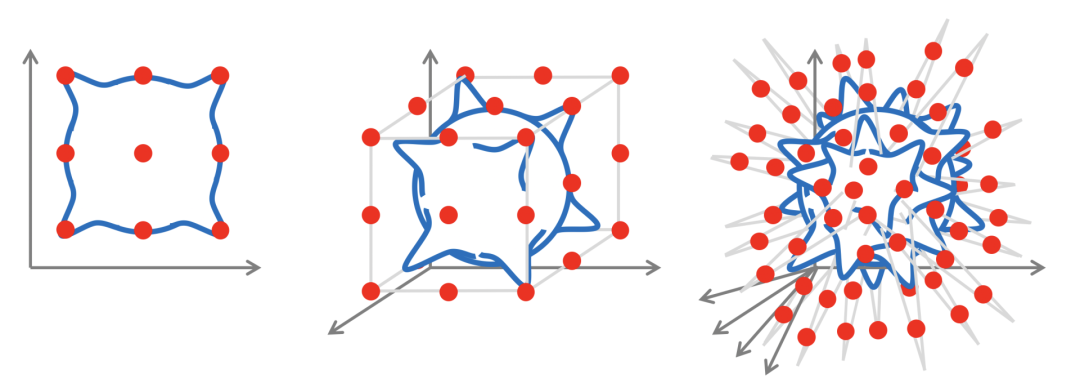
图注:维数诅咒示意图。对于一个由处于 d 维单位超立方体的象限中的高斯核组成的连续函数(蓝色),如果我们希望以 ε 的误差近似一个李普希兹连续的函数,则需要 𝒪(1/εᵈ) 的样本(红色点)。


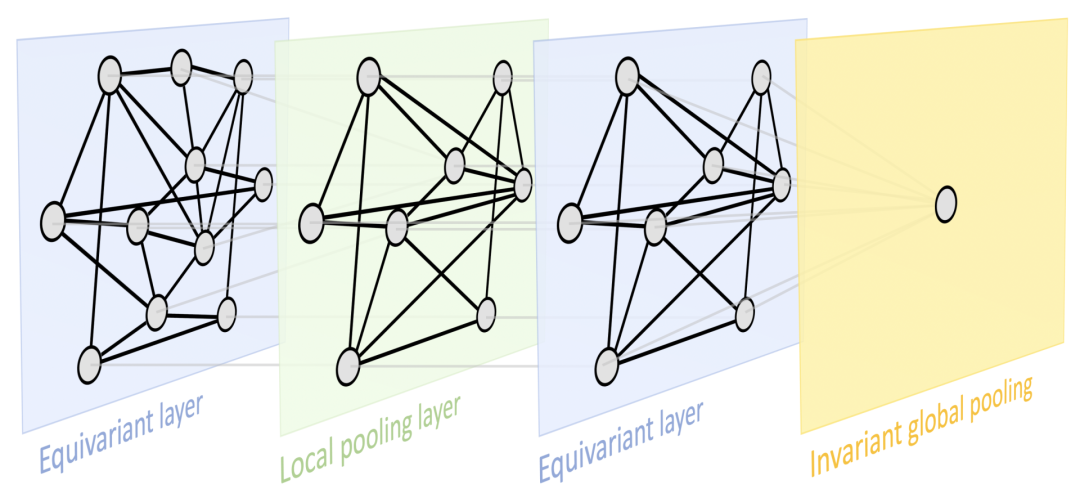
图注:展示了一种非常通用的设计,可以应用于不同类型的几何结构(例如,网格,具有全局变换群的齐次空间,图(集合也是其中一种特例)和流形,这些结构具有全局等距不变性和局部规范对称性。基于上述原理,我们实现了目前深度学习领域中的一些最流行的架构:由平移对称导出的卷积网络(CNN),由置换不变性导出的图神经网络、DeepSets 和 Transformer,由时间扭曲不变性导出的门控 RNN(例如 LSTM 网络),以及由规范对称性导出的计算机图形和视觉中使用的 Intrinsic Mesh CNN。
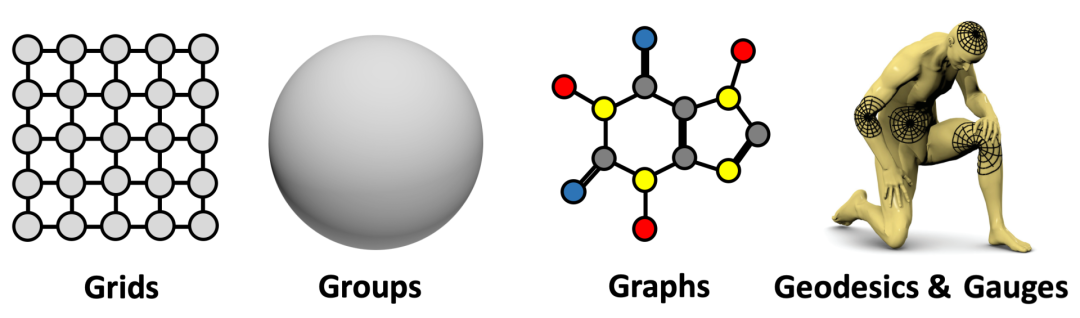
最后还要重点强调的是,对称性在历史上是众多科学领域中的一个关键概念。在机器学习研究社区中,对称性的重要性早已得到普遍认可,特别是在模式识别和计算机视觉的应用中,关于等变特征检测(Equivariant Feature Detection)的研究最早可以追溯到shun'ichi Amari 和Reiner Lenz 等人的工作。在神经网络的研究历史中,Marvin Minsky 和 Seymour Papert 提出的感知器群不变性定理(The Group Invariance Theorem)对(单层)感知器学习不变性的能力提出了基本限制。这是研究多层架构的主要动机之一,并最终催生了深度学习。
相关链接:
https://towardsdatascience.com/geometric-foundations-of-deep-learning-94cdd45b451d
https://arxiv.org/pdf/2104.13478.pdf
