
CV未来在这68张图上?Google Brain深扒ImageNet:顶级模型全都预测失败
转自:新智元
过去的十年里,ImageNet基本就是计算机视觉领域的「晴雨表」,看准确率有没有提升,就知道有没有新技术问世。
「刷榜」一直是模型创新的原动力,把模型Top-1准确率推动到90%+,比人类还高。

但ImageNet数据集是否真的像我们想象中的那么有用?
很多论文都曾对ImageNet发出质疑,比如数据的覆盖度、偏见问题、标签是否完善等等。
其中最重要的是,模型90%的准确率是否真的准确?
最近Google Brain团队和加州大学伯克利分校的研究人员重新审视了几个sota模型的预测结果,发现模型真正的准确率还可能被低估了!

论文链接:https://arxiv.org/pdf/2205.04596.pdf
研究人员通过对一些顶级模型所犯的每一个错误进行人工审查和分类,以便深入了解基准数据集的长尾错误。
其中主要关注ImageNet的多标签子集评估,最好的模型已经能达到97%的Top-1的准确率。
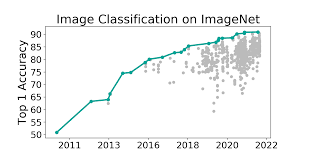
这项研究的分析结果显示,将近一半的所谓的预测错误根本就不是错误,并且还在图片中发现了新的多标签,也就是说,如果没有人工审查过预测结果,这些模型的性能可能都是被「低估」的!
不熟练的众包数据标注员往往会把数据标注错误,在很大程度上也影响了模型准确率的真实性。
为了校准ImageNet数据集,促进未来的良性进展,研究人员在文中提供了一个更新版的多标签评估集,并把sota模型预测存在明显错误的68个例子组合为一个新数据集ImageNet-Major,以方便未来CV研究者攻克这些bad case
还上「技术债」
从文章的标题「什么时候面团成了百吉饼?」就可以看出作者主要关注ImageNet里的标签问题,这也属于是历史遗留问题了。
下图是一个非常典型的标签歧义例子,图片里的标签为「面团」,模型的预测结果为「百吉饼」,错了吗?

这个模型理论上来说并没有预测错误,因为面团正在烤,马上就要成百吉饼了,所以既是面团又是百吉饼。
可以见得模型实际上已经能够预测到这个面团「即将成为」百吉饼,但在准确率上却没有拿到这一分。
实际上,以标准ImageNet数据集的分类任务作为评价标准,缺乏多标签、标签噪声、未指定的类别等问题都在所难免。

从负责识别此类对象的众包标注员的角度来看,这是一个语义甚至是哲学上的难题,只能通过多标签来解决,所以在ImageNet的衍生数据集中主要改善的就是标签问题。
距ImageNet成立已经过了16年,当时的标注人员、模型开发者对数据的理解肯定不如今天丰富,而ImageNet又是早期的大容量、标注相对良好的数据集,所以ImageNet很自然而然地成了CV刷榜的标准。
但标注数据的预算显然不如开发模型来的多,所以标签问题的改善也成了一种技术债。
为了找出ImageNet中剩下的错误,研究人员使用了一个具有 30 亿参数的标准ViT-3B模型(能够达到 89.5% 的准确度),其中JFT-3B作为预训练模型,并在ImageNet-1K上进行了微调。
使用ImageNet2012_multilabel的数据集作为测试集的情况下,ViT-3B初步达到的准确率为96.3%,其中模型明显错误预测了676个图像,然后对这些例子进行深入研究。
在重新标注数据时,作者没有选择众包,而是组建了一个5名专家评审组成的小组进行标注,因为这类标注错误对于非专业人员来说很难识别出来。
比如图(a),普通的标注人员可能写一个「桌子」就过了,但实际上图片里还有很多其他物体,比如屏幕、显示器、马克杯等等。

图(b)的主体为两个人,但标签为picket fence(栅栏),显然也是不完善的,可能的标签还有领结、制服等等。
图(c)也是一个明显的例子,如果只标出来「非洲象」,那象牙可能就被忽视掉了。
图(d)的标签为lakeshore(湖岸),但标注成seashore(海滨)实际上也没毛病。
为了增加标注效率,研究者还开发了一个专用的工具,能够同时显示模型预测的类别、预测分数、标签和图像。
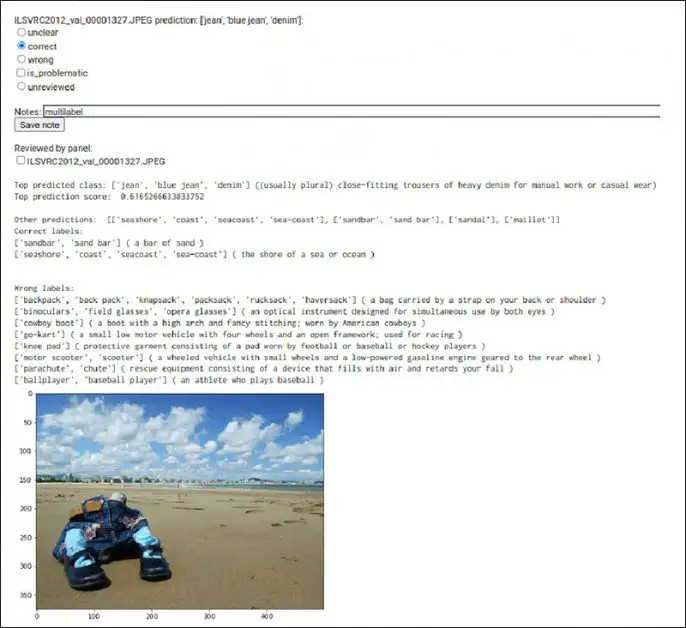
在某些情况下,专家组之间可能还存在标签的争议,这时候就把图片放到谷歌搜索里来辅助标注。
比如说有一个例子里,模型的预测结果里包含出租车,但图片里面除了「一点黄色」之外根本没有出租车的牌子。
这张图片的标注主要是通过谷歌图片搜索发现图像的背景是一个标志性的桥梁,然后研究人员定位到了图片所在的城市,对该城市中的出租车图像进行检索后,认可了这张图片里确实包含出租车而非一辆普通的汽车。并且从车牌的设计上进行对比,也验证了模型的预测是正确的。
在对研究的几个阶段发现的错误进行初步审查后,作者首先根据错误的严重程度将其分为两类:
1. 主要错误(Major):人类能够理解标签的含义,并且模型的预测和标签完全不沾边;
2. 次要错误(Minor):标签的可能是错误的或者不完善导致的预测错误。需要专家审查数据后进行纠正。

对于ViT-3B模型犯的155个主要错误,研究人员又找了其他三个模型共同预测来提高预测结果的多样性。
四个模型全都预测失败的主要错误有68个,然后分析了所有模型对这些例子的预测,并验证了它们没有一个是正确的新的多标签,即每个模型的预测结果确实都是主要错误。
这68个例子有几个共同特点,首先就是不同方式训练的sota模型都在这个子集上犯了错误、并且专家评审也认为预测结果完全和正确不沾边。
68张图像的数据集也足够小,方便后续研究者进行人工评估,如果未来攻克了这68个例子,那CV模型也许会取得新突破。
通过分析数据,研究者又将预测错误划分为四种类型:
1. 细粒度错误,其中预测的类别跟真实标签相似,但不完全相同;
2. 具有词表外(OOV)的细粒度,其中模型识别其类别正确但在 ImageNet 中不存在该对象的类别;
3. 虚假相关性,其中预测的标签是从图像的上下文中读取的;
4. 非原型,其中标签中的对象与预测标签相似、但并非完全一致。

在审查了原始 676 个错误后,研究人员发现其中298 个应该是正确的,或者可以确定原始标签是错误或有问题的。

总的来说,通过文章的研究结果可以得出四个结论:
1. 当一个大型、高精度模型做出其他模型没有的新预测时,大概其中50%都是正确的新多标签;
2. 更高精度的模型在类别和错误严重性之间没有表现出明显的相关性;
3. 如今SOTA模型在人工评估的多标签子集上的表现在很大程度上匹配或超过了最佳专家人类的表现;
4. 有噪音的训练数据和未指定的类别可能是限制有效衡量图像分类改进的一个因素。
或许图像标签问题还得等待自然语言处理技术来解决?
参考资料:
https://www.unite.ai/assessing-the-historical-accuracy-of-imagenet/
往期精彩: