
最后一届ImageNet冠军模型:SENet

作者:小小将
编辑:黄俊嘉
01
主体思路
对于CNN网络来说,其核心计算是卷积算子,其通过卷积核从输入特征图学习到新特征图。从本质上讲,卷积是对一个局部区域进行特征融合,这包括空间上(H和W维度)以及通道间(C维度)的特征融合。
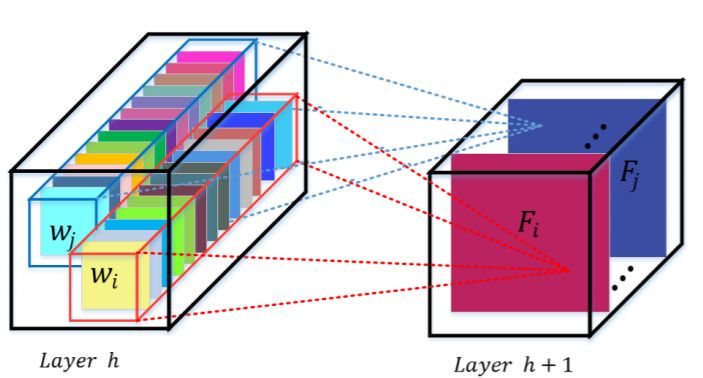
图1 CNN中的卷积操作
对于卷积操作,很大一部分工作是提高感受,即空间上融合更多特征融合,或者是提取多尺度空间信息,如Inception网络的多分支结构。对于channel维度的特征融合,卷积操作基本上默认对输入特征图的所有channel进行融合。而MobileNet网络中的组卷积(Group Convolution)和深度可分离卷积(Depthwise Separable Convolution)对channel进行分组也主要是为了使模型更加轻量级,减少计算量。而SENet网络的创新点在于关注channel之间的关系,希望模型可以自动学习到不同channel特征的重要程度。为此,SENet提出了Squeeze-and-Excitation (SE)模块,如下图所示:
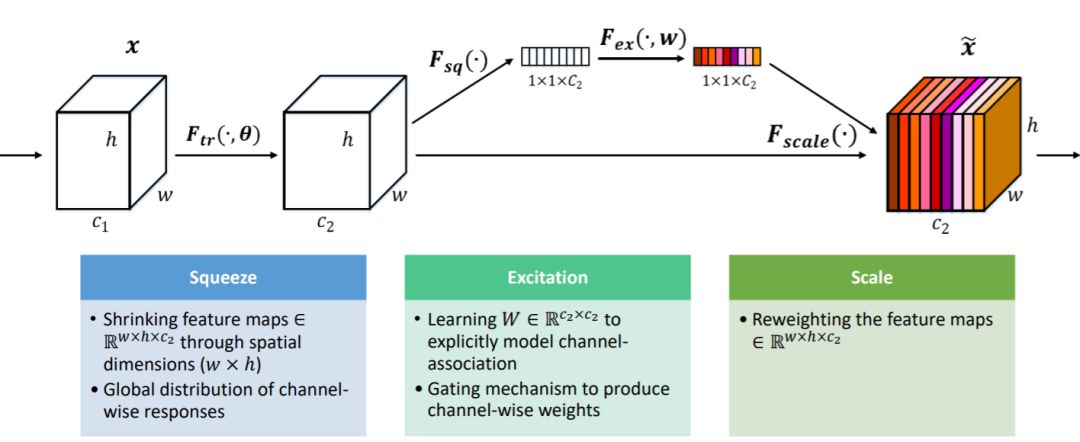
图2 Squeeze-and-Excitation (SE)模块
SE模块首先对卷积得到的特征图进行Squeeze操作,得到channel级的全局特征,然后对全局特征进行Excitation操作,学习各个channel间的关系,也得到不同channel的权重,最后乘以原来的特征图得到最终特征。本质上,SE模块是在channel维度上做attention或者gating操作,这种注意力机制让模型可以更加关注信息量最大的channel特征,而抑制那些不重要的channel特征。另外一点是SE模块是通用的,这意味着其可以嵌入到现有的网络架构中。
02
Squeeze-and-Excitation (SE) 模块
SE模块主要包括Squeeze和Excitation两个操作,可以适用于任何映射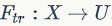 ,
,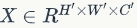 ,
,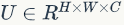 ,以卷积为例,卷积核为
,以卷积为例,卷积核为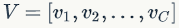 ,其中
,其中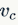 表示第c个卷积核。那么输出
表示第c个卷积核。那么输出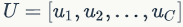 :
:
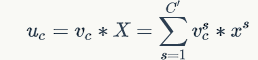
其中*代表卷积操作,而 代表一个3D卷积核,其输入一个channel上的空间特征,它学习特征空间关系,但是由于对各个channel的卷积结果做了sum,所以channel特征关系与卷积核学习到的空间关系混合在一起。而SE模块就是为了抽离这种混杂,使得模型直接学习到channel特征关系。
代表一个3D卷积核,其输入一个channel上的空间特征,它学习特征空间关系,但是由于对各个channel的卷积结果做了sum,所以channel特征关系与卷积核学习到的空间关系混合在一起。而SE模块就是为了抽离这种混杂,使得模型直接学习到channel特征关系。
Squeeze操作
由于卷积只是在一个局部空间内进行操作, 很难获得足够的信息来提取channel之间的关系,对于网络中前面的层这更严重,因为感受野比较小。为了,SENet提出Squeeze操作,将一个channel上整个空间特征编码为一个全局特征,采用global average pooling来实现(原则上也可以采用更复杂的聚合策略):
很难获得足够的信息来提取channel之间的关系,对于网络中前面的层这更严重,因为感受野比较小。为了,SENet提出Squeeze操作,将一个channel上整个空间特征编码为一个全局特征,采用global average pooling来实现(原则上也可以采用更复杂的聚合策略):
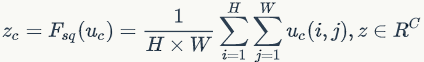
Excitation操作
Sequeeze操作得到了全局描述特征,我们接下来需要另外一种运算来抓取channel之间的关系。这个操作需要满足两个准则:首先要灵活,它要可以学习到各个channel之间的非线性关系;第二点是学习的关系不是互斥的,因为这里允许多channel特征,而不是one-hot形式。基于此,这里采用sigmoid形式的gating机制:
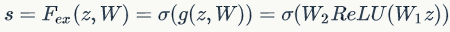
其中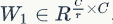 ,
, 。为了降低模型复杂度以及提升泛化能力,这里采用包含两个全连接层的bottleneck结构,其中第一个FC层起到降维的作用,降维系数为r是个超参数,然后采用ReLU激活。最后的FC层恢复原始的维度。
。为了降低模型复杂度以及提升泛化能力,这里采用包含两个全连接层的bottleneck结构,其中第一个FC层起到降维的作用,降维系数为r是个超参数,然后采用ReLU激活。最后的FC层恢复原始的维度。
最后将学习到的各个channel的激活值(sigmoid激活,值0~1)乘以U上的原始特征:
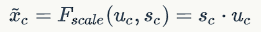
其实整个操作可以看成学习到了各个channel的权重系数,从而使得模型对各个channel的特征更有辨别能力,这应该也算一种attention机制。
03
SE模块在Inception和ResNet上的应用
SE模块的灵活性在于它可以直接应用现有的网络结构中。这里以Inception和ResNet为例。对于Inception网络,没有残差结构,这里对整个Inception模块应用SE模块。对于ResNet,SE模块嵌入到残差结构中的残差学习分支中。具体如下图所示:
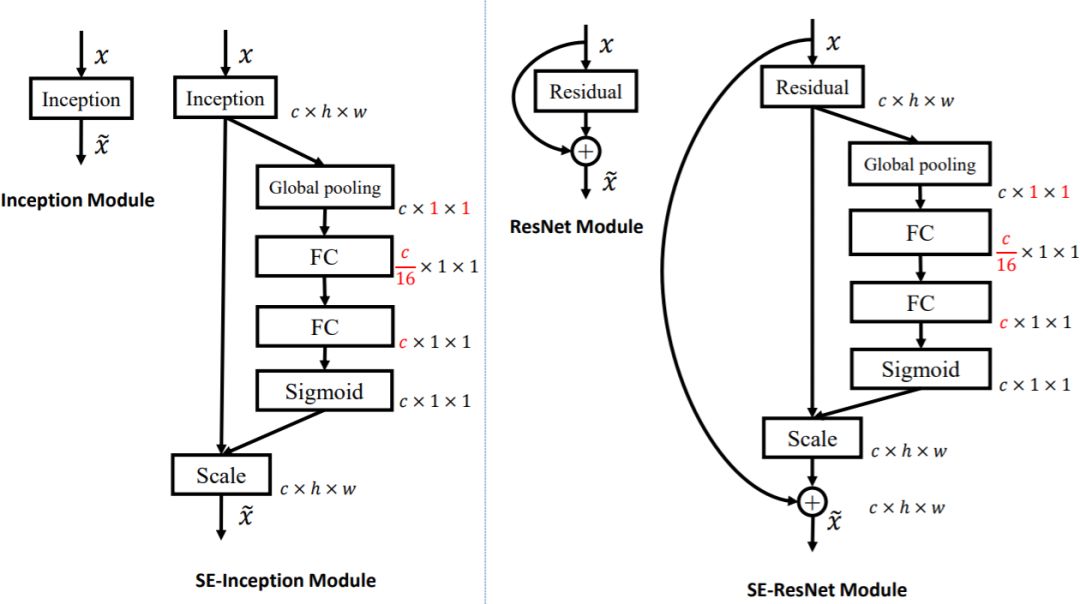
图3 加入SE模块的Inception和ResNet网络
同样地,SE模块也可以应用在其它网络结构,如ResNetXt,Inception-ResNet,MobileNet和ShuffleNet中。这里给出SE-ResNet-50和SE-ResNetXt-50的具体结构,如下表所示:
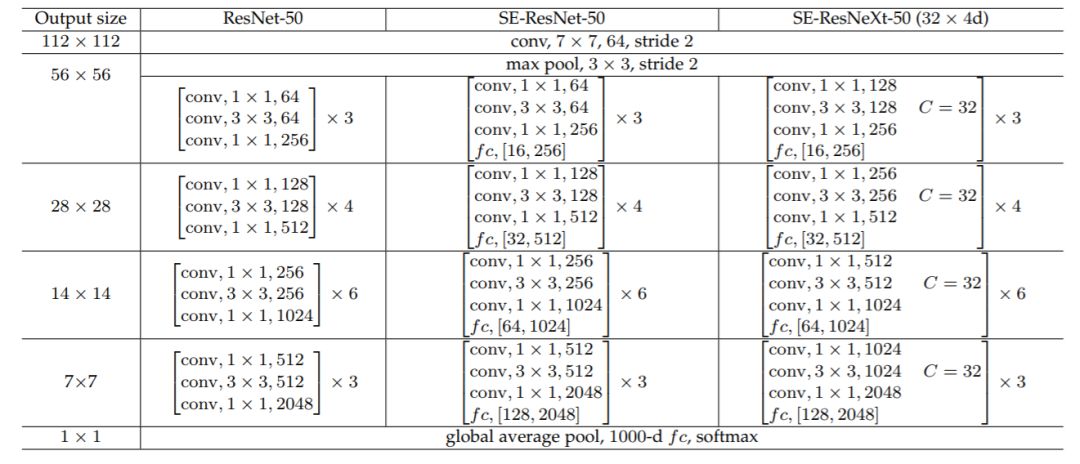
增加了SE模块后,模型参数以及计算量都会增加,这里以SE-ResNet-50为例,对于模型参数增加量为:
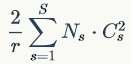
其中r为降维系数,S表示stage数量,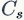 为第s个stage的通道数,
为第s个stage的通道数,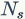 为第s个stage的重复block量。当r=16时,SE-ResNet-50只增加了约10%的参数量。但计算量(GFLOPS)却增加不到1%。
为第s个stage的重复block量。当r=16时,SE-ResNet-50只增加了约10%的参数量。但计算量(GFLOPS)却增加不到1%。
04
模型效果
SE模块很容易嵌入到其它网络中,作者为了验证SE模块的作用,在其它流行网络如ResNet和VGG中引入SE模块,测试其在ImageNet上的效果,如下表所示:
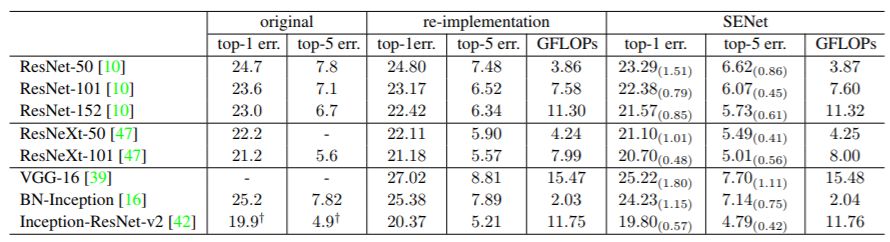
可以看到所有网络在加入SE模块后分类准确度均有一定的提升。此外,作者还测试了SE模块在轻量级网络MobileNet和ShuffleNet上的效果,如下表所示,可以看到也是有效果提升的。

最终作者采用了一系列的SENet进行集成,在ImageNet测试集上的top-5 error为2.251%,赢得了2017年竞赛的冠军。其中最关键的模型是SENet-154,其建立在ResNeXt模型基础上,效果如下表所示:
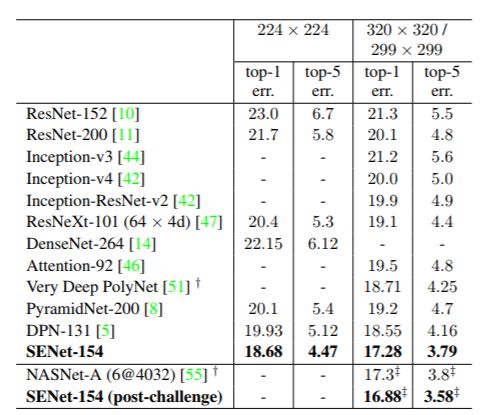
05
SE模块的实现
SE模块是非常简单的,实现起来也比较容易,这里给出PyTorch版本的实现(参考(https://github.com/moskomule/senet.pytorch)):
class SELayer(nn.Module):
def __init__(self, channel, reduction=16):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)对于SE-ResNet模型,只需要将SE模块加入到残差单元(应用在残差学习那一部分)就可以:
class SEBottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None, reduction=16):
super(SEBottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * 4)
self.relu = nn.ReLU(inplace=True)
self.se = SELayer(planes * 4, reduction)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out = self.se(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
06
小 结
SE模块主要为了提升模型对channel特征的敏感性,这个模块是轻量级的,而且可以应用在现有的网络结构中,只需要增加较少的计算量就可以带来性能的提升。另外最新的CVPR 2019有篇与SENet非常相似的网络SKNet([Selective Kernel Networks](https://arxiv.org/abs/1903.06586)),SKNet主要是提升模型对感受野的自适应能力,感兴趣可以深入看一下。
参考文献
1.[Squeeze-and-Excitation Networks](https://arxiv.org/abs/1709.01507)
2.[CVPR2017 WorkShop](http://image-net.org/challenges/talks_2017/SENet.pdf)

END
往期回顾之作者小小将
【7】深入理解TensorFlow中的tf.metrics算子
机器学习算法工程师
一个用心的公众号
进群,学习,得帮助
你的关注,我们的热度,
我们一定给你学习最大的帮助