“四月了,毕业论文写完了吗?”

论文关乎毕业,拿奖金、评职称、争取资金、争取项目,可谓是每个读书人的必经之路。
小象君在大学时候,经常看到这样的状况
写论文前:小意思!
前几天后台留言,哭诉找文献找不到的同学越来越多,今天就通过良同学的案例,给大家介绍一个超高效率解决论文的办法。
使用Python成效:毕业论文快速找到了合适且全面的文献 ,对论文引用以及整体架构上,有非常大的帮助。

良同学是一位完全零基础的经济学本科生,初期刚学的时候他甚至连中英文标点都要检查好久,自己运行很多次也搞不定,报名Python也是因为自己感兴趣,想多增加一个技能。

不过他还是在众多打游戏睡觉的室友中鹤立鸡群,坚持每天学习,不管平时上课以及校园活动再忙再累,都顺利完成了语法课,虽然进度很慢,不过后续事实证明良同学基础非常的牢固。有一次助教问他为什么想学Python,得到的回答让老师们感动之余也充满教学的动力!“早就听说Python的神奇,趁着没毕业还有时间,我想多体验一下这门‘属于未来的技术’,之前自学很慢,这次学习因为有各位老师的耐心解答,学起来轻松多了。”不过最近他进度的确落下很多,问问题也不那么勤快了,经过询问才知道是论文查文献太浪费时间,因为进度还没到爬虫,每天泡在图书馆,研究专业领域,根本没时间学课外课程。对此,我们专门针对各大论文文献网站,写出了一份独一无二,超实用的代码,帮助毕业生解放劳动力!很多同学看完之后都反馈代码超级好用!尤其毕业季里相当于雪中送炭。

良同学的事迹到这里就结束了,让我们来看下这个任务是如何用Python实现的要获取的信息:论文名,论文作者,论文来源,发表时间,隶属于的数据库,被索引的次数,下载次数和下载链接。第一步:这里利用知网的专业检索功能,界面如下所示,比如我们搜索主题是:股票。关键字是:A股的论文。搜索界面如下:
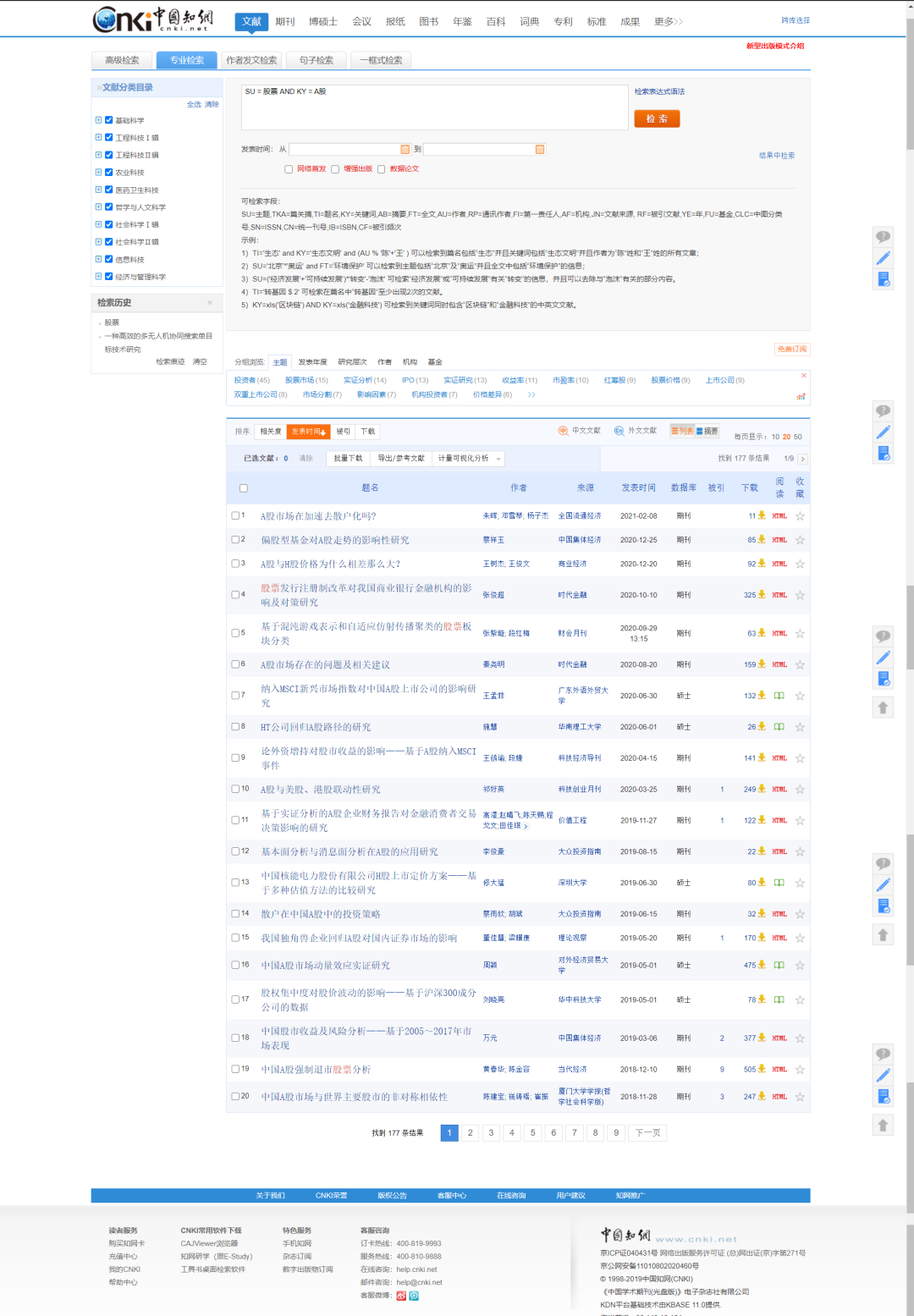
因为页数较多,这里使用selenium库进行爬取,它能方便的帮我们提取到网页中的对应元素,而且可以模拟鼠标的点击下一页的操作,方便对下一页的内容爬取。第二步:利用提供的chrome驱动的无界面模式,利用selenium库模拟chrome的操作实现爬取。针对一页具体的数据,这里使用selenium和lxml相结合的方式对网页进行解析,定位到需要爬取的数据。为了防止程序抛出异常,代码中使用了多处try语句。第三步:由于涉及到多页爬取,为了防止爬取太频繁被知网发现,需要每爬取一页让程序自动休眠10秒左右的时间(时间根据时间情况调节即可)第四步:为了便于代码的易读性,构建了一个ways.py的工具,其功能是从外部读取since.xls文件,可以通过该文件自定义需要爬取哪些内容,比如:主题、关键词、作者、机构、基金等,这里利用到了操作excel文件的xlrd库。第五步:把爬取到的内容利用csv库,写入到指定的result.csv文件中。按照这个逻辑完成代码之后,爬取完成,以下为部分代码展示:

我们来看下结果
能接触到Python是我大学期间最幸运的事,通过这次论文我才知道,我以前对Python的理解太虚无,总想着用它去创造改变未来的事情,没想到,它的实用近在眼前,就拿论文爬取这件事来讲,通过简单的调取库就可以实现爬取海量资源,就可以节省我大量时间,还可以通过数据分析洞察行业的信息,对于学经济的我来说,仿佛打开另一个世界的大门。现在我已经把python爬虫和数据分析都学完了,带着目标和解决问题的心态学习甚至解决了我的拖延症,新知识不断涌入头脑的感觉太棒了!


 下载APP
下载APP