
十分钟理解Transformer
点击下方卡片,关注“新机器视觉”公众号
视觉/图像重磅干货,第一时间送达
来源|知乎—Jason 报道|人工智能前沿讲习
地址|https://zhuanlan.zhihu.com/p/82312421
那什么是transformer呢?

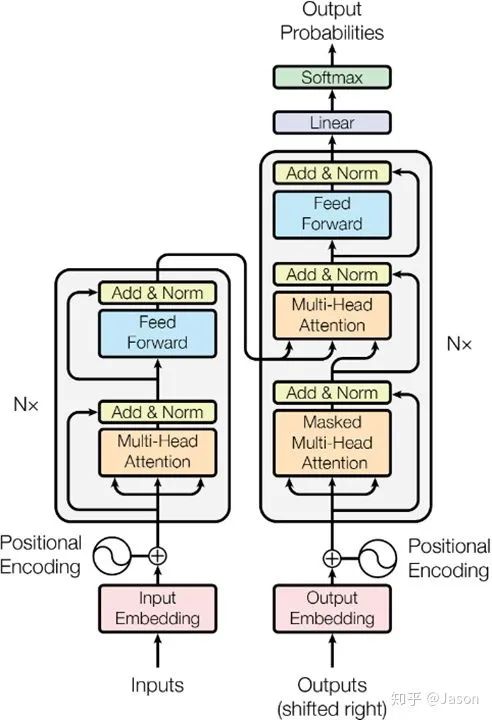
那么在这个黑盒子里面都有什么呢?
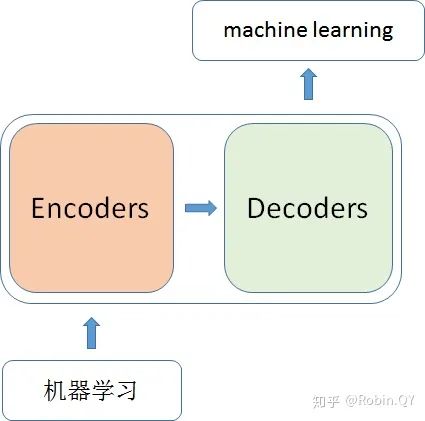
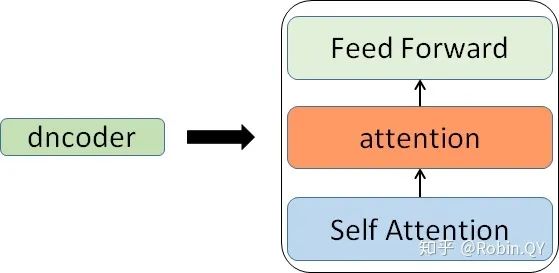
那么编码器和解码器里边又都是些什么呢?
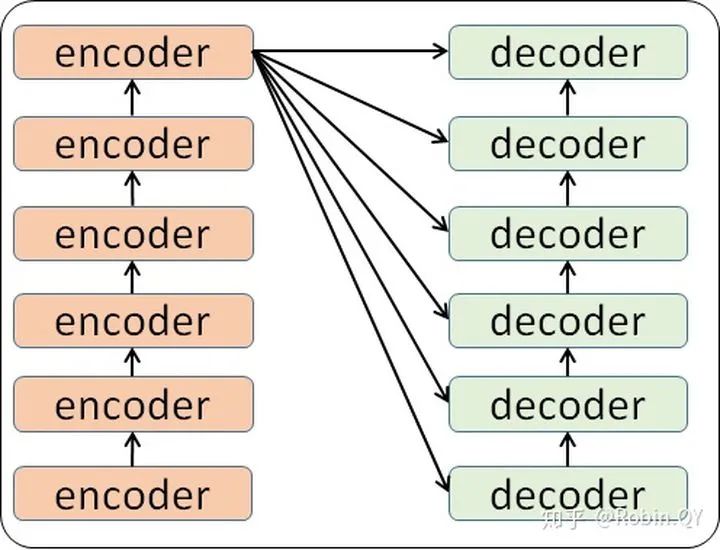
那么你可能又该问了,那每一个小编码器里边又是什么呢?
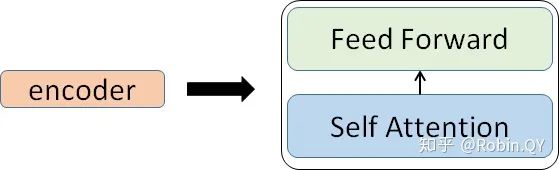
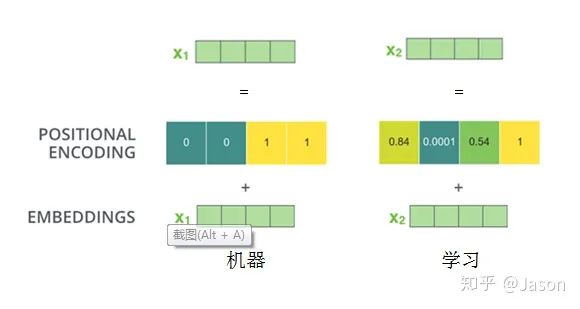
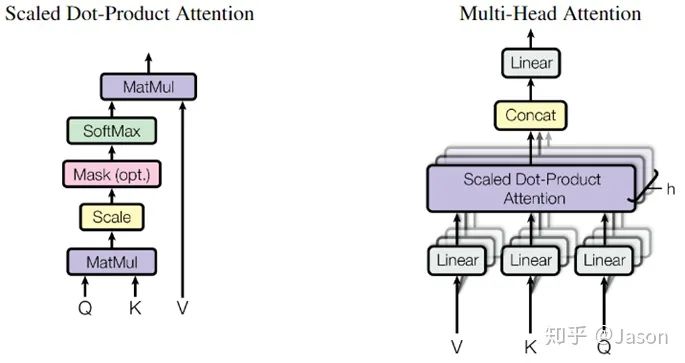
我们先来看下self-attention是什么样子的。
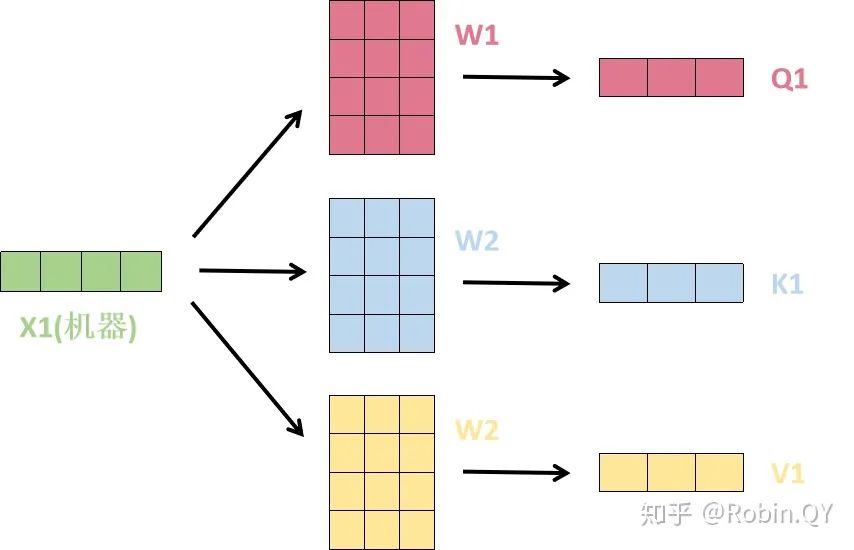
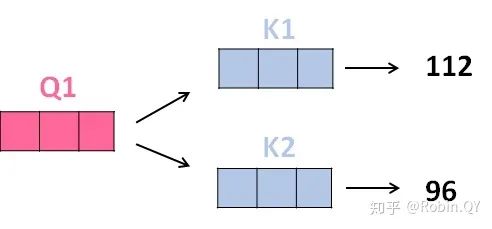
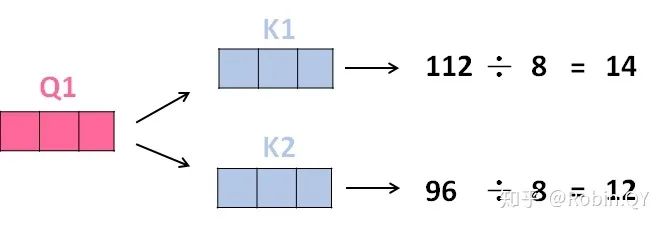
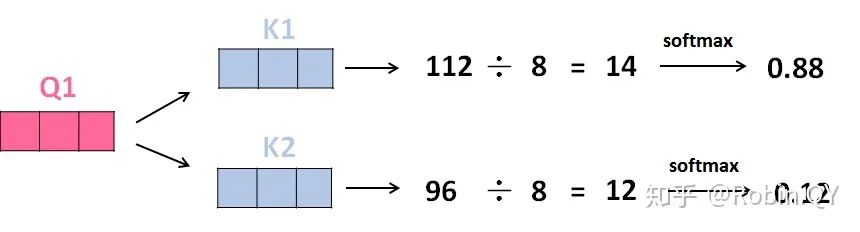
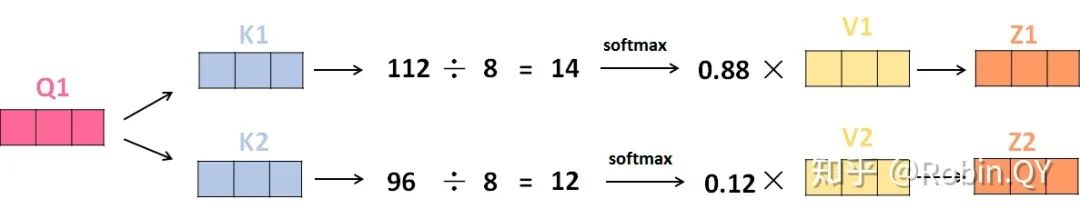

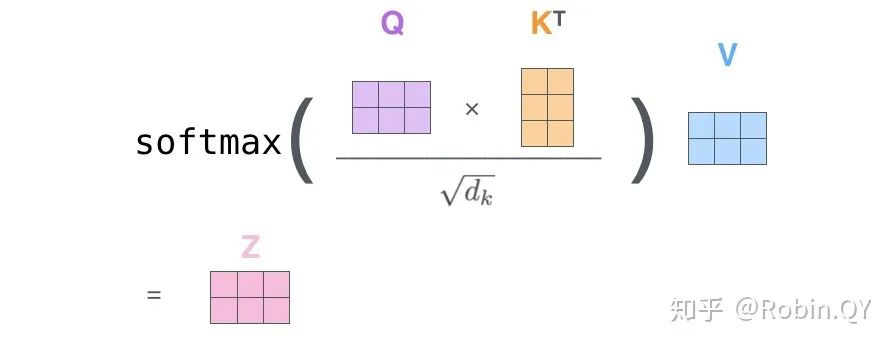
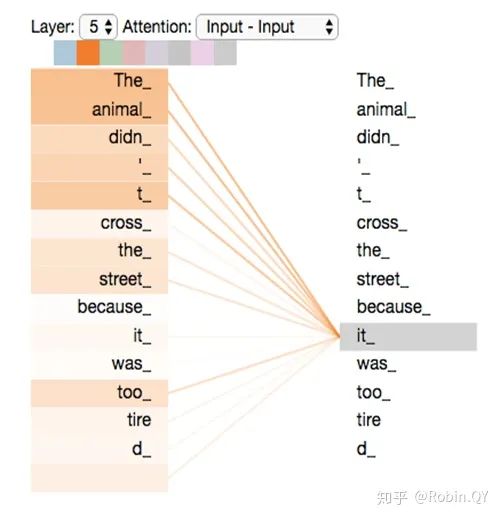
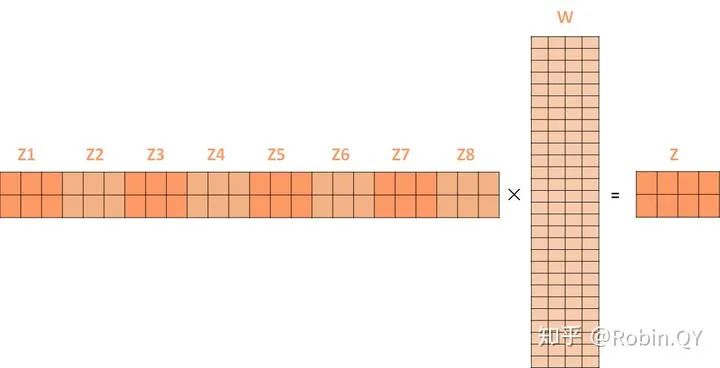
self-attention层到这里就结束了吗?

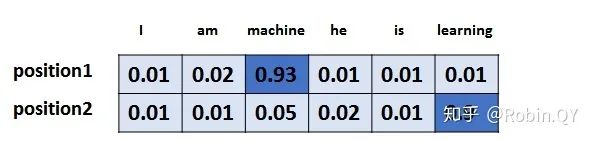
假设词汇表维度是6,那么输出最大概率词汇的过程如下:
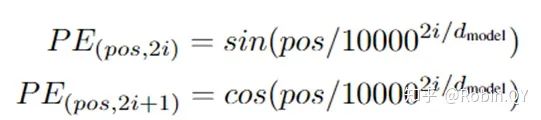
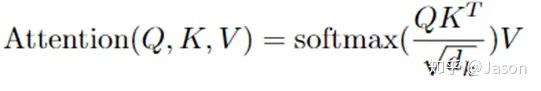
本文仅做学术分享,如有侵权,请联系删文。
评论