
笔记 | 深入理解Transformer
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

背景知识
高层次理解
通过实例来理解Tensor
Encoding
高层次理解Self-Attention
Self-Attention的细节
Self-Attention矩阵乘法
Multi-headed完善
整体过程
使用位置编码
编码规则
残差神经网络 Residuals
Decoder
Linear 和 Softmax层
回顾训练过程
LossFunction
TargetModel Outputs
TrainedModel Outputs
一、背景知识
Transformer是Google 的论文 Attention is All You Need中提出
Google开源了一个基于TensorFlow的 Tensor2Tensor的第三方库
哈佛大学用PyTorch 对 这篇文章进行了深度解读:http://nlp.seas.harvard.edu/2018/04/03/attention.html
二、高层次理解
首先将Transformer理解成一个黑盒子,黑盒子的功能是翻译,你输入一个语句,它对你的输入进行翻译操作。

黑盒子可以进行展开,由两部分组成:Encoders和Decoders

对黑盒子进一步细化,可以发现由6个Encoder和6个Decoder组成

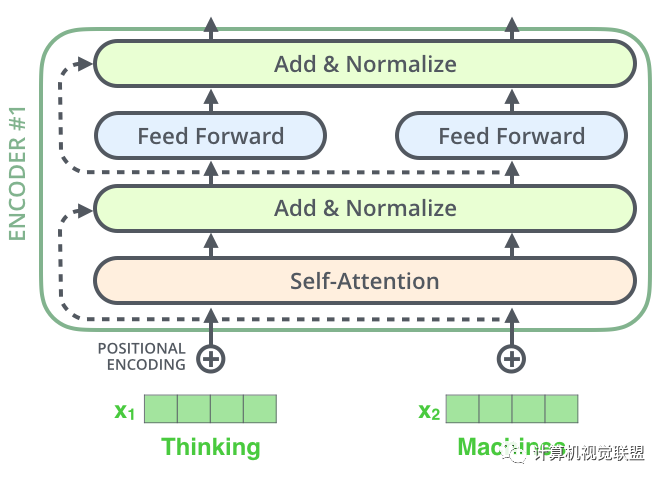
对于每一个Encoder,他们结构都是相同的,但是权值不共享。每一层都包括两部分:自监督+全连接
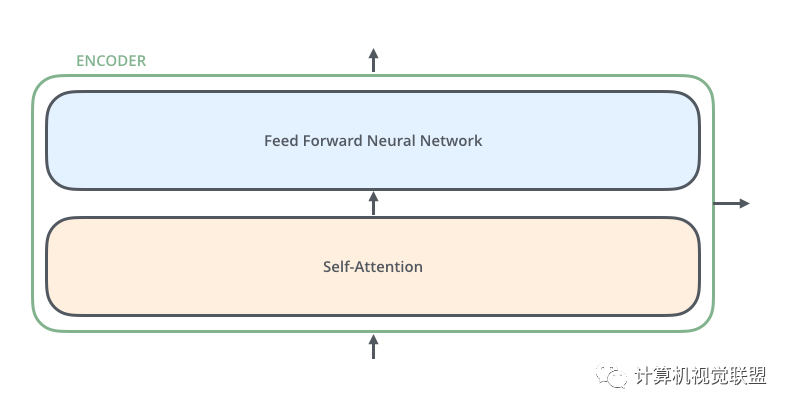
Self-attention的输入会被传入一个全连接的前馈神经网络,每个encoder的前馈神经网络的参数都是相同的,但是作用相互独立。
Decoder部分也有相同的层级结构,但是中间多了一个Encoder-Decoder-Attention层,帮助专注于对应的那个语句。(与Seq2Seq模型类似)

三、通过实例来理解Tensor
首先做一个embedding使得输入的单词成为向量,具体可看这篇博客:
https://blog.csdn.net/qq_41664845/article/details/84313419

列表的大小和词向量的维度大小都是可以设置的超参数,一般设置训练数据集中最长的句子的长度。这个例子是把每个单词编码为512维的向量。
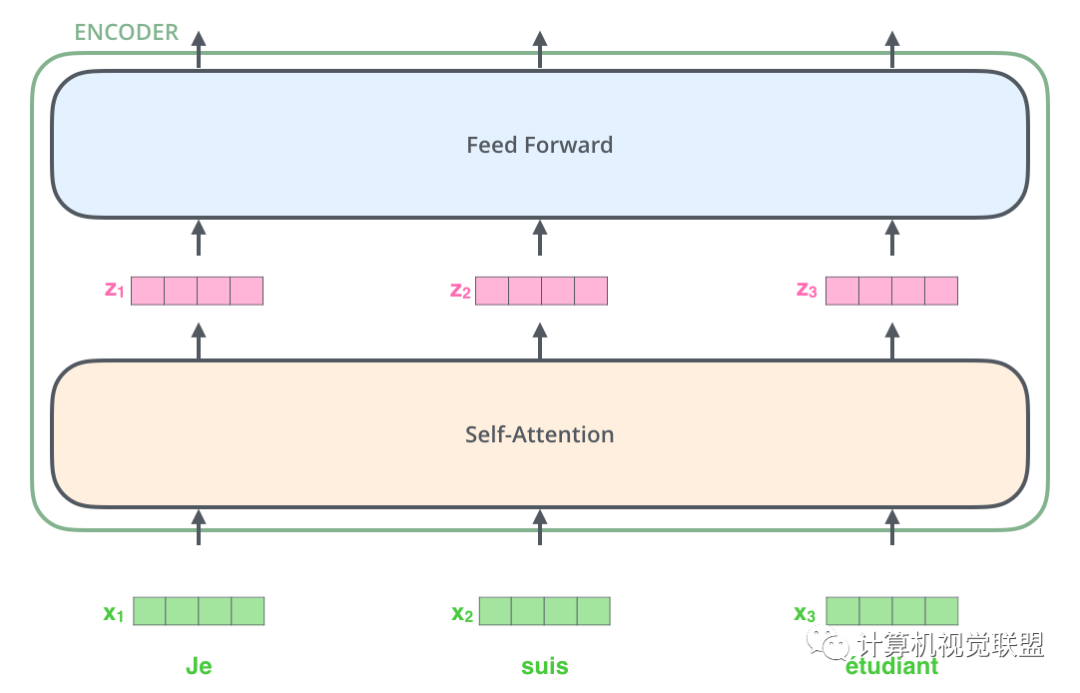
可以观察到,x1,x2,x3输入后通过self-attention,分别得到了z1,z2,z3,这点就要注意,其实z1,z2,z3这3个是通过x1,x2,x3一起合作产生的。
Encoding
每一个Encoder接收一个512维的向量x作为输入,然后传递Self-Attention,产生一个等量的512维的z,再经过全连接神经网络,输出的r也是512维,然后传递给下一个encoder
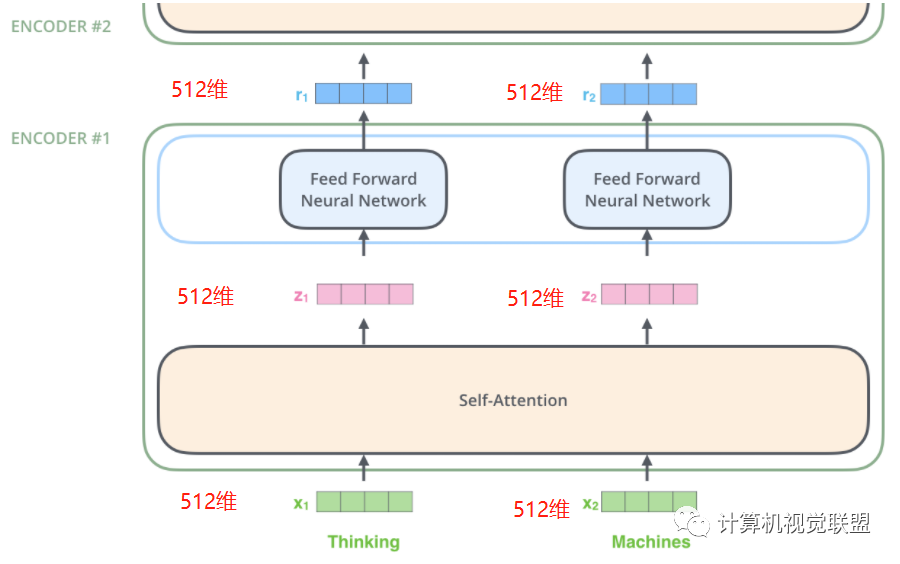
注意,前馈神经网络的结构其实是一致的
四、高层次理解Self-Attention
假如输入:
”The animal didn't cross the street because it was too tired”
这句话
那么句子中的“it”如何和“animal”关联起来?

Self-Attention的细节
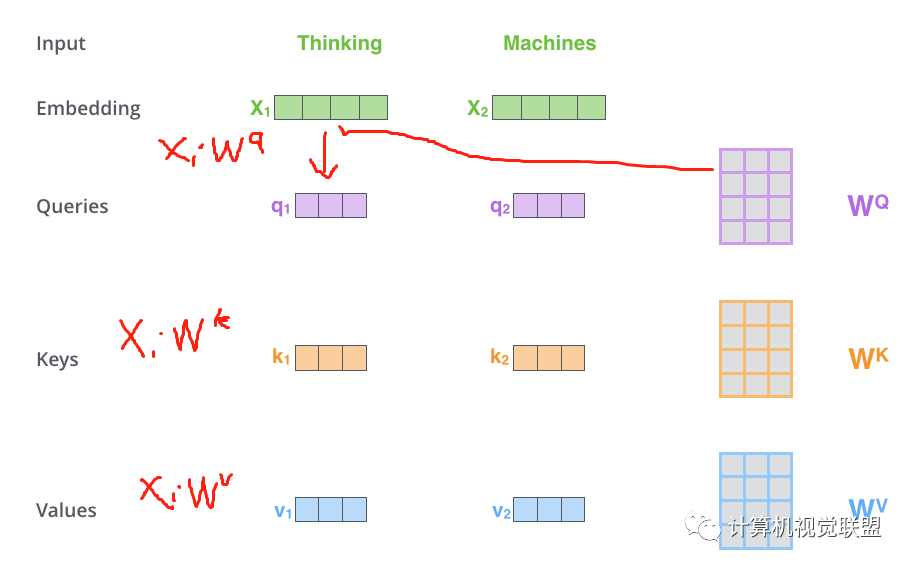
第一步:Q,K,V计算
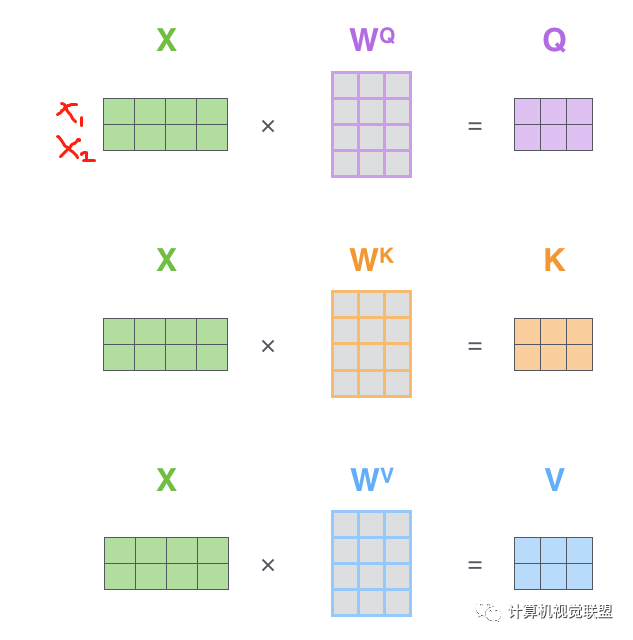
对于每个单词,我们创建一个Query向量,一个Key向量和一个Value向量。这些向量是通过词嵌入乘以我们训练过程中创建的3个训练矩阵而产生的。
输入的向量维度是512维,新向量的维度64维。新向量的维度通过实际情况自己确定。

Multiplying x1 by the WQ weight matrix produces q1
第二步:点乘
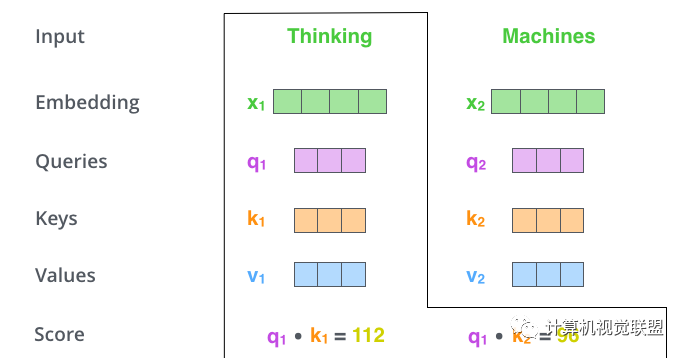
q1和k1点乘,q1和k2点乘,注意!!!是q1和k2!看清楚,不是q2
第三步、第四步:
将点乘的结果除以sqrt(dk)。这个里面向量是64,开方是8,那么就是除以8
然后进行Softmax的操作

Softmax的操作得到的分数,就是当前单词在每个句子中每个单位位置的表示程度。
第五步、第六步:
将Values和Softmax的值相乘得到v1,v2,对当前词的关注度不变,对不相关的的进行降低。
累加加权的向量得到z1

Self-Attention矩阵乘法
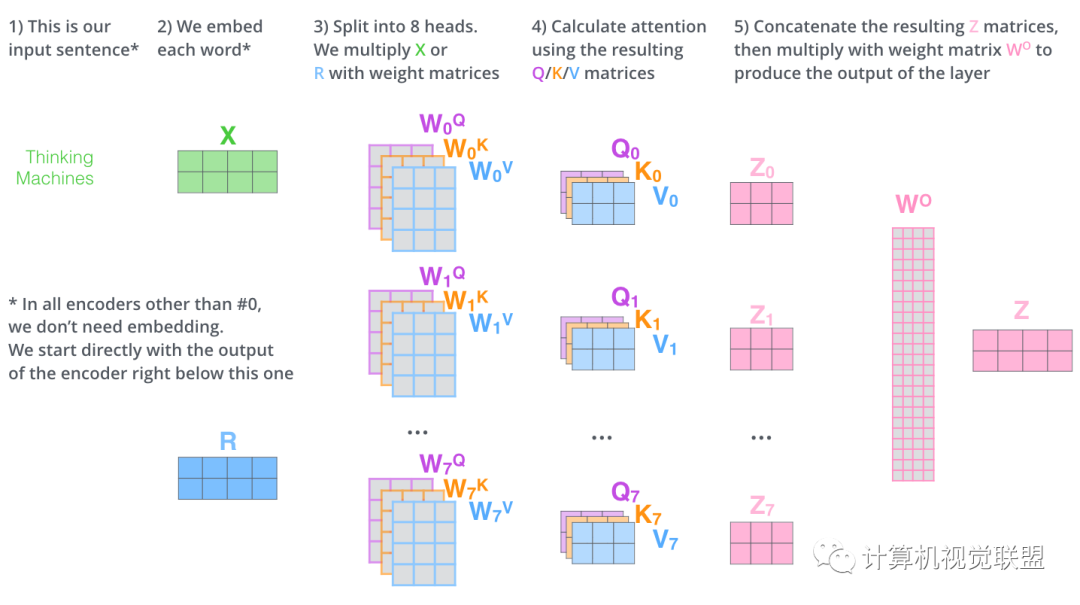
第一步是去计算Query,Key和Value矩阵。X是x1和x2一起转化为的矩阵。
然后一下子就操作得到后面的Z
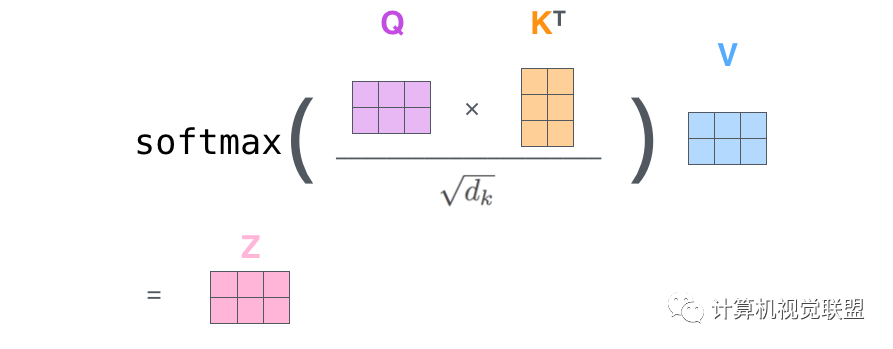
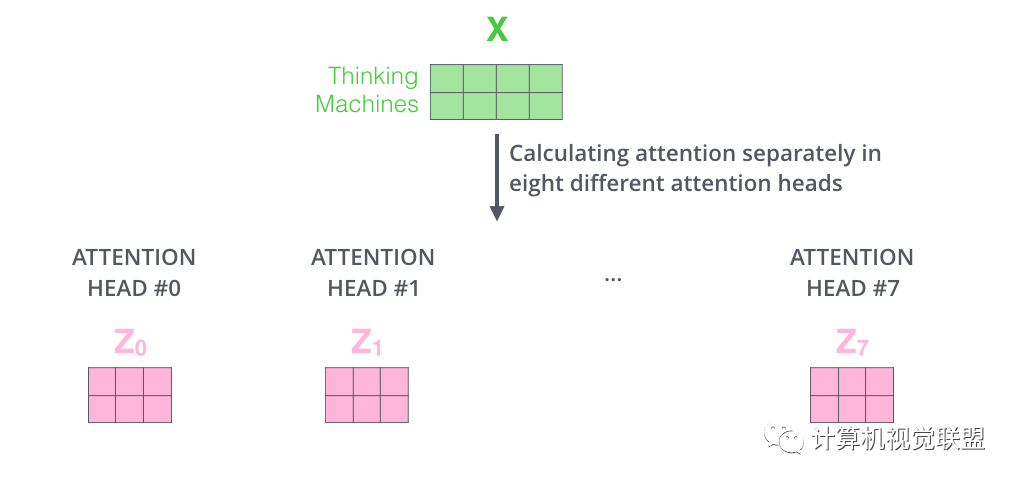
Multi-headed 完善
扩展了模型关注不同位置的能力
提供投影到不同的子空间subspace

通过multi-headed attention,我们为每个“header”都独立维护一套Q/K/V的权值矩阵。
使用8个时间点去计算权值矩阵,得到8个不同的矩阵z
把这8个矩阵链接在一起,然后再与矩阵Wo相乘
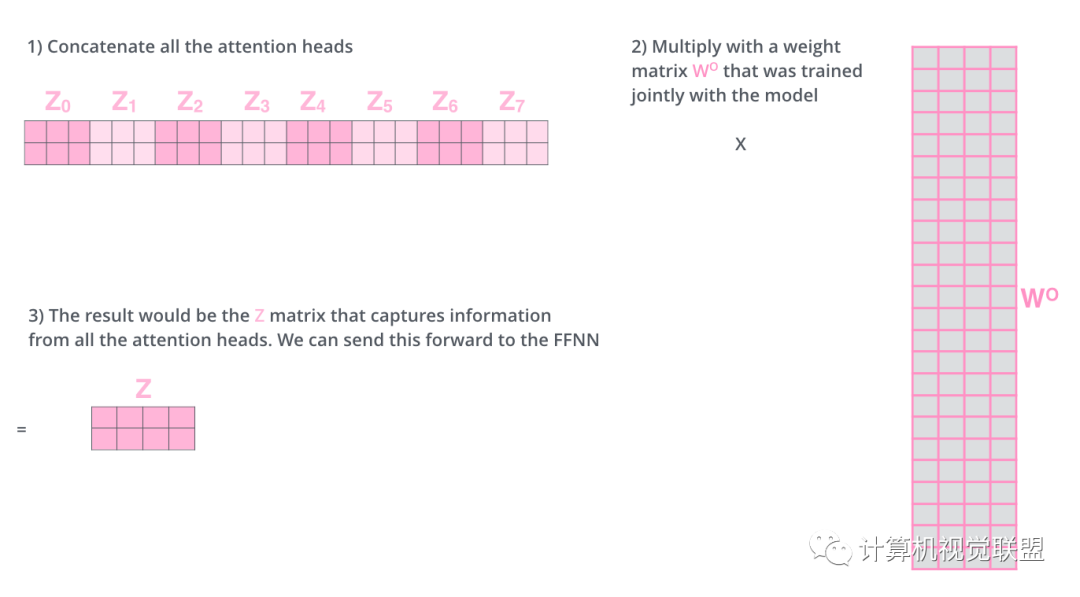
整体过程
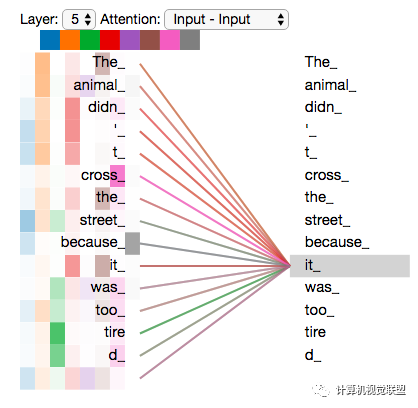
我们随意找两个不同的attention header的情况(8列,取下下图的2,3列),看一下关注点会有什么区别

这两个时间戳上面,发现it最关注两个:animal和tire
将所有注意力都添加到图片上,可能不那么容易理解其中含义
五、使用位置编码
输入序列还要考虑单词的顺序的问题
transformer为每个输入单词的词嵌入了一个新的位置向量。

为了让模型知道单词的顺序信息,将位置编码的向量信息直接进行规则产生
比如嵌入的维度是4,实际编码效果如下:
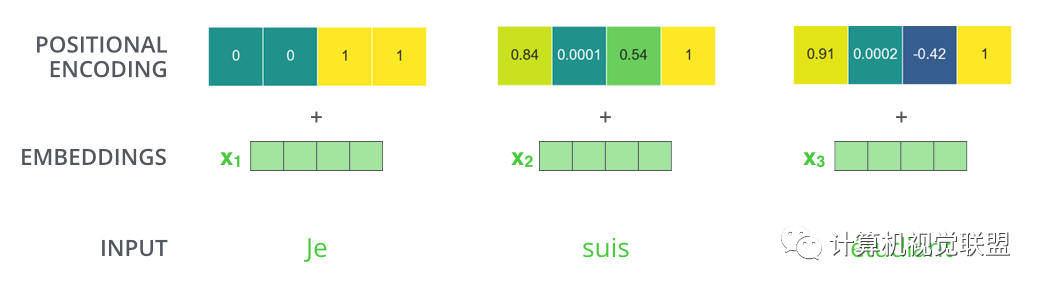
编码规则
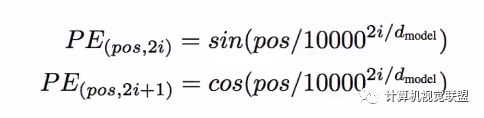

比如20个单词,每个单词编码为512维度。
一共20行,那么每一行就表示一个词向量,包含512个值,每个值在-1到1之间。可视化显示:

中心位置一分为2,主要是一半是正弦生成,一半是余弦生成。
对上述的Transformer2Transformer有细微改变显示的话:

import numpy as npimport matplotlib.pyplot as plt# https://github.com/jalammar/jalammar.github.io/blob/master/notebookes/transformer/transformer_positional_encoding_graph.ipynb# Code from https://www.tensorflow.org/tutorials/text/transformerdef get_angles(pos, i, d_model):angle_rates = 1 / np.power(10000, (2 * (i//2)) / np.float32(d_model))return pos * angle_ratesdef positional_encoding(position, d_model):angle_rads = get_angles(np.arange(position)[:, np.newaxis],np.arange(d_model)[np.newaxis, :],d_model)# apply sin to even indices in the array; 2iangle_rads[:, 0::2] = np.sin(angle_rads[:, 0::2])# apply cos to odd indices in the array; 2i+1angle_rads[:, 1::2] = np.cos(angle_rads[:, 1::2])pos_encoding = angle_rads[np.newaxis, ...]return pos_encodingtokens = 10dimensions = 64pos_encoding = positional_encoding(tokens, dimensions)print (pos_encoding.shape)plt.figure(figsize=(12,8))plt.pcolormesh(pos_encoding[0], cmap='viridis')plt.xlabel('Embedding Dimensions')plt.xlim((0, dimensions))plt.ylim((tokens,0))plt.ylabel('Token Position')plt.colorbar()plt.show()
六、残差神经网络 Residuals
layer-normalization步骤
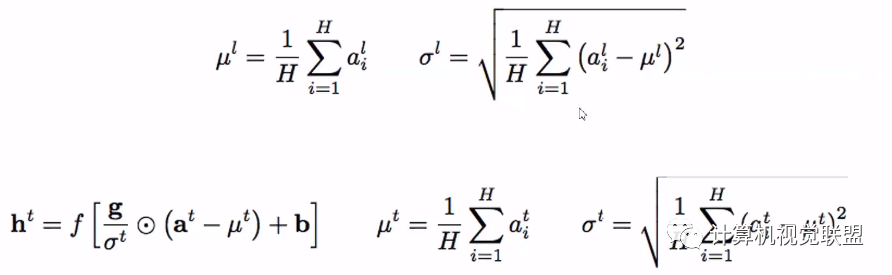

进一步可视化
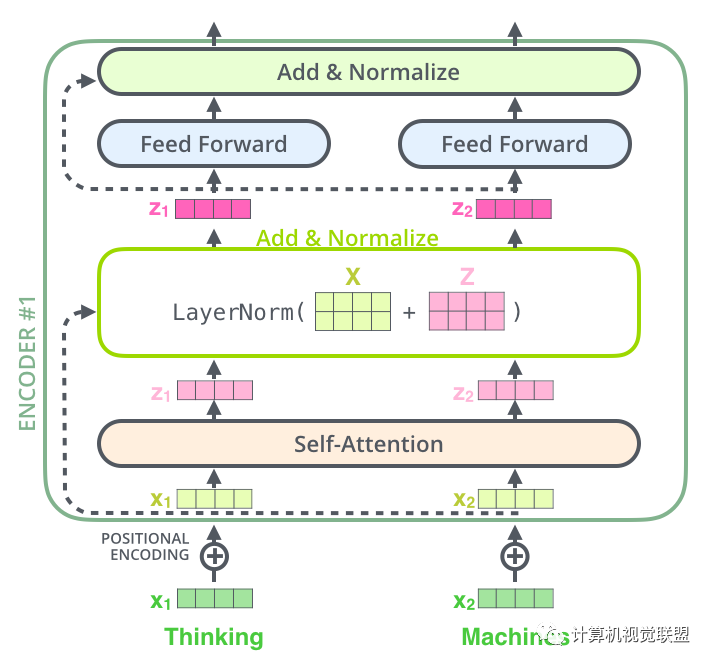
Decoder部分和这个是同样的。我们堆叠了2个Encoder和2个Decoder
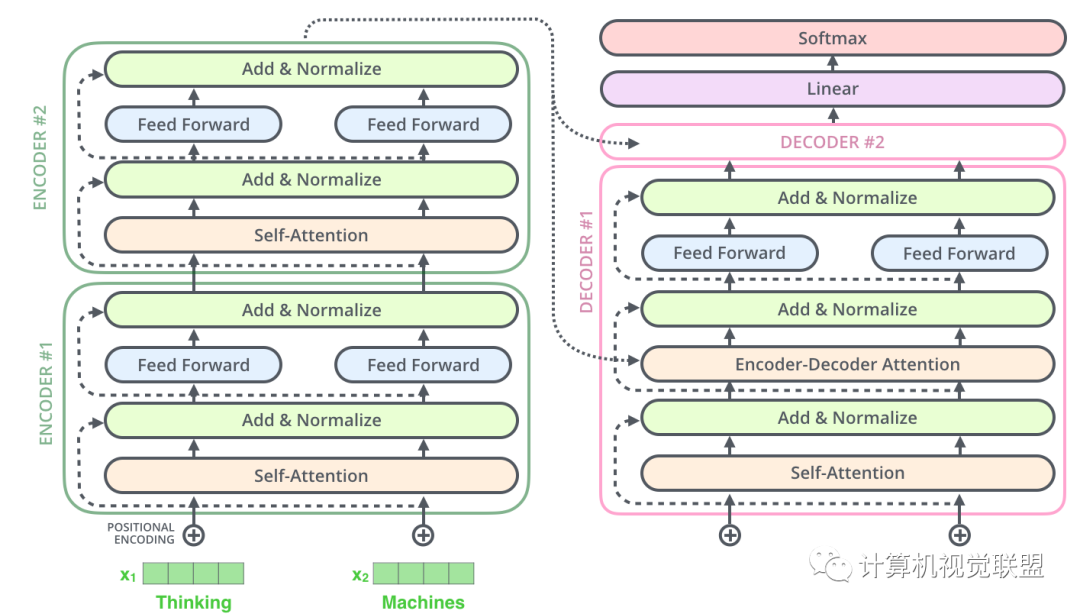
七、Decoder
Encoder将其转化为一组attention的集合(K,V)
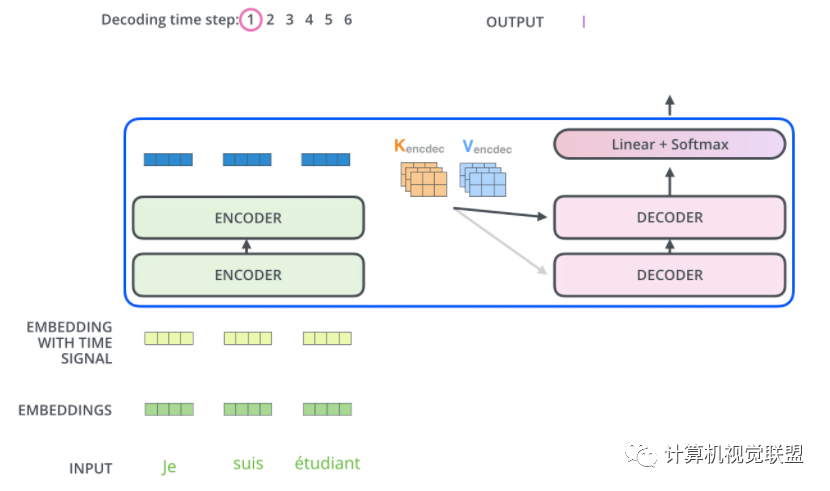
八、Linear 和 Softmax层
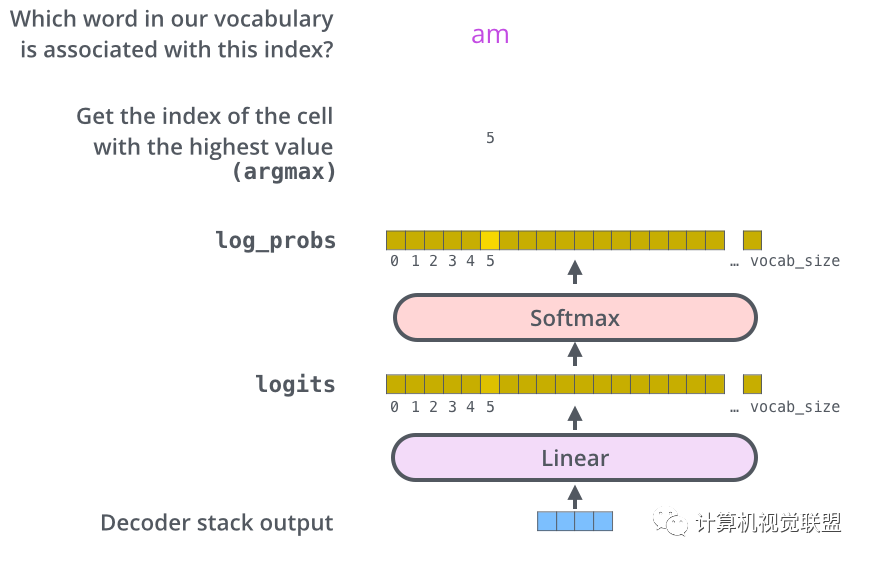
线性层是一个简单的全连接神经网络,由Decoder产生的向量投影到一个更大的向量中,成为对数向量Logits.
假设实验模型的语料库一共1万个英语单词,那么Logits的矢量表示1万个小格子,每个小格子就表示了一个单词。
线性层之后是一个Softmax层,Softmax层可以通过转换将分数转换为概率,选取概率最高的作为索引,然后通过索引找到单词作为输出
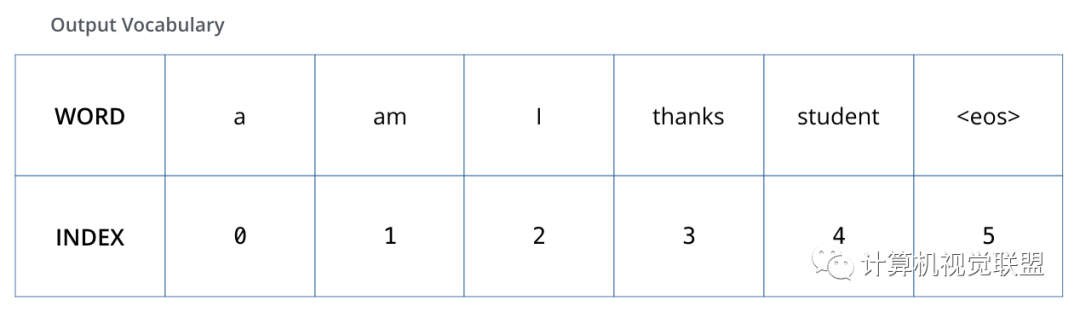
九、回顾训练过程
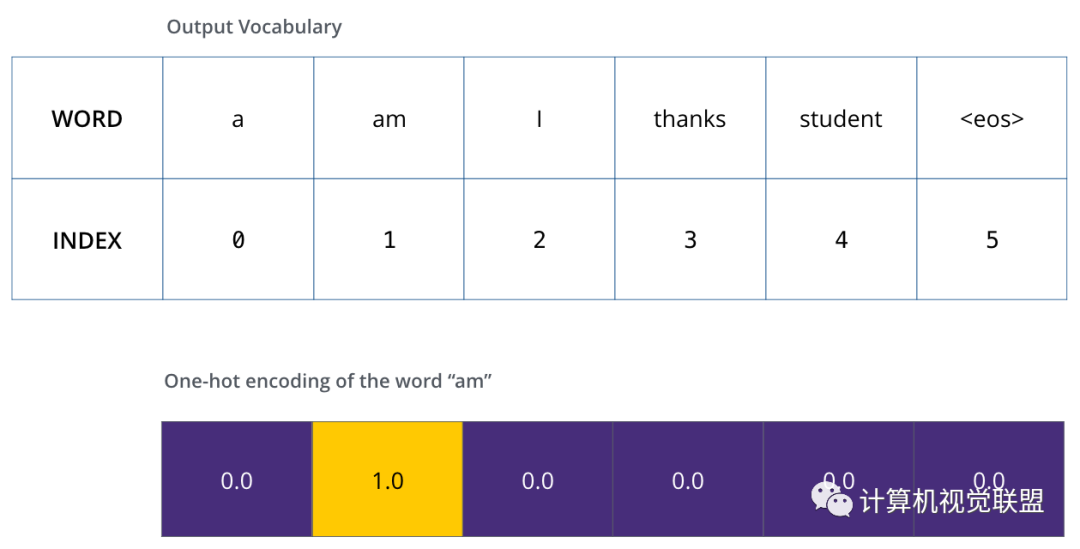
假设输出的词汇只有“a”、“am”、“I”、“thanks”、“student”、“
一旦确定了输出的词汇表,就可以使用相同宽度的向量来表示词汇表中的单词,称为one-hot编码
举例子以句子中的“am”为例子,one-hot编码
Loss Function
模型的参数权重是随机初始化的
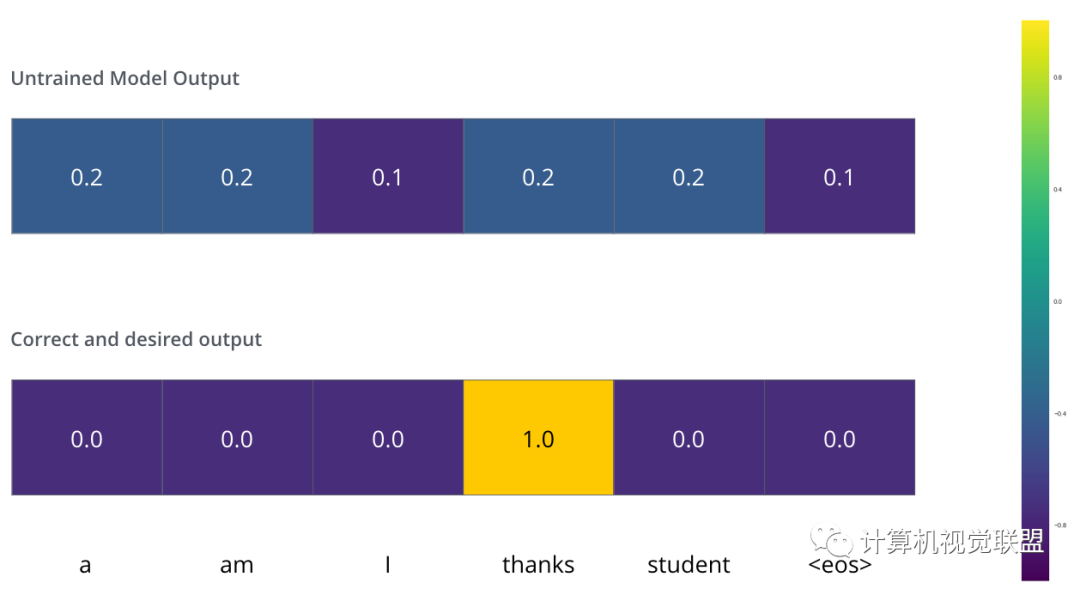
实际上做一个简单的减法就行
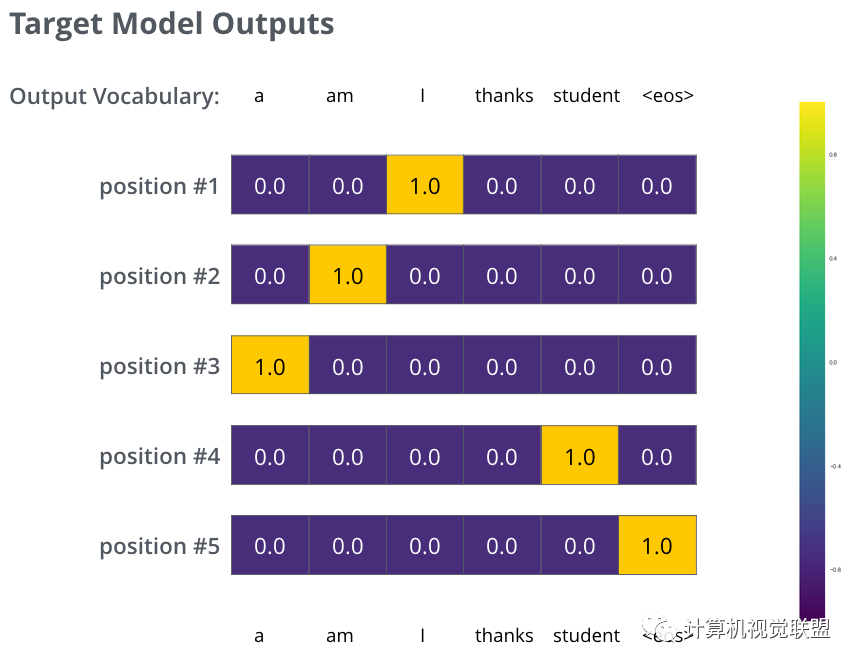
Target Model Outputs
Trained Model Outputs
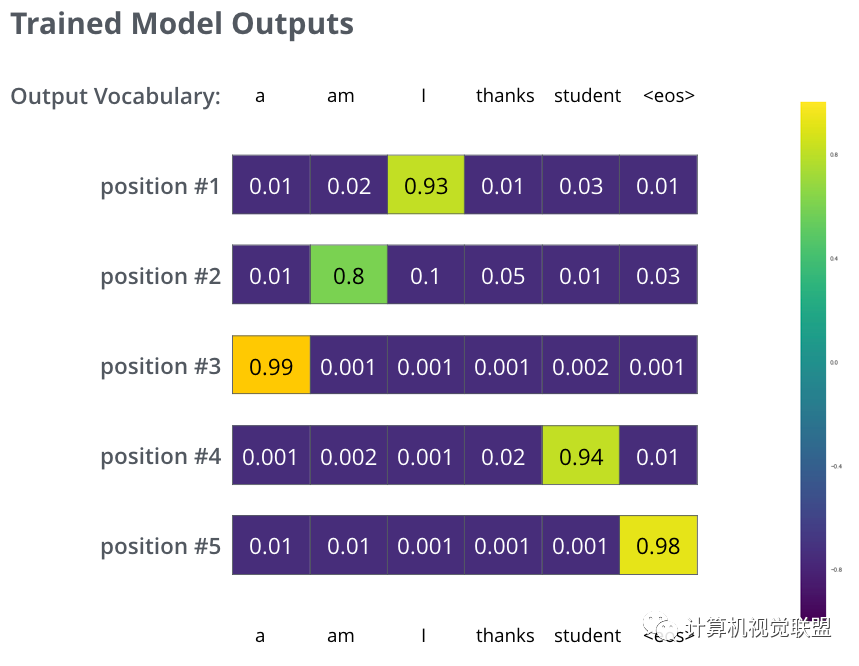
虽然没有那么准确,但是通过比较可以找到最大的概率值
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~