
10分钟带你深入理解Transformer原理及实现
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文转自|深度学习这件小事
基于 Transformer《Attention Is All You Need》构建的模型(比如 Bert ),在多个自然语言处理任务上都取得了革命性的效果,目前已取代 RNN 成为默认选项,可见 Transformer 的厉害之处。
结合 Harvard 的代码《Annotated Transformer》分享一下这个 encoder-decoder 与 attention 机制结合的方法。代码链接:The Annotated Transformer。
目录:
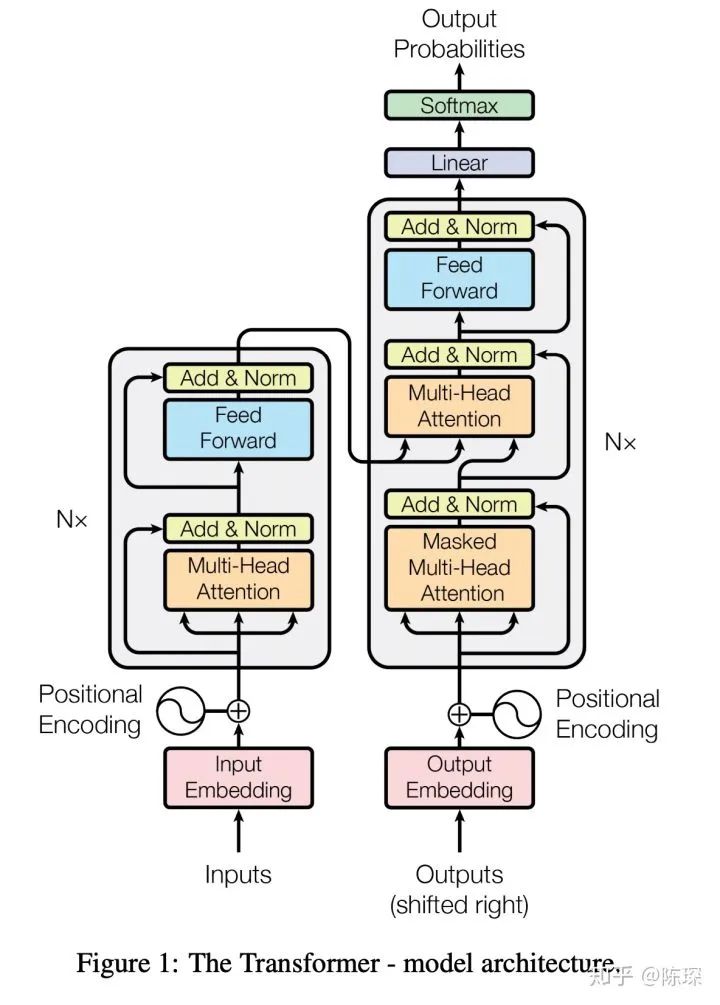
整体架构描述
Input & Output Embedding
OneHot Encoding
Word Embedding
Positional Embedding
Input short summary
Encoder
Encoder Sub-layer 1: Multi-Head Attention Mechanism
Step 1
Step 2
Step 3
Encoder Sub-layer 2: Position-Wise fully connected feed-forward
Encoder short summary
Decoder
Diff_1:“masked” Multi-Headed Attention
Diff_2:encoder-decoder multi-head attention
Diff_3:Linear and Softmax to Produce Output Probabilities
greedy search
beam search
Scheduled Sampling
0.模型架构
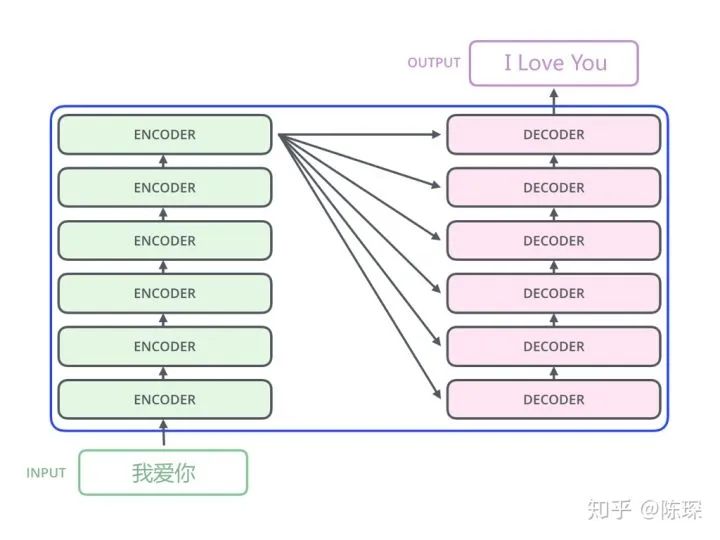
今天的示例任务为中译英:中文输入为“我爱你”,通过 Transformer 翻译为 “I Love You”。
Transformer 中对应的超参数包括:

这些也是函数 make_model(src_vocal, tgt_vocab, N=6, d_model=512, d_ff = 2048, h=8, dropout=0.1) 使用的超参数。
整个架构猛一看是挺吓人的,首先还是需要将整个 Transformer 拆分进行描述:
Embedding 部分
Encoder 部分
Decoder 部分
1. 对 Input 和 Output 进行 representation
1.1 对 Input 的 represent
首先用常用来表达 categorical 特征的方法即one-hot encoding 对句子进行表达。one-hot 指的是一个向量只有一个元素是1,其余的都为0。很直接的,vector 的长度就是由词汇表 vocabulary 的长度决定的。如果想要表达10000个word,那么就需要10000维的向量。
1.2 word embedding
但我们不直接给 Transformer 输入简单的one-hot vector,原因包括这种表达方式的结果非常稀疏,非常大,且不能表达 word 与 word 之间的特征。所以这里对词进行 embedding,用较短的向量表达这个 word 的属性。一般在 Pytorch 中,我们都是用 nn.Embedding 来做,或者直接用 one-hot vector 与权重矩阵 W 相乘得到。
nn.Embedding 包含一个权重矩阵 W,对应的 shape 为 ( num_embeddings,embedding_dim )。num_embeddings 指的是词汇量,即想要翻译的 vocabulary 的长度。embedding_dim 指的是想用多长的 vector 来表达一个词,可以任意选择,比如64,128,256,512等。在 Transformer 论文中选择的是512(即 d_model =512)。
其实可以形象地将 nn.Embedding 理解成一个 lookup table,里面对每一个 word 都存了向量 vector 。给任意一个 word,都可以从表中查出对应的结果。
处理 nn.Embedding 权重矩阵有两种选择:
使用 pre-trained 的 embeddings 并固化,这种情况下实际就是一个 lookup table。
对其进行随机初始化(当然也可以选择 pre-trained 的结果),但设为 trainable。这样在 training 过程中不断地对 embeddings 进行改进。
Transformer 选择的是后者。
在 Annotated Transformer 中,class “Embeddings“ 用来生成 word 的embeddings,其中用到 nn.Embedding。具体实现见下:
class Embeddings(nn.Module):
def __init__(self, d_model, vocab):
super(Embeddings, self).__init__()
self.lut = nn.Embedding(vocab, d_model)
self.d_model = d_model
def forward(self, x):
return self.lut(x) * math.sqrt(self.d_model)
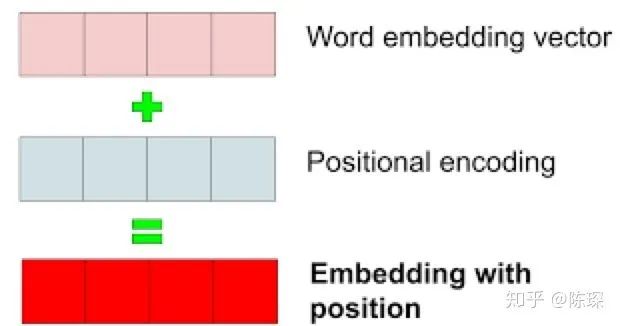
1.3 Positional Embedding
我们对每一个 word 进行 embedding 作为 input 表达。但是还有问题,embedding 本身不包含在句子中的相对位置信息。
那 RNN 为什么在任何地方都可以对同一个 word 使用同样的向量呢?因为 RNN 是按顺序对句子进行处理的,一次一个 word。但是在 Transformer 中,输入句子的所有 word 是同时处理的,没有考虑词的排序和位置信息。
对此,Transformer 的作者提出了加入 ”positional encoding“ 的方法来解决这个问题。”positional encoding“ 使得 Transformer 可以衡量 word 位置有关的信息。
positional encoding 与 word embedding 相加就得到 embedding with position。
那么具体 ”positional encoding“ 怎么做?为什么能表达位置信息呢?作者探索了两种创建 positional encoding 的方法:
通过训练学习 positional encoding 向量
使用公式来计算 positional encoding向量
试验后发现两种选择的结果是相似的,所以采用了第2种方法,优点是不需要训练参数,而且即使在训练集中没有出现过的句子长度上也能用。
计算 positional encoding 的公式为:
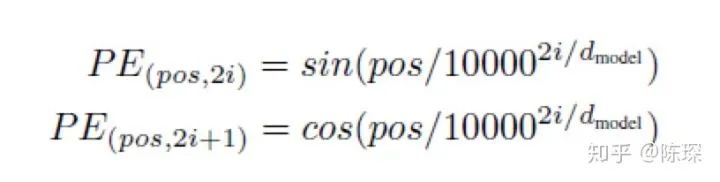
在这个公式中:
pos 指的是这个 word 在这个句子中的位置
i指的是 embedding 维度。比如选择 d_model=512,那么i就从1数到512
为什么选择 sin 和 cos ?positional encoding 的每一个维度都对应着一个正弦曲线,作者假设这样可以让模型相对轻松地通过对应位置来学习。

在 Annotated Transformer 中,使用 class ”Positional Encoding“ 来创建 positional encoding 并加入到 word embedding 中:
class PositionalEncoding(nn.Module):
"Implement the PE function."
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# Compute the positional encodings once in log space.
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) *
-(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + Variable(self.pe[:, :x.size(1)],requires_grad=False)
return self.dropout(x)
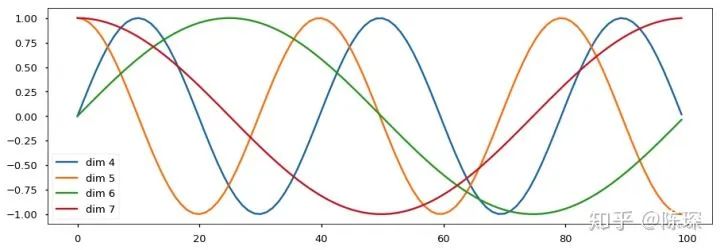
波的频率和偏移对于每个维度是不同的:
1.4 Input 小总结
经过 word embedding 和 positional embedding 后可以得到一个句子的 representation,比如”我爱你“这个句子,就被转换成了三个向量,每个向量都包含 word 的特征和 word 在句子中的位置信息:
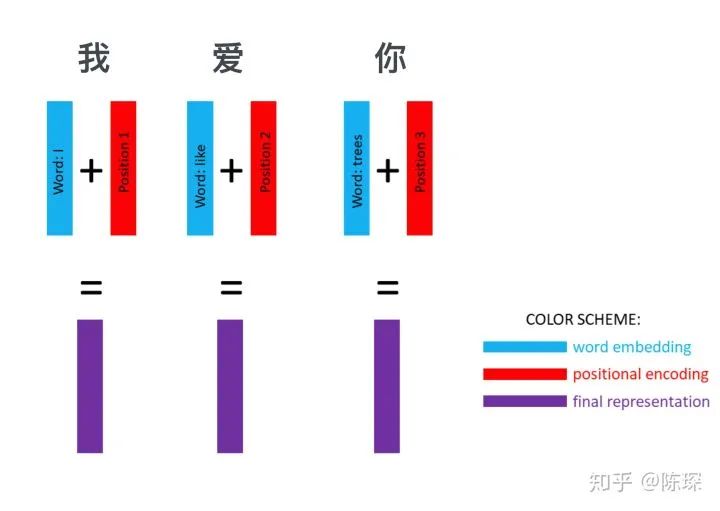
我们对输出的结果做同样的操作,这里即中英翻译的结果 ”I Love You“。使用word embedding 和 positional encoding 对其进行 represent。
Input Tensor 的 size 为 [nbatches, L, 512]:
nbatches 指的是定义的 batch_size
L 指的是 sequence 的长度,(比如“我爱你”,L = 3)
512 指的是 embedding 的 dimension
目前完成了模型架构的底层的部分:
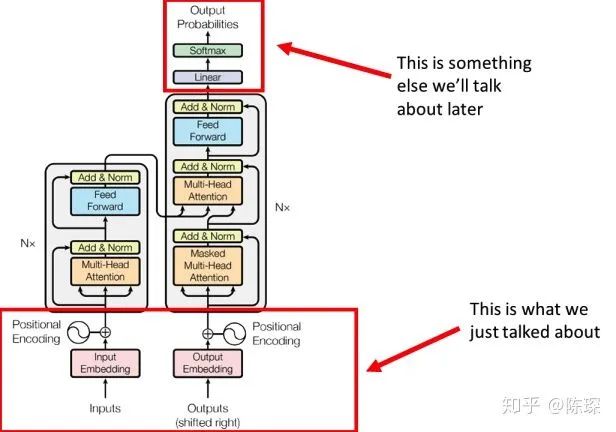
2. Encoder
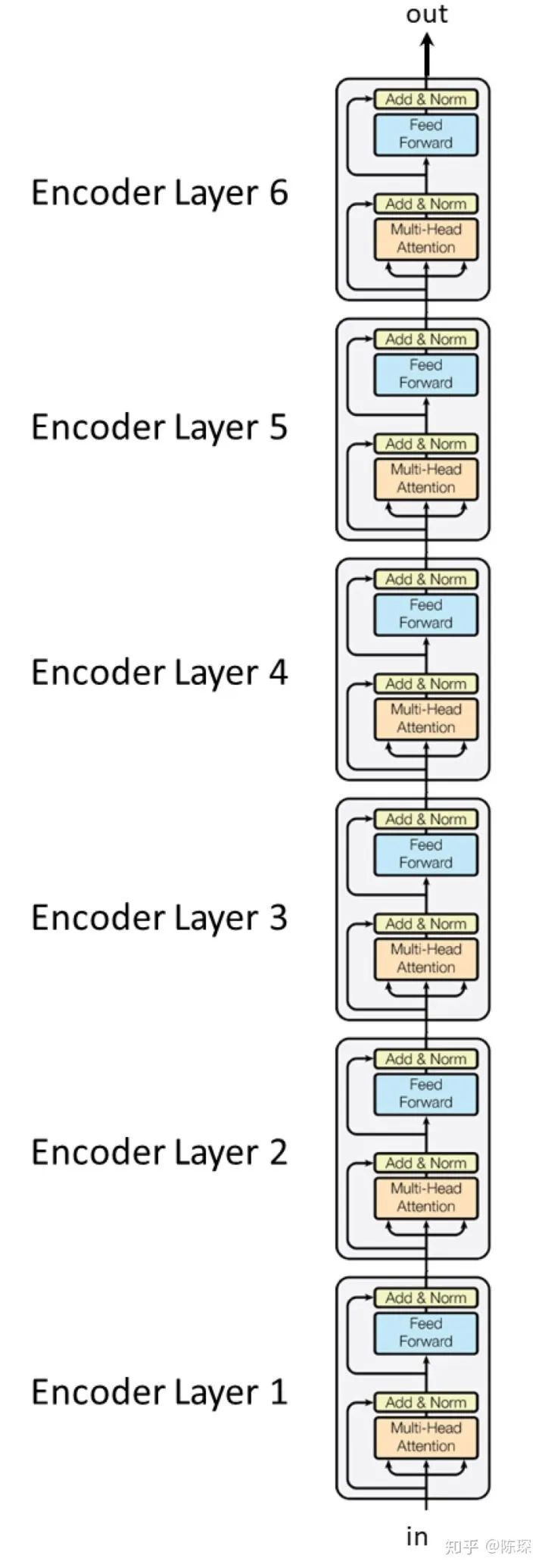
Encoder 相对 Decoder 会稍微麻烦一些。Encoder 由 6 个相乘的 Layer 堆叠而成(6并不是固定的,可以基于实际情况修改),看起来像这样:
每个 Layer 包含 2 个 sub-layer:
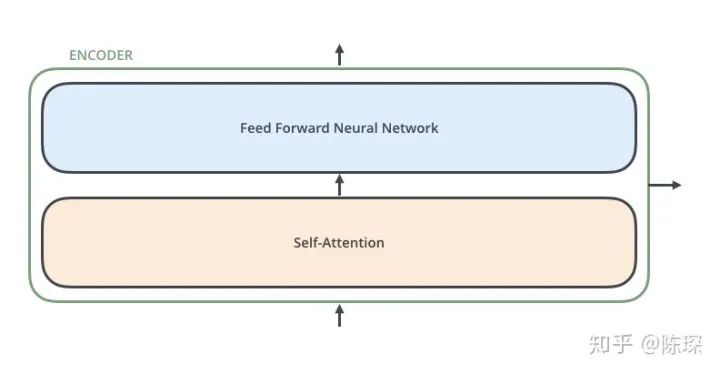
第一个是 ”multi-head self-attention mechanism“
第二个是 ”simple,position-wise fully connected feed-forward network“
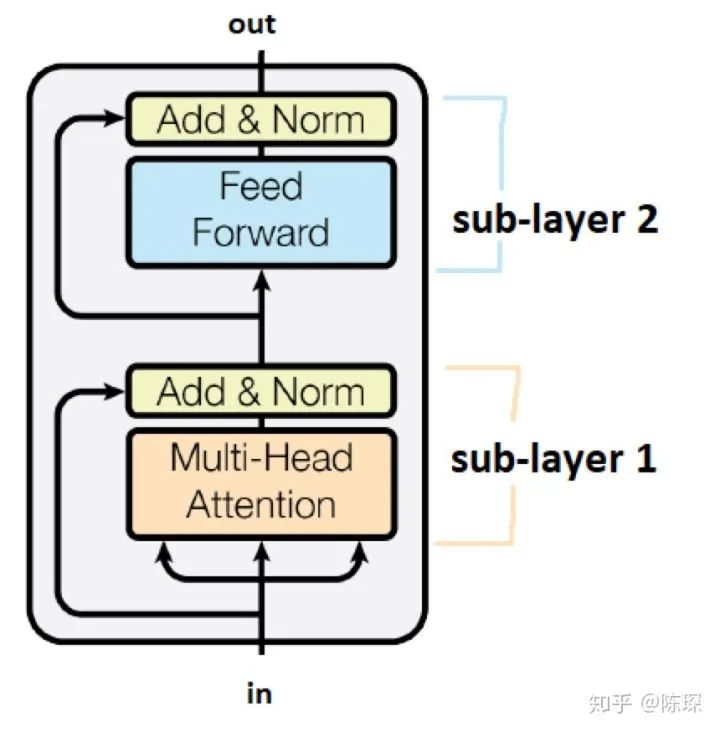
Annotated Transformer 中的 Encoder 实现代码:
class Encoder(nn.Module):
"Core encoder is a stack of N layers"
def __init__(self, layer, N):
super(Encoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, mask):
"Pass the input (and mask) through each layer in turn."
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)
class EncoderLayer(nn.Module):
"Encoder is made up of self-attn and feed forward (defined below)"
def __init__(self, size, self_attn, feed_forward, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = self_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 2)
self.size = size
def forward(self, x, mask):
"Follow Figure 1 (left) for connections."
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))
return self.sublayer[1](x, self.feed_forward)
class “Encoder” 将 <layer> 堆叠N次。是 class “EncoderLayer” 的实例。
“EncoderLayer” 初始化需要指定<size>,<self_attn>,<feed_forward>,<dropout>:
<size> 对应 d_model,论文中为512
<self_attn> 是 class MultiHeadedAttention 的实例,对应sub-layer 1
<feed_forward> 是 class PositionwiseFeedForward 的实例,对应sub-layer 2
<dropout> 对应 dropout rate
2.1 Encoder Sub-layer 1: Multi-Head Attention Mechanism
理解 Multi-Head Attention 机制对于理解 Transformer 特别重要,并且在 Encoder 和 Decoder 中都有用到。
概述:
我们把 attention 机制的输入定义为 x。x 在 Encoder 的不同位置,含义有所不同。在 Encoder 的开始,x 的含义是句子的 representation。在 EncoderLayer 的各层中间,x 代表前一层 EncoderLayer 的输出。
使用不同的 linear layers 基于 x 来计算 keys,queries和values:
key = linear_k(x)
query = linear_q(x)
value = linear_v(x)
linear_k, linear_q, linear_v 是相互独立、权重不同的。
计算得到 keys(K), queries(Q)和values(V) 值之后,按论文中如下公式计算 Attention:
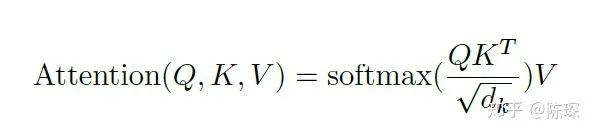
矩阵乘法表示:
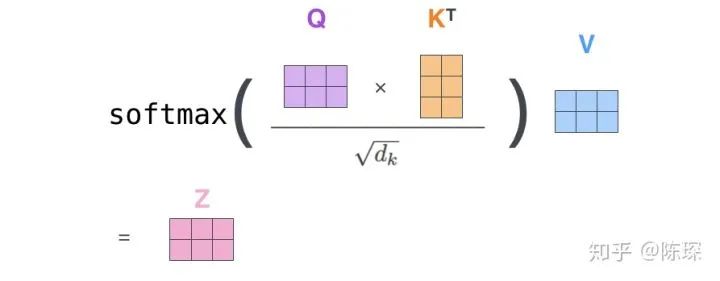
这里的比较奇怪的地方是为啥要除以 sqrt(d_k) 对吧?
作者的解释是说防止
 增大时,
增大时,  点积值过大,所以用
点积值过大,所以用  对其进行缩放。引用一下原文”We suspect that for large values of dk, the dot products grow large in magnitude, pushing the softmax function into regions where it has extremely small gradients” 对
对其进行缩放。引用一下原文”We suspect that for large values of dk, the dot products grow large in magnitude, pushing the softmax function into regions where it has extremely small gradients” 对 取 softmax 之后值都介于0到1之间,可以理解成得到了 attention weights。然后基于这个 attention weights 对 V 求 weighted sum 值 Attention(Q, K, V)。
取 softmax 之后值都介于0到1之间,可以理解成得到了 attention weights。然后基于这个 attention weights 对 V 求 weighted sum 值 Attention(Q, K, V)。详细解释:Annotated Transformer 中 Multi-Headed attention 的实现为
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
"Take in model size and number of heads."
super(MultiHeadedAttention, self).__init__()
assert d_model % h == 0
# We assume d_v always equals d_k
self.d_k = d_model // h
self.h = h
self.linears = clones(nn.Linear(d_model, d_model), 4)
self.attn = None
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
"Implements Figure 2"
if mask is not None:
# Same mask applied to all h heads.
mask = mask.unsqueeze(1)
nbatches = query.size(0)
# 1) Do all the linear projections in batch from d_model => h x d_k
query, key, value = \
[l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for l, x in zip(self.linears, (query, key, value))]
# 2) Apply attention on all the projected vectors in batch.
x, self.attn = attention(query, key, value, mask=mask,
dropout=self.dropout)
# 3) "Concat" using a view and apply a final linear.
x = x.transpose(1, 2).contiguous() \
.view(nbatches, -1, self.h * self.d_k)
return self.linears[-1](x)
这个 class 进行实例化时需要指定:
<h> = 8,即 “heads” 的数目。在 Transformer 的 base model 中有8 heads
<d_model> = 512
<dropout> = dropout rate = 0.1
keys 的维度 d_k 是基于
 计算来的。在上面的例子中 d_k = 512 / 8 = 64。
计算来的。在上面的例子中 d_k = 512 / 8 = 64。下面分3步详细介绍一下 MultiHeadedAttention 的 forward() 函数:
从上面的代码看出,forward 的 input 包括:query,key,values和mask。这里先暂时忽略 mask。query,key和value 是哪来的?实际上他们是 “x” 重复了三次得来的,x 或者是初始的句子 embedding或者是前一个 EncoderLayer 的输出,见 EncoderLayer 的代码黄色划线部分,self.self_atttn 是 MultiHeadedAttention 的一个实例化:

“query” 的 shape 为 [nbatches, L, 512] ,其中:
nbatches 对应 batch size
L 对应 sequence length ,512 对应 d_mode
“key” 和 “value” 的 shape 也为 [nbatches, L, 512]
Step 1)
对 “query”,“key”和“value”进行 linear transform ,他们的 shape 依然是[nbatches, L, 512]。
对其通过 view() 进行 reshape,shape 变成 [nbatches, L, 8, 64]。这里的h=8对应 heads 的数目,d_k=64 是 key 的维度。
transpose 交换 dimension1和2,shape 变成 [nbatches, 8, L 64]。
Step 2)
前面提到我们计算 attention 的公式:
Annotated Transformer 中的 attention() 代码为:
def attention(query, key, value, mask=None, dropout=None):
"Compute 'Scaled Dot Product Attention'"
d_k = query.size(-1)
scores = torch.matmul(query, key.transpose(-2, -1)) \
/ math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = F.softmax(scores, dim = -1)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn, value), p_attn
query 和 key.transpose(-2,-1) 相乘,两者分别对应的 shape 为 [nbatches, 8, L 64] 和 [nbatches, 8, 64, L]。这样相乘得到的结果 scores 的 shape为[nbatches, 8, L, L]。
对 scores 进行 softmax,所以 p_attn 的 shape 为 [nbatches, 8, L, L]。values的 shape 为 [nbatches, 8, L, 64]。所以最后 p_attn 与 values 相乘输出的 result 的 shape 为 [nbatches, 8, L, 64]。
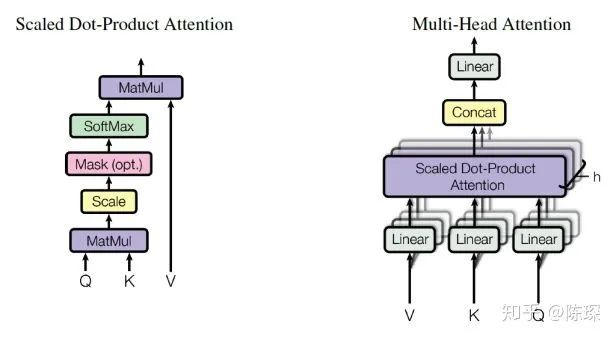
在我们的输入与输出中,有8个 heads 即 Tensor 中的 dimension 1,[ nbatches, 8, L, 64 ]。8个 heads 都进行了不同的矩阵乘法,这样就得到了不同的 “representation subspace”。这就是 multi-headed attention 的意义。
Step 3)
x的初始shape为 [ nbatches, 8, L, 64 ],x.transpose(1,2) 得到 [ nbatches,L, 8,64 ]。然后使用 view 进行 reshape 得到 [ nbatches, L, 512 ]。可以理解为8个heads结果的 concatenate 。最后使用 last linear layer 进行转换。shape仍为 [ nbatches, L, 512 ]。与input时的shape是完全一致的。
可视化见论文中的图例:
2.2 Encoder Sub-layer 2: Position-Wise fully connected feed-forward network
SubLayer-2 只是一个 feed-forward network。比较简单。
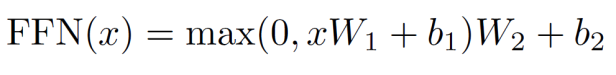
在 Annotated Transformer 中对应的实现为:
class PositionwiseFeedForward(nn.Module):
"Implements FFN equation."
def __init__(self, d_model, d_ff, dropout=0.1):
super(PositionwiseFeedForward, self).__init__()
self.w_1 = nn.Linear(d_model, d_ff)
self.w_2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
return self.w_2(self.dropout(F.relu(self.w_1(x))))
2.3 Encoder short summary
Encoder 总共包含6个 EncoderLayers 。每一个 EncoderLayer 包含2个 SubLayer:
SubLayer-1 做 Multi-Headed Attention
SubLayer-2 做 feedforward neural network
3. The Decoder
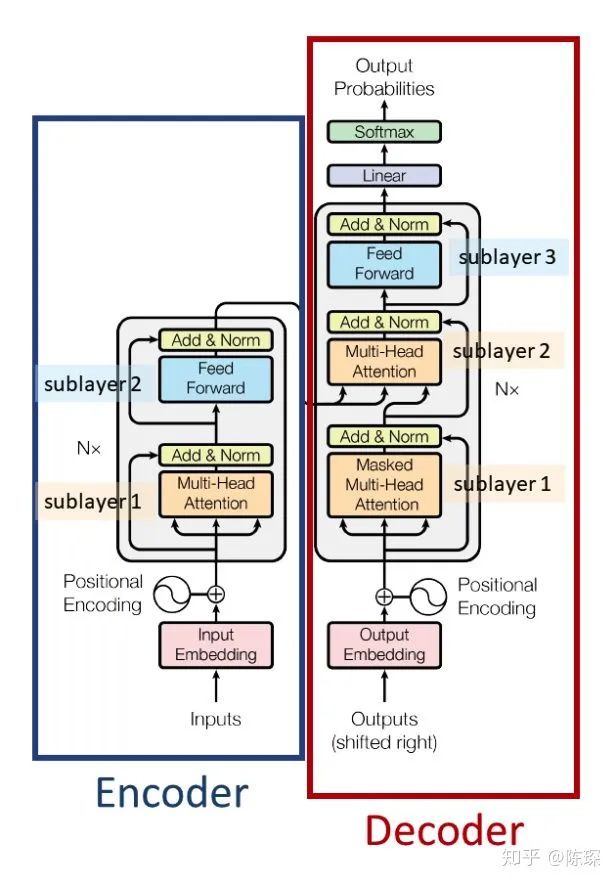
Encoder 与 Decoder 的交互方式可以理解为:
Decoder 也是N层堆叠的结构。被分为3个 SubLayer,可以看出 Encoder 与 Decoder 三大主要的不同:
Diff_1:Decoder SubLayer-1 使用的是 “masked” Multi-Headed Attention 机制,防止为了模型看到要预测的数据,防止泄露。
Diff_2:SubLayer-2 是一个 encoder-decoder multi-head attention。
Diff_3:LinearLayer 和 SoftmaxLayer 作用于 SubLayer-3 的输出后面,来预测对应的 word 的 probabilities 。
3.1 Diff_1 : “masked” Multi-Headed Attention
mask 的目标在于防止 decoder “seeing the future”,就像防止考生偷看考试答案一样。mask包含1和0:
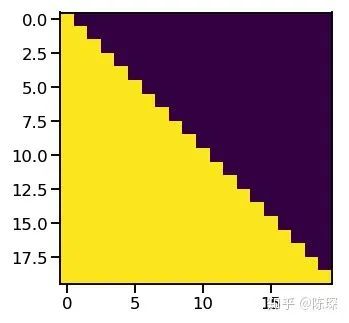
Attention 中使用 mask 的代码中:
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
引用作者的话说, “We […] modify the self-attention sub-layer in the decoder stack to prevent positions from attending to subsequent positions. This masking, combined with fact that the output embeddings are offset by one position, ensures that the predictions for position i can depend only on the known outputs at positions less than i.”
3.2 Diff_2 : encoder-decoder multi-head attention
Annotated Transformer 中的 DecoderLayer 的实现为:
class DecoderLayer(nn.Module):
"Decoder is made of self-attn, src-attn, and feed forward (defined below)"
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
super(DecoderLayer, self).__init__()
self.size = size
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 3)
def forward(self, x, memory, src_mask, tgt_mask):
m = memory
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask))
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask))
return self.sublayer[2](x, self.feed_forward)
重点在于 x = self.sublayer1 self.src_attn 是 MultiHeadedAttention 的一个实例。query = x,key = m, value = m, mask = src_mask,这里x来自上一个 DecoderLayer,m来自 Encoder的输出。
到这里 Transformer 中三种不同的 Attention 都已经集齐了:

3.3 Diff_3 : Linear and Softmax to Produce Output Probabilities
最后的 linear layer 将 decoder 的输出扩展到与 vocabulary size 一样的维度上。经过 softmax 后,选择概率最高的一个 word 作为预测结果。
假设我们有一个已经训练好的网络,在做预测时,步骤如下:
给 decoder 输入 encoder 对整个句子 embedding 的结果 和一个特殊的开始符号 </s>。decoder 将产生预测,在我们的例子中应该是 ”I”。
给 decoder 输入 encoder 的 embedding 结果和 “</s>I”,在这一步 decoder 应该产生预测 “Love”。
给 decoder 输入 encoder 的 embedding 结果和 “</s>I Love”,在这一步 decoder 应该产生预测 “China”。
给 decoder 输入 encoder 的 embedding 结果和 “</s>I Love China”, decoder应该生成句子结尾的标记,decoder 应该输出 ”</eos>”。
然后 decoder 生成了 </eos>,翻译完成。
但是在训练过程中,decoder 没那么好时,预测产生的词很可能不是我们想要的。这个时候如果再把错误的数据再输给 decoder,就会越跑越偏:
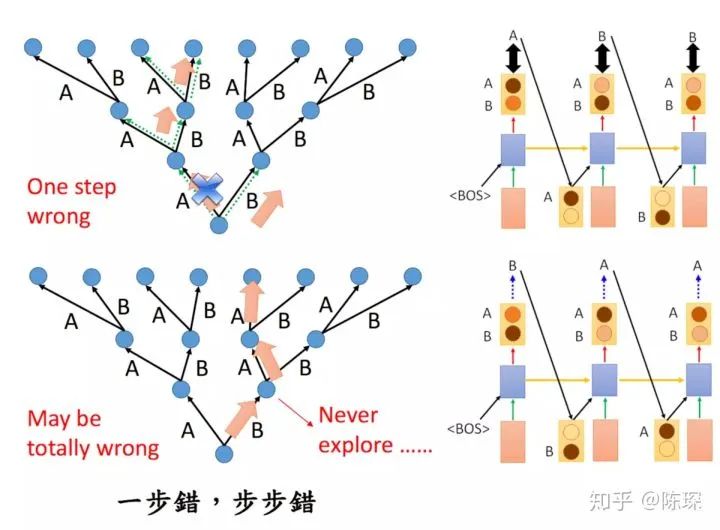
这里在训练过程中要使用到 “teacher forcing”。利用我们知道他实际应该预测的 word 是什么,在这个时候喂给他一个正确的结果作为输入。
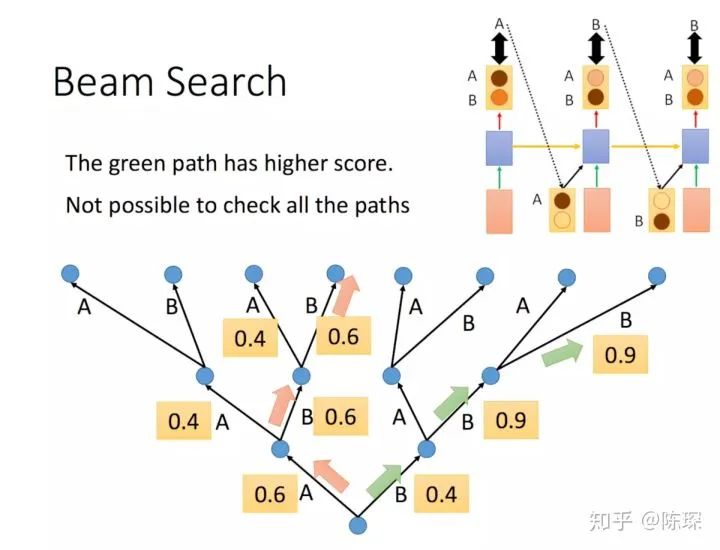
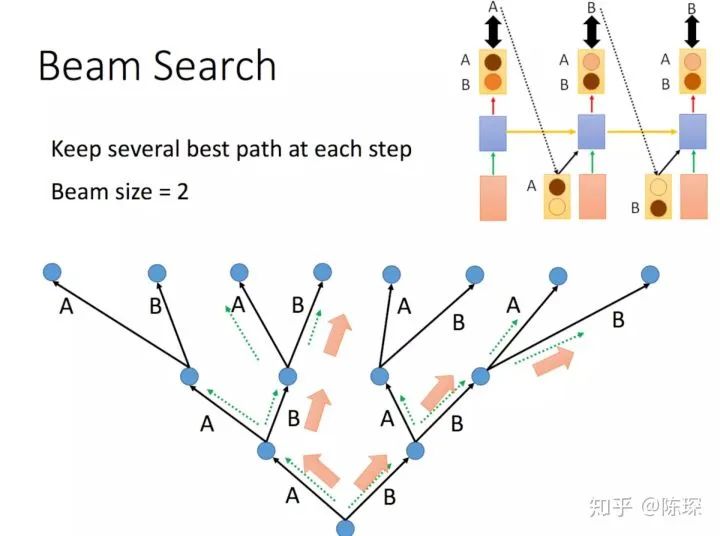
相对于选择最高的词 (greedy search),还有其他选择是比如 “beam search”,可以保留多个预测的 word。Beam Search 方法不再是只得到一个输出放到下一步去训练了,我们可以设定一个值,拿多个值放到下一步去训练,这条路径的概率等于每一步输出的概率的乘积,具体可以参考李宏毅老师的课程:
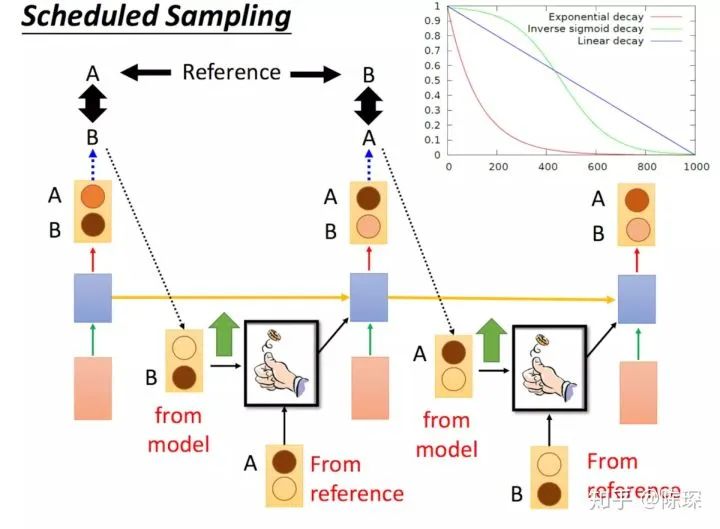
或者 “Scheduled Sampling”:一开始我们只用真实的句子序列进行训练,而随着训练过程的进行,我们开始慢慢加入模型的输出作为训练的输入这一过程。
这部分对应 Annotated Transformer 中的实现为:
class Generator(nn.Module):
"Define standard linear + softmax generation step."
def __init__(self, d_model, vocab):
super(Generator, self).__init__()
self.proj = nn.Linear(d_model, vocab)
def forward(self, x):
return F.log_softmax(self.proj(x), dim=-1)
对着图,再回顾一下 Encoder 与 Decoder 的结构吧。
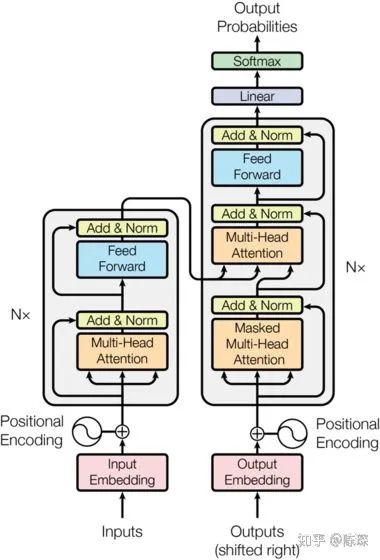
参考链接:
https://arxiv.org/pdf/1706.03762.pdf
https://glassboxmedicine.com/2019/08/15/the-transformer-attention-is-all-you-need/
https://jalammar.github.io/illustrated-transformer/
—完—
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~