B站讲课视频,差点翻车
大家好,我是DASOU。

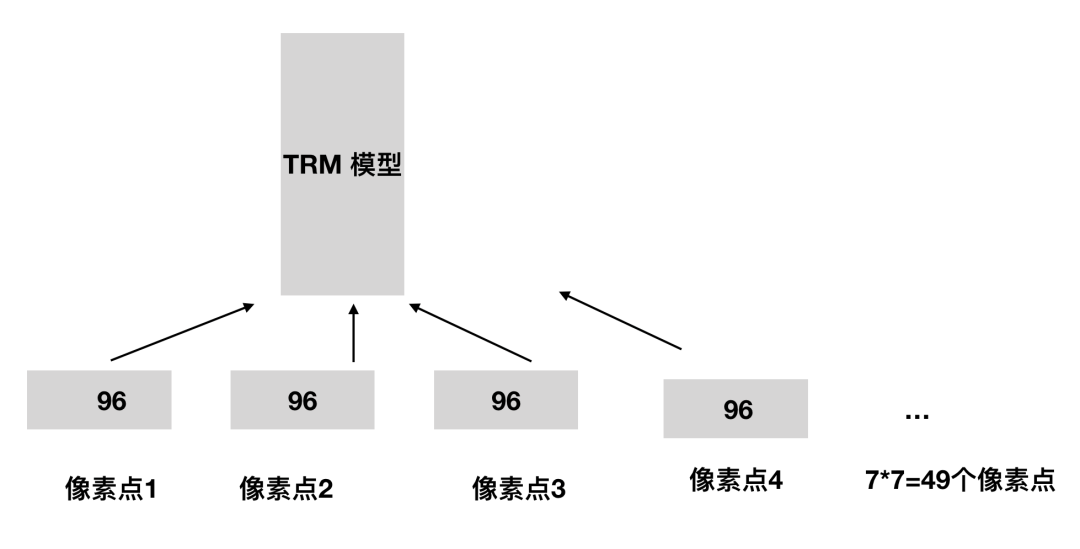
In our implementation, we use a patch size of 4 × 4 and thus the feature dimension of each patch is 4 × 4×3 = 48.
评论
 下载APP
下载APP大家好,我是DASOU。
In our implementation, we use a patch size of 4 × 4 and thus the feature dimension of each patch is 4 × 4×3 = 48.