
使用 Python 下载 B 站视频

文 | 某某白米饭
来源:Python 技术「ID: pythonall」

B 站,一个月活用户达到 1.72 的视频网站,有时候会因为某些未知的原因导致放入收藏夹的视频失效,为了防止视频被和谐、被失效,身为 Pythonista 来撸一个 B 站的视频下载器。
分析页面
首先我们在 B 站点开一个视频(https://www.bilibili.com/video/BV1Vh411Z7j5)用 F12 分析一波,在下图中可以看到有多个 m4s 结尾的链接,并且响应的类型是 video/mp4。
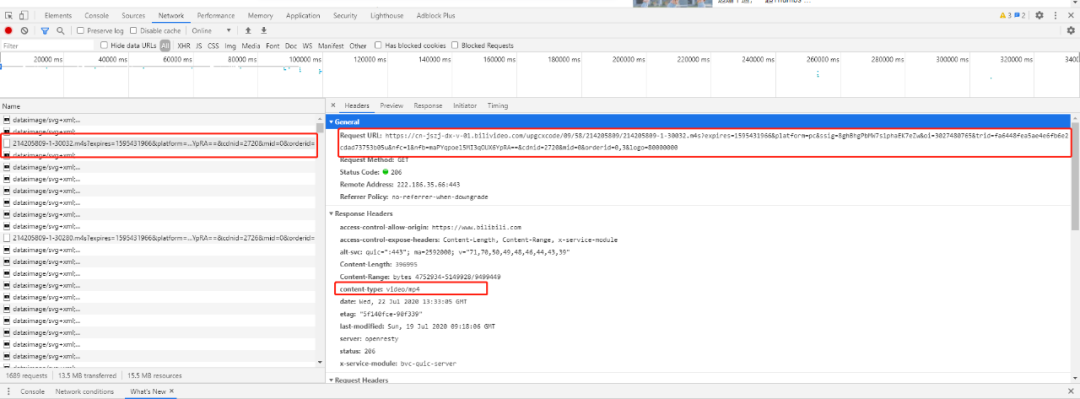
把面板打到 Elements 界面,找到一个 window.playinfo 的 javascript 变量,并且内容和上图中的 url 类似,都是 m4s 链接,目标已找到。
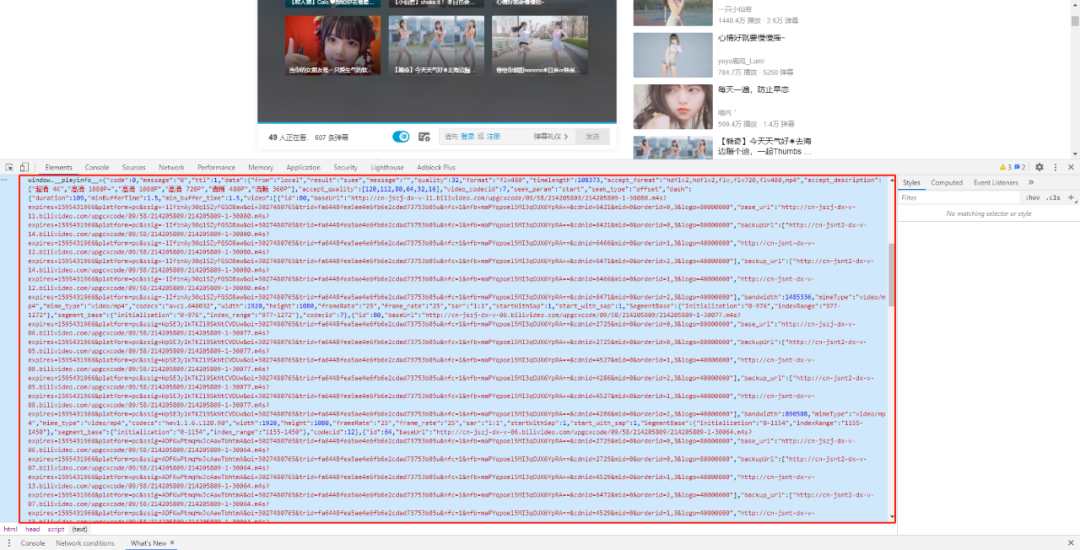
获取标题和链接
抓取视频页面,并用 BeautifulSoup 模块解析页面,获取视频标题和链接(https://www.bilibili.com/video/BV17K4y1x7gs)。
def __init__(self, bv):# 视频页地址self.url = 'https://www.bilibili.com/video/' + bv# 下载开始时间self.start_time = time.time()def get_vedio_info(self):try:headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36'}response = requests.get(url = self.url, headers = headers)if response.status_code == 200:bs = BeautifulSoup(response.text, 'html.parser')# 取视频标题video_title = bs.find('span', class_='tit').get_text()# 取视频链接pattern = re.compile(r"window\.__playinfo__=(.*?)$", re.MULTILINE | re.DOTALL)script = bs.find("script", text=pattern)result = pattern.search(script.next).group(1)temp = json.loads(result)# 取第一个视频链接for item in temp['data']['dash']['video']:if 'baseUrl' in item.keys():video_url = item['baseUrl']breakreturn {'title': video_title,'url': video_url}except requests.RequestException:print('视频链接错误,请重新更换')
示例结果:
{'title': '《属于周杰伦的情歌王2.0》安安静静的回忆有杰伦陪伴的20年','url': 'http://cn-jszj-dx-v-06.bilivideo.com/upgcxcode/34/57/214635734/214635734_nb2-1-30080.m4s?expires=1595538100&platform=pc&ssig=Q5uom_rGdPasJhHBvna8tw&oi=3027480765&trid=347f5dc41e9647e2a6dce48286d0b478u&nfc=1&nfb=maPYqpoel5MI3qOUX6YpRA==&cdnid=2725&mid=0&cip=222.186.35.71&orderid=0,3&logo=80000000'}
下载视频
下载视频使用 urllib 模块的 urlretrieve(url, filename=None, reporthook=None) 方法,它可以将远程数据直接下载到本地。
def download_video(self, video):title = re.sub(r'[\/:*?"<>|]', '-', video['title'])url = video['url']filename = title + '.mp4'opener = urllib.request.build_opener()opener.addheaders = [('Origin', 'https://www.bilibili.com'),('Referer', self.url),('User-Agent', 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36')]urllib.request.install_opener(opener)urllib.request.urlretrieve(url = url, filename = filename)
示例结果:
一个视频下载完成。
进度条
现在还缺一个进度条,没有进度条的下载工具是一个没有灵魂的下载工具。

def schedule(self, blocknum, blocksize, totalsize):'''urllib.urlretrieve 的回调函数:param blocknum: 已经下载的数据块:param blocksize: 数据块的大小:param totalsize: 远程文件的大小:return:'''percent = 100.0 * blocknum * blocksize / totalsizeif percent > 100:percent = 100s = ('#' * round(percent)).ljust(100, '-')sys.stdout.write("%.2f%%" % percent + '[ ' + s +']' + '\r')sys.stdout.flush()
示例结果:
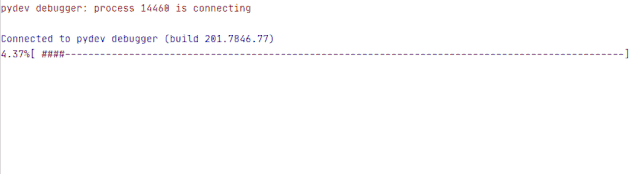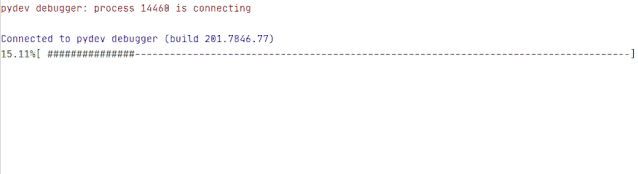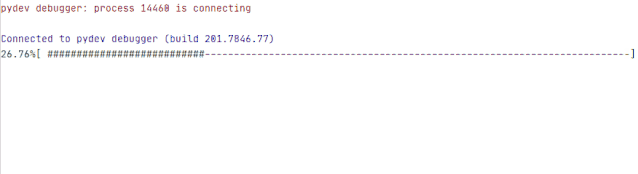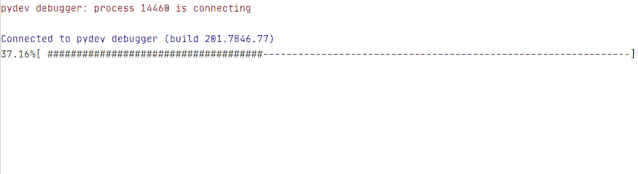
最后更新一下下载视频的代码,加入 reporthook 参数。
urllib.request.urlretrieve(url = url, filename = filename, reporthook = self.schedule)总结
简单的一个 B 站视频下载工具到这就完成了,有兴趣的话大伙可以试试下载 B 站的番剧,似乎和普通的视频不一样。
PS:公号内回复「Python」即可进入Python 新手学习交流群,一起 100 天计划!
老规矩,兄弟们还记得么,右下角的 “在看” 点一下,如果感觉文章内容不错的话,记得分享朋友圈让更多的人知道!


【代码获取方式】
识别文末二维码,回复:200727