
送书 | 教你下载B站指定视频
大家好!我是啃书君!
不知道大家有没有下载自己喜欢的视频的习惯,反正我就有。众所周知,b站是一个很好的学习知识平台,我们可以在b站学习各种各样的知识,但唯一的不足是b站没有提供下载视频的功能,遇到喜欢的只能点赞、关注、收藏,那么我们想下载指定的视频该怎么办呢,今天将教你下载b站指定视频!!!
爬前准备
在爬前指定视频数据并下载指定视频之前,我们需要用到以下库、模块、第三方工具:
requests库:用来发送网络请求;
os模块:用来处理文件和目录;
parsel库:是Scrapy 开发团队开源的一个支持 XPath和 CSS 选择器语法的网页解析库,用来将文本数据转换为XPath可以解析的HTML文本;
re库:正则解析库,主要用于字符串匹配;
FFmpeg第三方工具:用来记录、转换数字音频、视频,并能将其转化为流的开源第三方工具,我们这里主要用来纯音频和纯视频的拼接。
相信大家对上面前四个库与模块已经很熟悉了,安装方式也很简单,执行pip install 库名即可,所以这里我们主要介绍FFmpeg第三方工具。
FFmpeg第三方工具简介
FFmpeg是一套可以用来记录、转换数字音频、视频,并能将其转化为流的开源第三方工具。它包括了领先的音/视频编码库libavcodec等。可以轻易地实现多种视频格式之间的相互转换。包括如下几个部分:
libavformat:用于各种音视频封装格式的生成和解析,包括获取解码所需信息以生成解码上下文结构和读取音视频帧等功能;
libavcodec:用于各种类型声音/图像编解码;
libavutil:包含一些公共的工具函数;
libswscale:用于视频场景比例缩放、色彩映射转换;
libpostproc:用于后期效果处理;
ffmpeg:该项目提供的一个工具,可用于格式转换、解码或电视卡即时编码等;
ffsever:一个 HTTP 多媒体即时广播串流服务器;
ffplay:是一个简单的播放器,使用ffmpeg 库解析和解码,通过SDL显示;
ffprobe:收集多媒体文件或流的信息,并以人和机器可读的方式输出。
FFmpeg第三方工具就介绍到这里,下面我们开始安装与配置FFmpeg
FFmpeg第三方工具安装与配置
首先我们进入FFmpeg官网,如下图所示:

注意:这里有个小坑,就是可能有不少人会直接点击Download Source Code并进行下载,下载并解压后,得到的是其源代码及一些配置程序,如下图所示:

这些文件和程序对我们没多大用,我们需要的是包和可执行文件。
下载包和可执行文件
点击Download Source Code并进行下载得到的是源代码,我们需要的是包和可执行文件,所以正确的下载方式如下图所示:

大家可以根据自己的操作系统来下载对应的压缩包,点击图中的3后,就会跳转如下网页:

我们往下拉页面找到release builds,如下图所示:
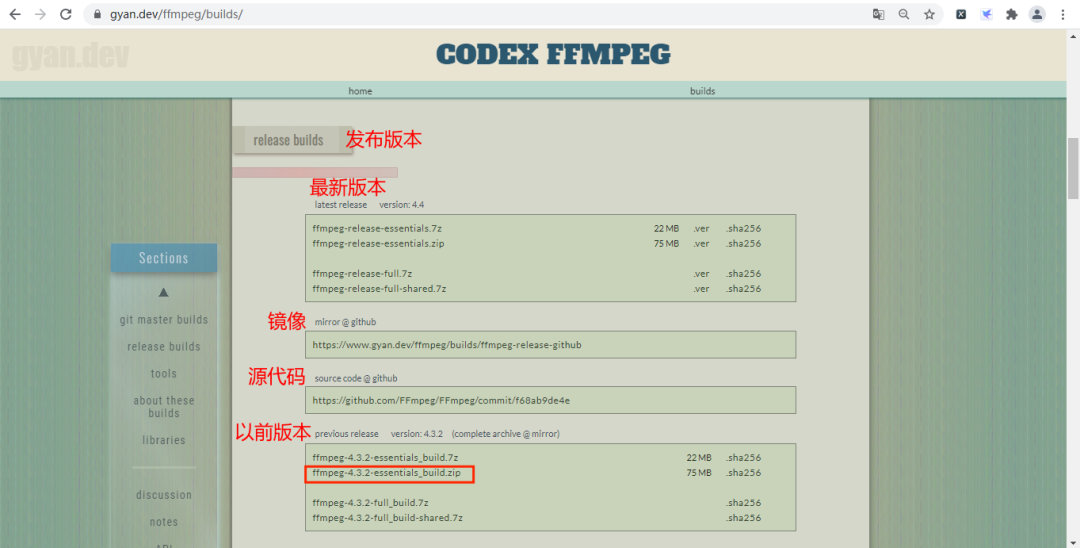
我这里是下载以前版本的压缩包,如上图的红框所示,下载完毕,解压文件,进入bin目录。如下图所示:

设置环境变量
只下载包和可执行文件是没多大用的,我们还需要设置环境变量,设置环境变量方法很简单。
首先进入刚刚解压的文件,进入bin目录,把其路径复制下来,如下图所示:
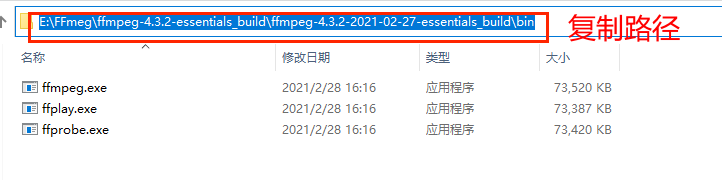
然后点击“系统属性->环境变量->系统变量”,选择“Path”条目,点击“编辑->新建”,把刚才的bin文件夹路径复制粘贴进去,点击确定即可。如下图所示:

好了,环境变量已经设置好了,接下来开始测试FFmpeg是否安装并配置成功。
我们打开cmd命令行窗口,输入命令“ffmpeg –version”。窗口返回ffmpeg的版本信息,说明安装成功,如下图所示:

好了,FFmpeg第三方工具的安装和配置就讲到这里,接下来我们正式开始爬取工作。
网页分析
首先我们进入b站,随便点击一个愉悦视频并打开开发者工具,如下图所示:

通常情况下,我们通过检查元素来定位页面的数据信息的存放位置,如下图所示:

假如左边的红框是一张图片的话,我们很容易就可以在右边的红框找到其图片的URL链接,经过一番的寻找,并没有发现对我们有用的视频URL链接,那么怎么办好呢,是不是爬不了了。
这时我们可以换个思路,一般情况下,几乎所有的视频网站都可以选择视频清晰度来播放,如下图所示:
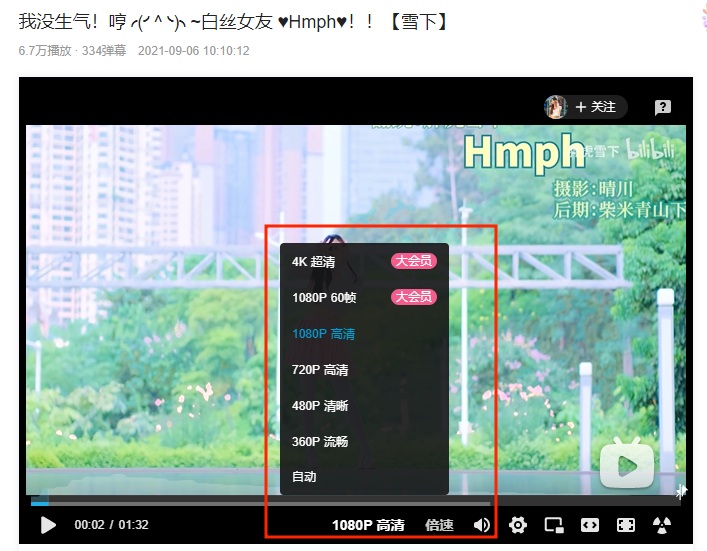
那么我们可以考虑尝试在代码元素中搜索超清,看看能不能搜到和视频链接相关的数据,如下图所示:
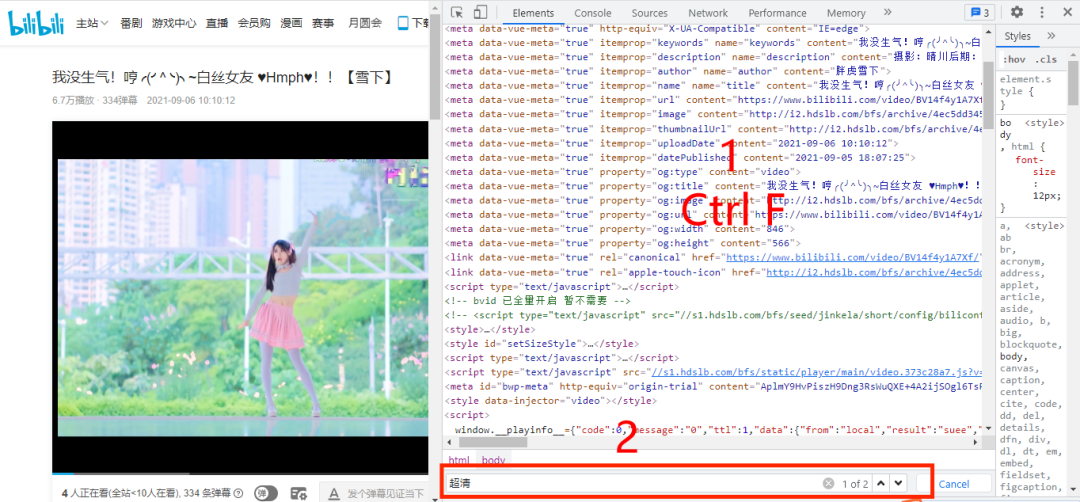
我们发现搜索超清有两个匹配项,经过简单的判断,我们发现第一个匹配项中有个参数名为window.playinfo,翻译出来的大概意思是播放信息,播放信息中,一般都会存放播放视频的url链接,经过简单的查找,果然在里面找到我们的想要的url链接,如下图所示:

细心的小伙伴就发现了id的参数值对应着视频的清晰度,其中,超清4k对应的id值为120,高清1080P60对应的id值为116,由于我们不是b站的大会员,最高清晰度只能选择1080P高清,所以对应的id为80。
图中方框的video表示视频,那么问题来了,那audio音频在哪里找呢?我们继续用刚才的搜索方法,搜索audio,如下图所示:
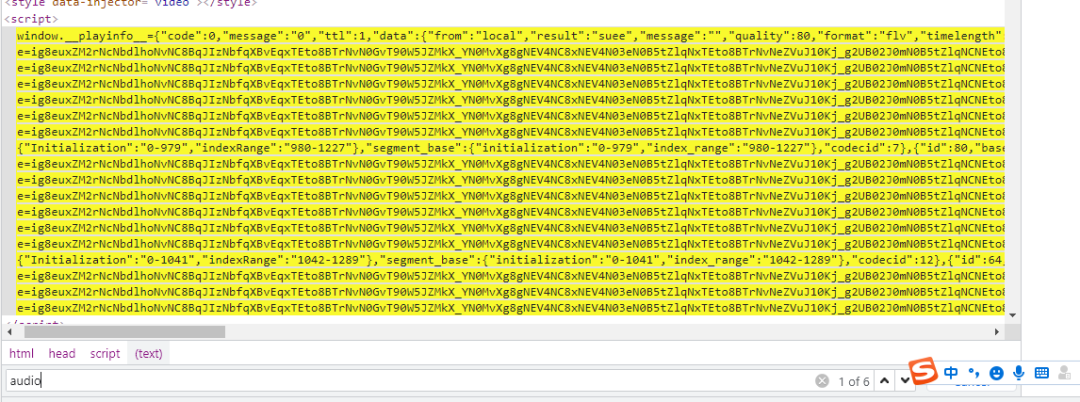
我们发现,audio音频的存放位置是在我们刚才找到的video存放位置之中,这样就好办了,现在video视频和audio音频的URL链接都知道在哪里了,接下来我们正式开始编写爬虫来下载我们想要的视频。
实战演练
我们的基本爬取并下载视频的思路是:
发送网络请求;
提取视频的名字、video纯视频链接和audio纯音频链接;
下载video纯视频和audio纯音频;
拼接完整的视频。
发送网络请求
首先我们发送网络请求,发送网络请求最重要的是什么,没错就是要有URL链接,那么URL链接是哪个呢,URL链接就是我们视频页的URL链接,如下图所示:

具体代码如下所示:
url = 'https://www.bilibili.com/video/BV17U4y1j7Sz?spm_id_from=333.851.b_7265636f6d6d656e64.6'
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36',
'referer': url
}
def get_parse():
response = requests.get(url, headers=headers)
data = response.text
get_data(data)
首先我们创建一个变量url来存放发送网络请求的URL,再定义get_parse()方法来发送网络请求、获取响应数据并将数据传递给自定义的get_data()方法中。当我们想要下载其他的视频时,只要修改url链接即可。
提取视频名及获取视频音频URL
在上一步中,我们成功发送了网络请求并将网络请求响应数据返回到自定义方法get_data()中,接下来我们将提取视频名及视频音频的URL链接,具体代码如下所示:
def get_data(data):
Xpath = parsel.Selector(data)
title = Xpath.xpath('//*[@id="viewbox_report"]/h1/span/text()').extract_first()
playinfo = Xpath.xpath('/html/head/script[5]/text()').extract_first()
video_url = re.findall(r'"video":.*?,"baseUrl":"(.*?)",', playinfo)[0]
audio_url = re.findall(r'"audio":.*?,"baseUrl":"(.*?)",', playinfo)[0]
download(video_url,audio_url,title)
首先利用parsel.Selector()方法把get_data()接收到的文本数据转换为XPath可以解析的HTML文本并通过xpath来把视频名和播放信息提取出来,再通过正则表达式将纯视频URL链接和纯音频URL链接提取出来,注意re.findall()返回的是列表,所以我们通过[0]来获取列表中的数据,这样我们得到的就是字符串。最后把视频名和纯视频音频的URL传递给自定义方法download()中。
下载视频音频
在上一步中,我们成功提取并传递视频名和纯视频音频的URL到自定义方法download()中,接下来就要下载视频了,具体代码如下所示:
def download(video_url,audio_url,title):
video = requests.get(video_url, headers=headers).content
audio = requests.get(audio_url, headers=headers).content
title_new = title + "纯"
with open(f'{title_new}.mp4', 'wb')as f:
f.write(video)
with open(f'{title_new}.mp3', 'wb')as f:
f.write(audio)
Splicing(title)
首先我们通过在上一步获取到的URL链接发送网络请求并返回响应的字节码,再定义一个变量来对下载的纯视频音频进行命名,然后将纯视频的字节码和纯音频的字节码写入文件中,最后将视频名和title_new传递到自定义方法Splicing()中。
不知道大家有没有注意到,就是我们在第一步发送网络请求中,headers请求头中有一个参数referer,这个参数我们一般称为防盗链。这里一定要添加referer。
图中的错误意思简单来说就是无法拼接已经损坏或无内容的纯音频和纯视频,我们查看刚下载的纯视频纯音频文件,如下图所示:

我们发现刚下载的纯视频纯音频文件只有1KB的大小,但几乎没有视频音频是1KB的,所以很显然我们没有下载到视频音频。那么问题来了,明明一切很合乎常理,为什么会没有下载到视频音频呢。这里就和referer防盗链有关。
referer防盗链是一种简单的反爬机制,用来标识这个请求是从哪个页面发过来的,服务器可以拿到这一信息并做相应的处理,例如做来源统计、防盗处理等,假如没加防盗链,服务器就可能认为你的请求属于爬虫发送的,服务器就不给出响应。
那么如何正确添加referer的参数呢?referer的参数存放在网页的哪里呢?哪些网址可以作为referer参数呢?
在我看来,这三个地方的网址都可以作为referer参数,我们拿b站作为例子:
#b站首页网址
'referer':'https://www.bilibili.com/'
#要爬取页面的网址
'referer':'https://www.bilibili.com/video/BV14f4y1A7Xf?spm_id_from=333.851.b_7265636f6d6d656e64.6'
第三,Requeset Headers里面的referer,如下图所示:

这里我们直接用要爬取页面的网址作为referer的参数。
拼接完整的视频
在上一步中,纯音频纯视频已经下载后了,接下来我们开始把视频音频拼接起来,拼接方法很简单,具体代码如下图所示:
def Splicing(title,title_new):
os.system(f'ffmpeg -i "{title_new}.mp4" -i "{title_new}.mp3" -c copy "{title}.mp4"')
os.remove(f'{title_new}.mp4')
os.remove(f'{title_new}.mp3')
首先调用os.system方法,再利用ffmpeg第三方工具,其中
-i 文件名表示输入文件,也就是存在你要拼接的文件;
-c copy 文件名表示输出文件,相当于将纯视频纯音频文件合并在一起并导出。
最后纯音频纯视频文件对我们已经没有什么用了,这时可以调用os.remove()方法把它们移除。
程序运行结果如下图所示:

结果展示

好了,下载b站指定的视频讲到这里了,感谢观看!!!
送书
本次送书《Python高效开发实战——Django、Tornado、Flask、Twisted(第3版)》,一书本着“纯碎干货,实用至上”的原则,让我们成为真正的全栈开发人才。
1、讲解Python Web开发,必定离不开HTTP。有多少人知道HTTP的工作流程呢?
2、我们访问网站,网站服务器把内容反馈给我们。网站服务器是什么?
3、都说HTTP网站不安全,要变成HTTPS的。如何建立HTTPS网站?
本文就针对以上问题做简单解答。

本书分为3篇:上篇是Python基础,带领初学者实践Python开发环境,掌握基本语法,同时对网络协议、Web客户端技术、数据库建模等网络编程基础进行深入浅出的学习;中篇是Python框架,学习当前***的Python Web框架,即Django、Tornado、Flask和Twisted,达到对各种Python网络技术融会贯通的目的;下篇是Python框架实战,分别使用4种框架进行项目实践,利用其各自的特点开发适用于不同场景的网络程序。本书内容精练、重点突出、实例丰富、讲解通俗,是广大网络应用设计和开发人员不可多得的一本参考书。
公众号回复:送书 ,参与抽奖(共3本)
点击下方回复:送书 即可!
大家如果有什么建议,欢迎扫一扫二维码私聊小编~
回复:加群 可加入Python技术交流群
你的点【赞】,会让我知道,你们就是那个一直陪着我努力的人。