
视频超分|SOF-VSR
点击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达

paper: https://arxiv.org/abs/2001.02129
code: https://github.com/LongguangWang/SOF-VSR
Abstract
视频超分旨在生成具有与LR时序一致性且视觉效果更好的高分辨率图像。视频超分的关键挑战在于:如何更有效的利用连续帧间的时序信息。现有的深度学习方法通常采用光流方法从LR图像上估计时序信息,低分辨率的光流会影响HR图像的细节复原效果。
该文提出了一种端到端的视频超分方法,它同时对光流与图像进行超分,光流超分开源提供更精确的时序信息进而提升视频超分的性能。作者首先提出一种光流重建网络(OFRNet)以“自粗而精”的方式预测HR光流,然后采用HR光流进行运动补偿编码时序信息,最后采用补偿后的LR图像送入超分网络(SRNet)生成超分结果。
作者通过充分的实验验证了HR光流对于超分性能提升的有效性,所提方法在Vid4与DAVIS10数据集上取得了SOTA性能。
该文的贡献包含以下几点:
将光流与图像的超分集成到统一的SOF-VSR框架中,光流超分有助于提升图像超分性能; 提出一种OFRNet采用“自粗而精”的方式从LR图像中预测HR光流,它有助于重建更精确的时序信息; 在公开基准数据集(Vid4,DAVIS10)上,所提SOF-VSR取得了SOTA性能。
Method
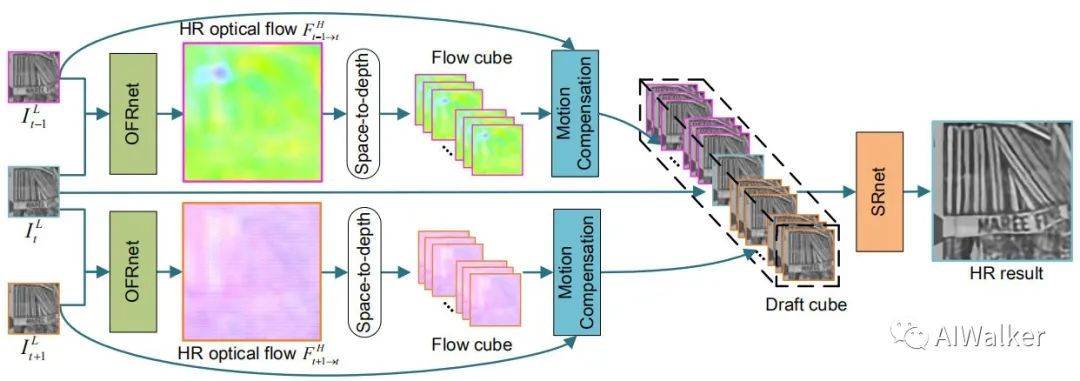
上图给出了所提方法的流程图,它包含光流估计模块、运动补偿模块以及图像超分模块。接下来,我们将从四个方面进行展开介绍与分析(OFRNet、运动补偿、SRNet以及损失函数)。
这里我们先给出关于视频超分的定义,给定帧连续LR序列,视频超分的目标是对中间帧进行超分重建。在该文中,作者首先将输入由RGB空间转为YCbCr,仅针对Y通道进行超分。LR图像序列首先送入OFRNet中预测HR光流,它采用中间帧以及近邻帧作为输入,预测HR光流,然后采用采用space-to-depth将HR光流变换到低分辨率,得到LR光流体;下一步采用所得光流进行运动补偿;最后补偿后的LR图像将送入SRNet进行HR图像重建。
OFRNet
作者设计了一种CNN网络用于从LR图像中直接预测HR光流,它以成对图像(中间帧以及近邻帧)作为输入,输出HR光流,该过程可以描述为:
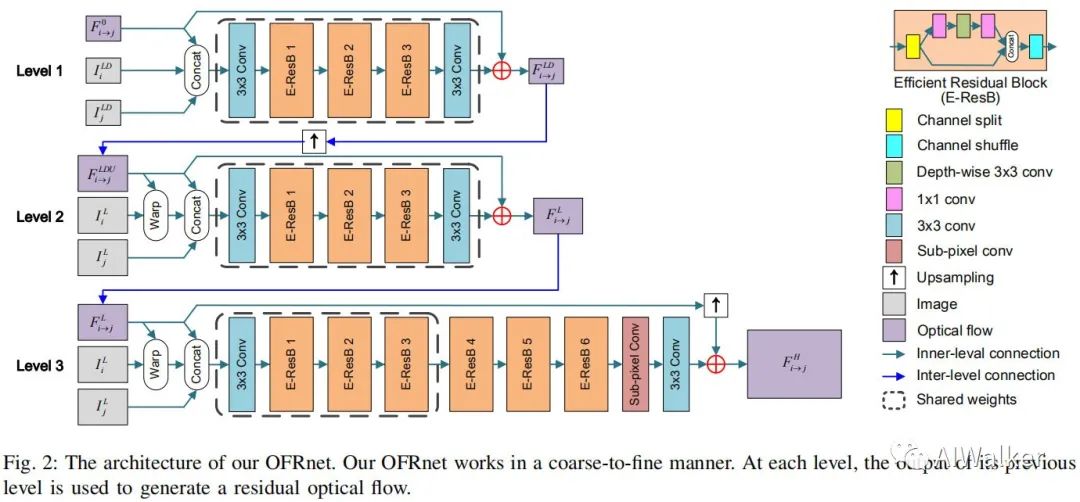
为降低模型大小以及训练难度,作者采用了尺度递归架构,见上图。在前两级作者采用递归模块估计不同尺度的光流信息,在第三级作者首先采用递归架构生成深度表达,然后引入SR模块重建HR光流。这种尺度递归架构有助于OFRNet处理复杂的运动,同时使得模型更轻量。
Motion Compensation Module
通过OFRNet得到HR光流后,作者通过space-to-depth变换对HR光流与LR图像进行桥接,见下图。注:光流的幅值需要除以s以匹配LR图像的空间分辨率。
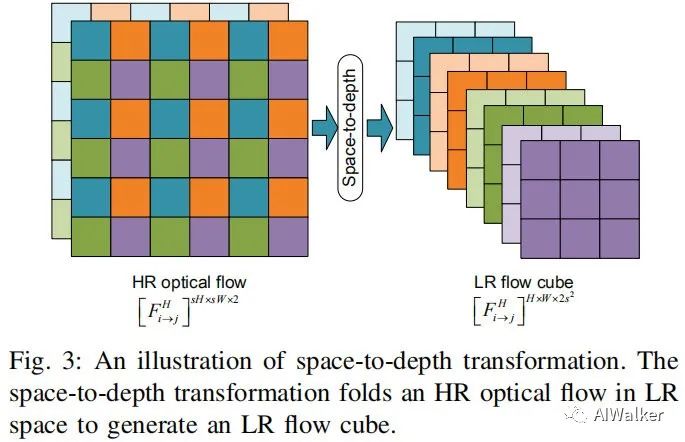
基于上述变换后的LR光流对LR图像进行运动补偿,补偿过程可以描述为:
其中表示双线性插值仿射变换操作,表示concat后的结果。可以看到:尽管是在LR层面进行的运动补偿,但HR光流的时序信息均被编码到了补偿帧。
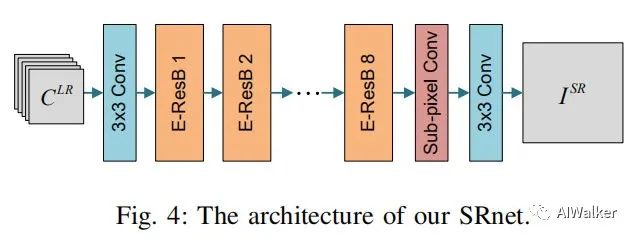
SRNet
SRNet采用帧LR图像作为输入,并对中间帧进行超分。完成运动补偿后,将每个近邻帧的补偿帧通过concat进行组合并送入到SRNet中进行图像重建,该过程可以描述为:
其中表示超分结果,表示运动补偿后的LR输入以及中间帧输入。下图给出了SRNet的网络结构示意图。
Loss Function
作者分别针对SRNet和OFRNet设计了损失函数,它们分别是:
其中用于约束光流的平滑性,作者设置超参为。联合训练的损失函数定义如下:
其中。
Experiments
训练数据:作者选用了CDVL,测试数据为Derf4、Vid4以及DAVIS。评价准则:PSNR、SSIM以及MOVIE。下图给出了所提方法在Vid4上的参数量与FLOPS以及指标。
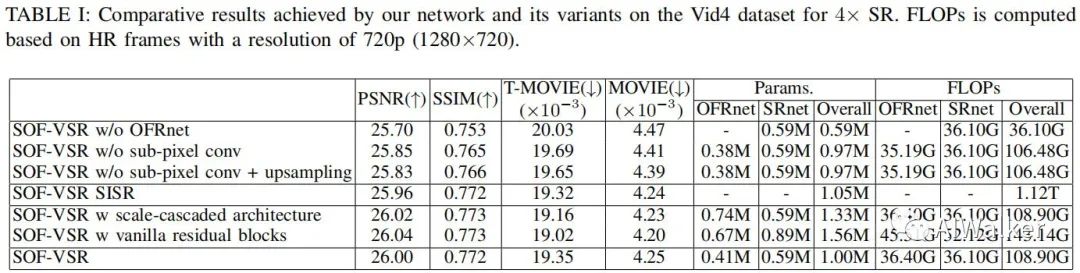
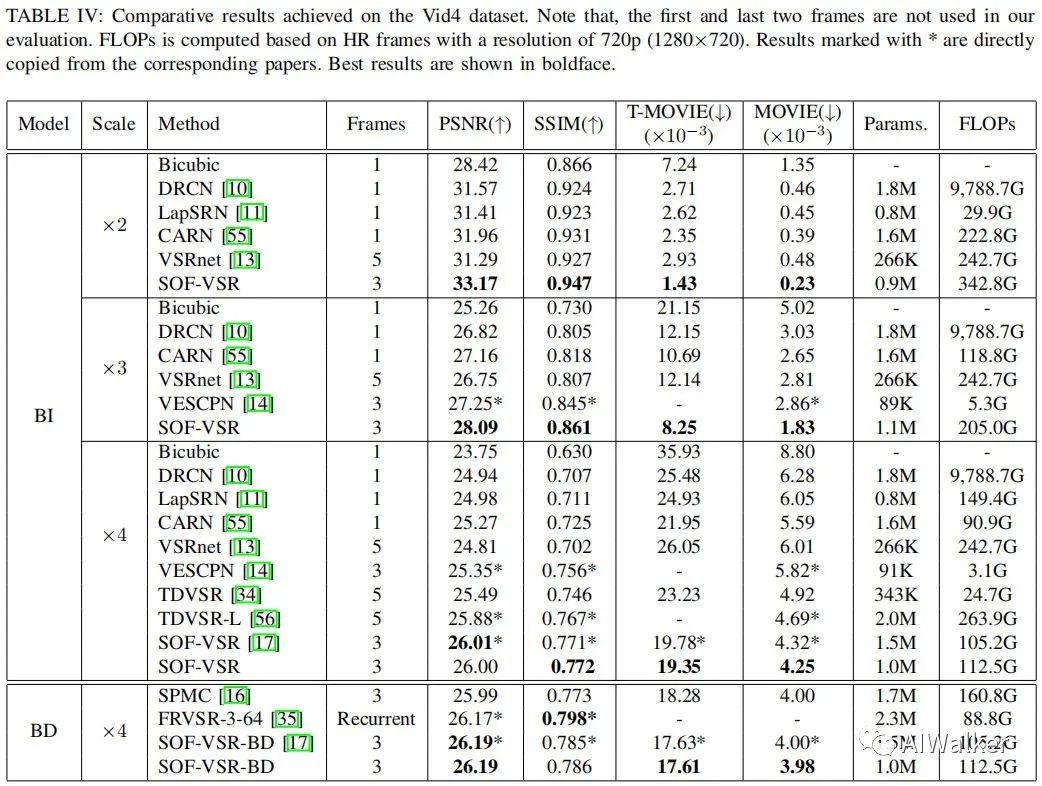
下表给出了所提方法与其他视频超分方法的在Vid4数据集上性能对比

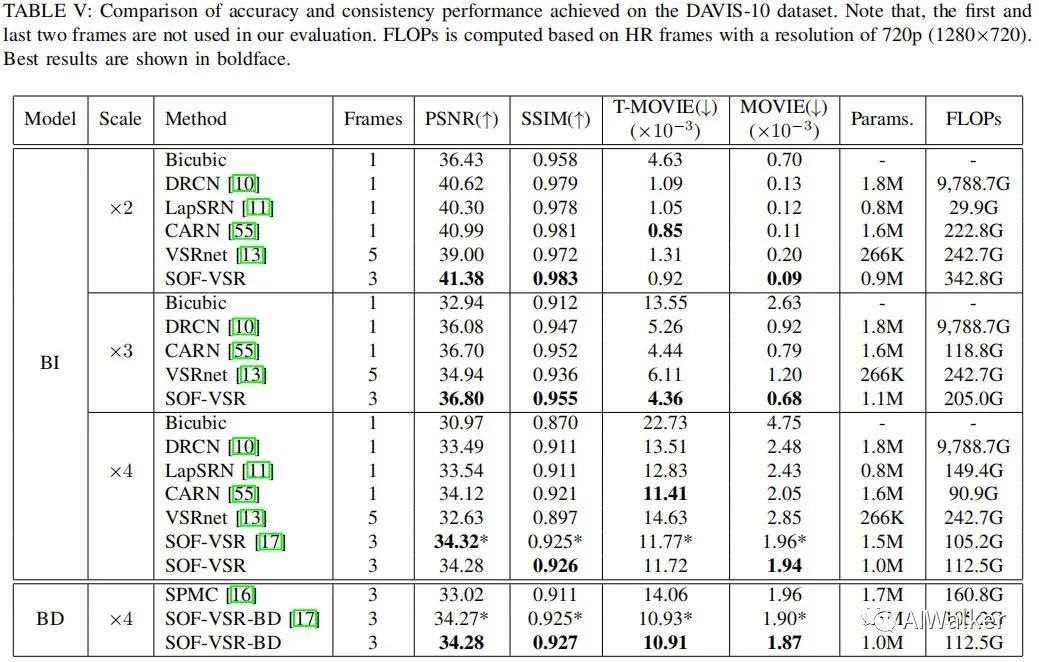
下表给出所提方法与其他视频超分方法在DAVIS10数据集上的性能对比。

全文到底结束,更多详细实验分析建议查看原文,不再赘述.
觉得有用,给个在看哦!