
神仙打架丨NTIRE2021视频超分挑战双赛道方案

极市导读
NTIRE2021近日已经落下帷幕,BasicVSR++和OVSR在比赛中都有非常两眼的表现,可谓是神仙打架。本文回顾了比赛中五个团队的方案以及对视频超分的新进展。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
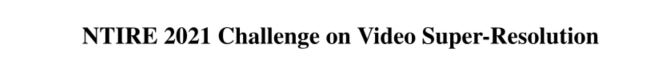
论文链接:https://arxiv.org/pdf/2104.14852.pdf
比赛链接:https://competitions.codalab.org/competitions/28051
译者言:NTIRE2021已于近日落下帷幕。BasicVSR++在VSR赛道摘得桂冠,同时它在Vid4的测试集中也突破了29dB的大关;OVSR模型在比赛中也有亮眼的表现,其他许多局部+全局的方案也取得了较高的PSNR值,可谓是神仙打架。相比之下,STSR赛道并没有特别突出的方法。下文将会回顾这场比赛中两个赛道对视频超分的新进展。
比赛简介
视频超分挑战共有两个赛道:Track 1是VSR任务,Track 2是STSR任务。分别有247名和223名参赛者报名。使用REDS中24,000, 3,000和3,000HD视频作为训练,验证和测试集。数据集地址:https://seungjunnah.github.io/Datasets/reds.html.
Track 1:VSR:使用MATLAB imresize函数的生成×4的LR帧。目标是从LR序列(24fps)中重建HR视频。
Track 2:STSR:从Track 1的LR视频中去掉奇数帧(12fps)来作为STSR问题的输入。目标是执行STSR并从LR输入重建24fps的地面真实值视频。要求参与者在训练Track 2方法时不许使用Track 1中的奇数帧。
度量与评价:采用PSNR和SSIM两个标准度量来评估提交的方法。根据PSNR分数的排序,以确定胜利者。本文还提供了LPIPS分数来定量测量结果图像的感知质量。

方法与团队
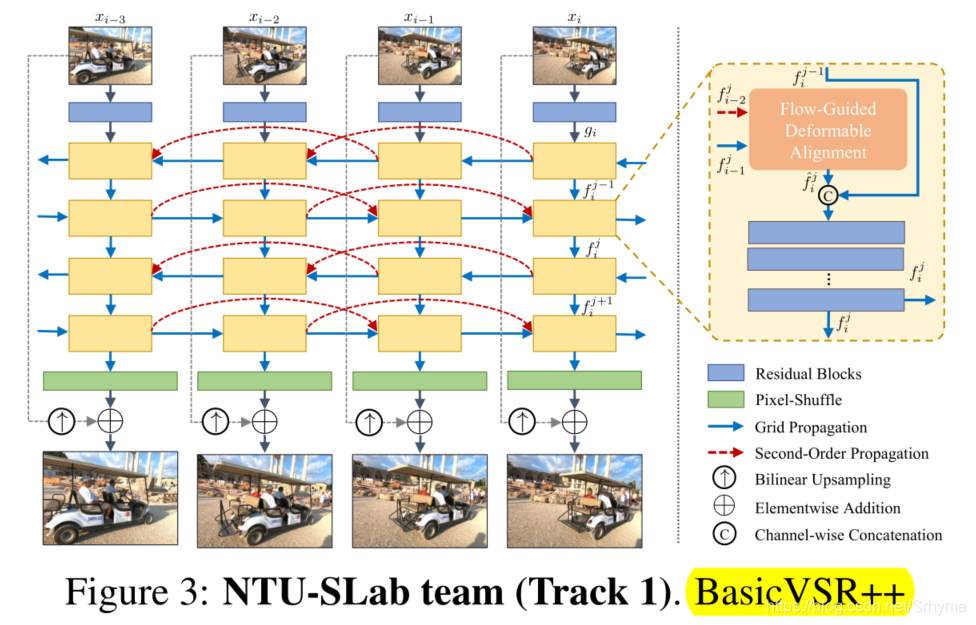
NTU-SLab:BasicVSR++
南洋理工大学NTU-SLab团队提出了BasicVSR++框架,它采用与BasicVSR相同的基本方法,通过引入二阶网格传播和流动引导变形对准对传播和对准方法进行了改进。下图显示了BasicVSR++的总体架构。利用残差块从图像中提取特征序列,并采用二阶网格传播算法进行传播。在传播块内部,添加了流可变形对准模块以获得更好的性能。为了克服特征在BasicVSR中只能传播一次的限制,二阶网格传播方案可以对特征进行多次细化。通过多个双向传播层,重新访问不同时间步长的特征,使每个特征包含更多有用的信息。
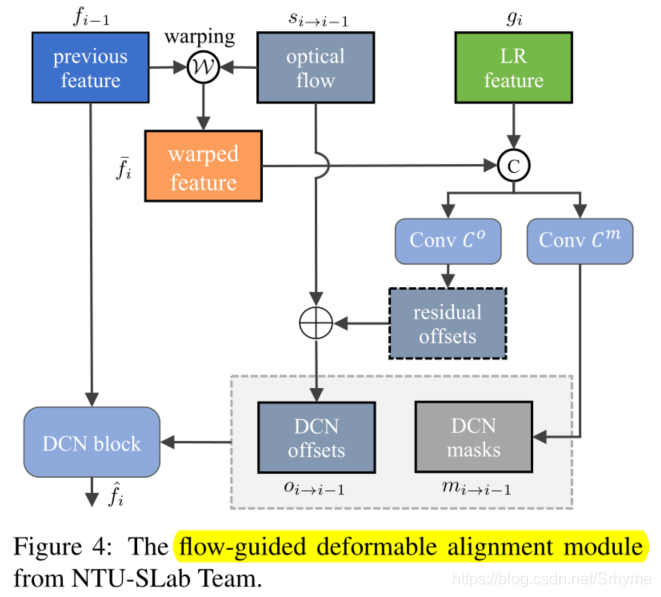
流导向可变形对齐使用可变形卷积代替基于流的对齐。由于可变形卷积具有偏移分量,因此其性能优于基于流的对齐。该方法利用光流来减轻可变形卷积的训练不稳定性。流导向可变形对准的体系结构如图4所示。
目前论文已经发表在预发表平台,链接:https://arxiv.org/pdf/2104.13371.pdf.
Imagination team:LCVR+MQVI
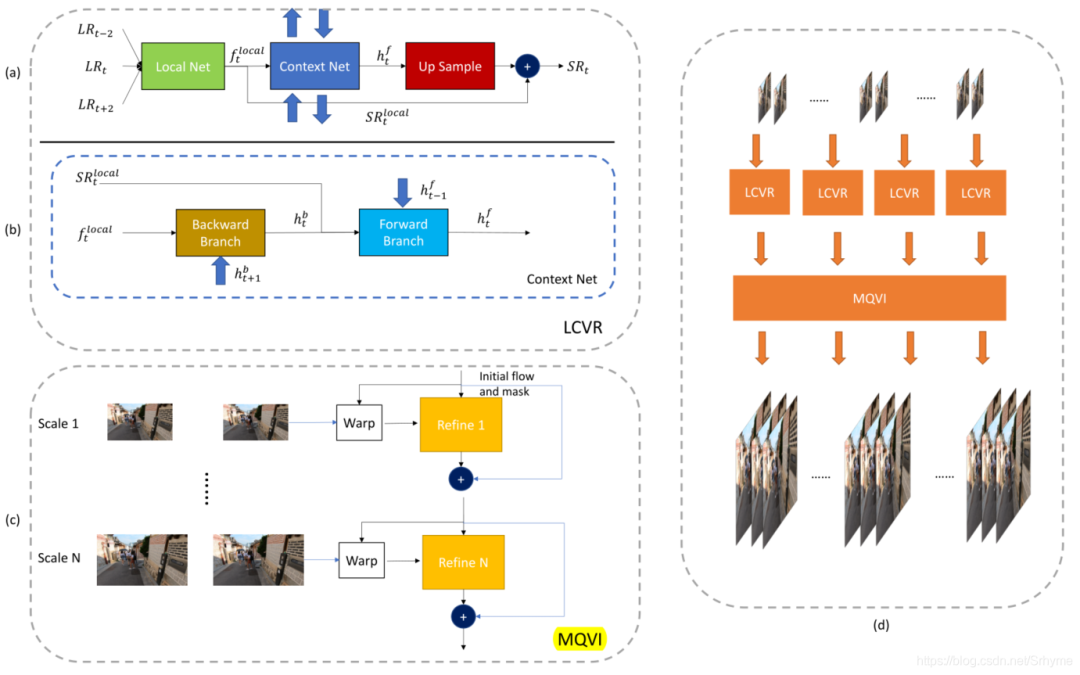
腾讯优图实验室和华东师范大学Imagination团队提出了一种局部到上下文的视频超分(LCVR)方法,并将其与多尺度二次视频插值(MQVI)相结合进行STSR。LCVR框架包括三个模块:局部模块、上下文模块和上采样模块。局部模块使用带有通道注意的EDVR网络生成局部特征和超分辨帧。上下文网模块由前后分支组成,其输出通过上采样模块转换为残差帧,与局部模块的输出相加得到最后的SR帧。采用附加的自集成策略使性能提高了0.2dB。LCVR框架如下图所示。
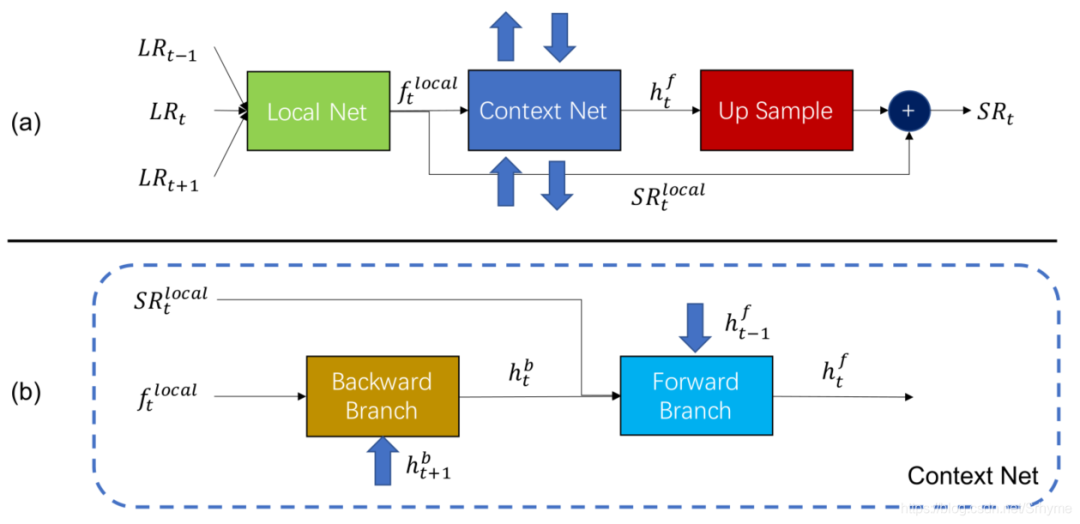
在STSR中,MQVI模块连接在LCVR模块之后。首先,由LCVR模块生成偶数帧的SR图像,然后使用MQVI模块进行插值生成奇数帧。该文采用二次帧插值,因为它可以处理比线性帧插值更复杂的运动。此外,还应用了多尺度结构以从粗到细的方式细化特征。MQVI和总体的结构如下图所示。
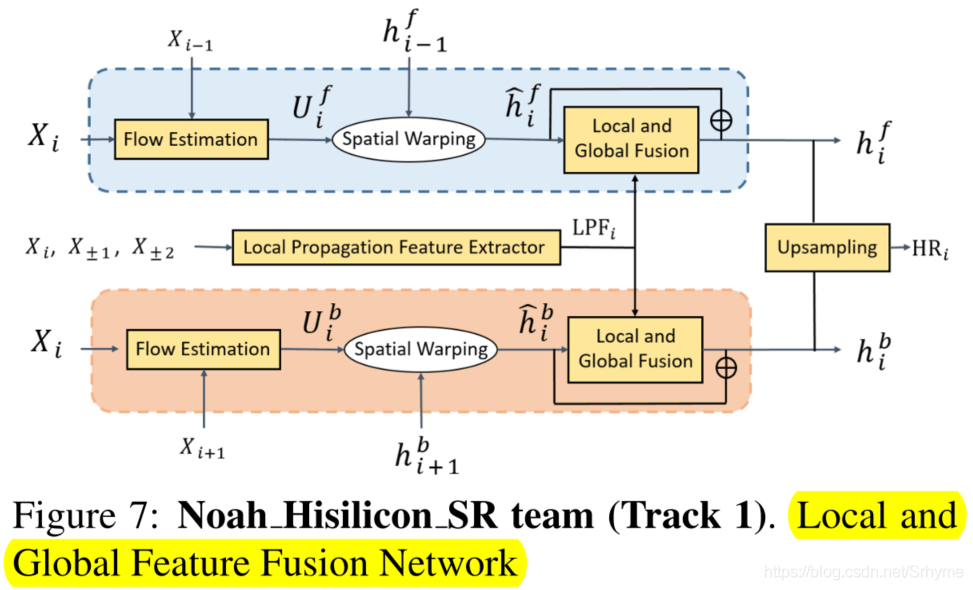
Noah_Hisilicon_SR:LGFFN
诺亚方舟实验室与华为海思科技的Noah_Hisilicon_SR团队提出了局部和全局特征融合网络(LGFFN)。在BasicVSR框架的基础上将全局传播特征和局部传播特征相结合,结构如下图所示。
VUE
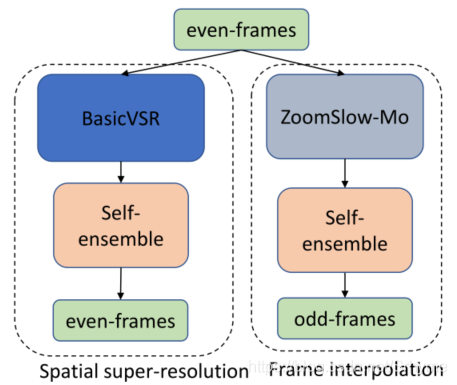
百度计算机视觉部门的VUE团队提出了两阶段算法。在Track 1中,两个阶段都使用BasicVSR模型,首先生成粗超分辨图像,然后通过第二个网络进行细化。在这两个阶段中,为了获得更好的性能,采用了自集成。
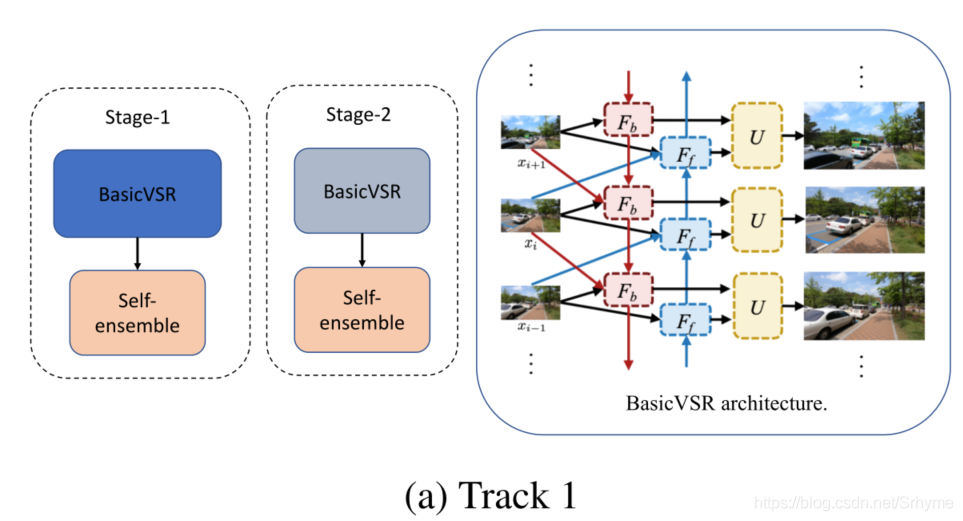
在Track 2中,两个阶段并行运行,第二阶段用ZoomSlow-Mo模型代替。BasicVSR模型估计偶数帧的超分辨输出,而ZoomSlow-Mo模型估计奇数帧的超分辨输出。为了获得更高的峰值信噪比,两级都采用了自集成。
Other
武汉大学的NERCMS团队提出了全知视频超分辨率网络(OVSR)来进行VSR任务,论文链接:https://arxiv.org/pdf/2103.15683。电子科技大学的Diggers团队使用BasicVSR来进行VSR任务,他们的耗时最小,仅为1.2。其他改进的BasicVSR方法时间则是成倍提成,如BasicVSR++为7.3。LPIPS最高的STSR方法来自京东方科技研发中心的BOE-IOT-AIBD团队,他们采用两阶段的方法,使用EDVR作为视频超分网络,采用多尺度二次插值(MSQI)作为时间超分辨率网络。其他方法还有使用以RBPN、EDVR、PFNL等为基础架构的模型,它们的性能等并不出众。
本文亮点总结
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“79”获取CVPR 2021:TransT 回放及PPT~
深度学习环境搭建:个人深度学习工作站配置指南|深度学习主机配置推荐
实操教程:用OpenCV的DNN模块部署YOLOv5目标检测|TensorRT的FP16模型转换教程
算法技巧(trick):17种提高PyTorch“炼丹”速度方法|PyTorch Trick集锦|深度学习调参tricks总结
最新CV竞赛:2021 高通人工智能应用创新大赛|CVPR 2021 | Short-video Face Parsing Challenge

# 极市原创作者激励计划 #
