
RTX3090 时代最新GPU选购指南:哪款显卡配得上我的炼丹炉?

极市导读
近日,华盛顿大学博士Tim Dettmers发表文章,就深度学习从业者如何选购GPU的问题发表了看法。

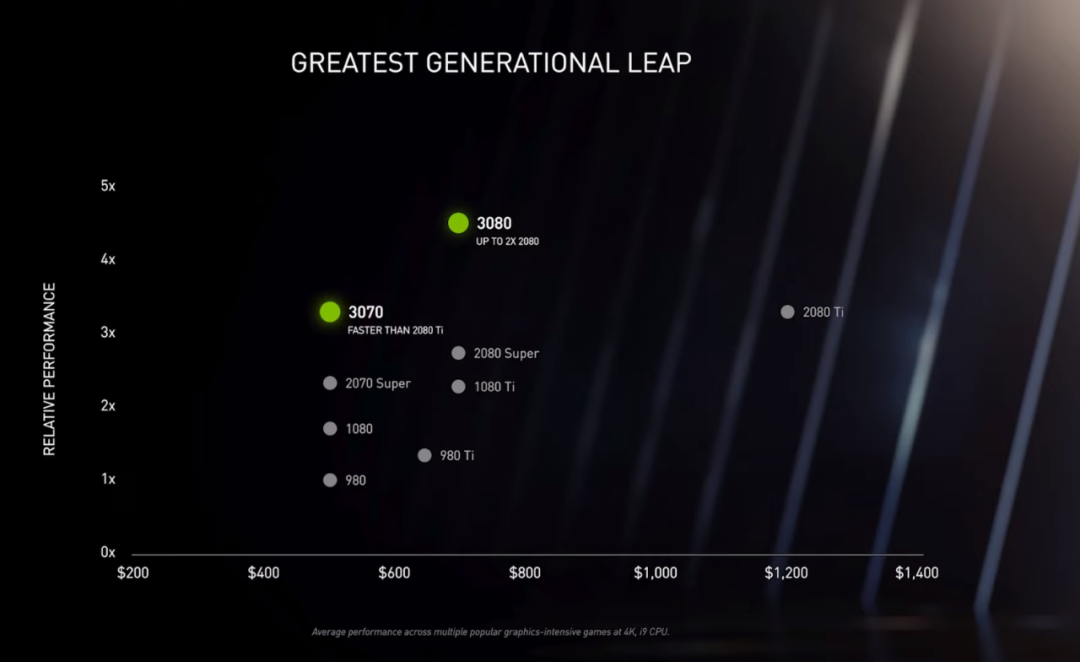
选择GPU时你需要知道的东西
SE-ResNeXt101:1.43 倍
Masked R-CNN:1.47 倍
Transformer(12 层机器翻译,在 WMT14 en-de 数据集上):1.70 倍

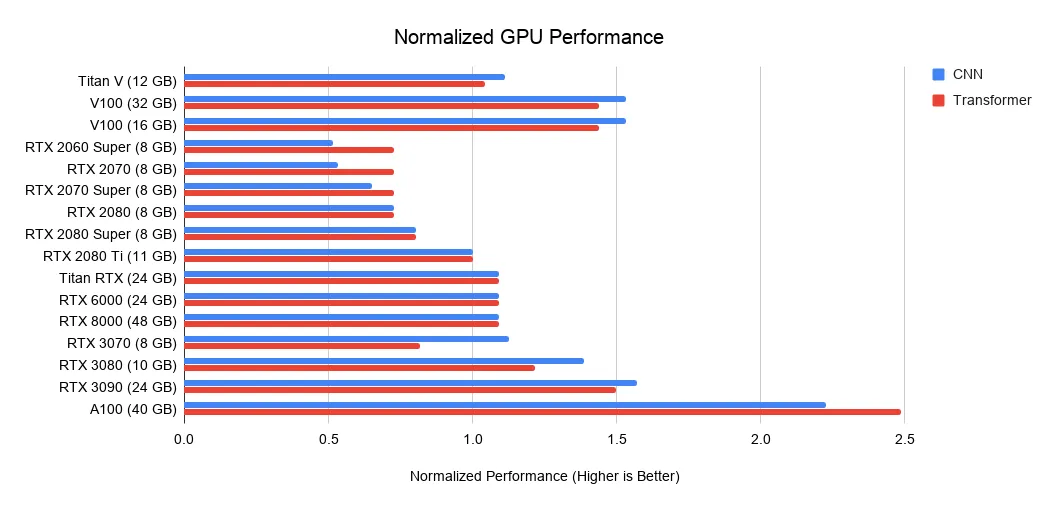
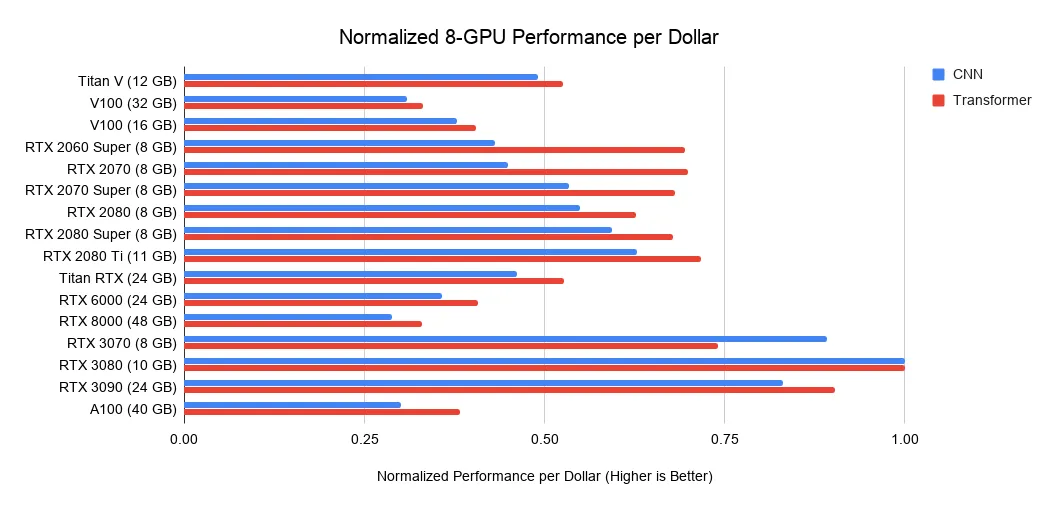
GPU深度学习性能排行
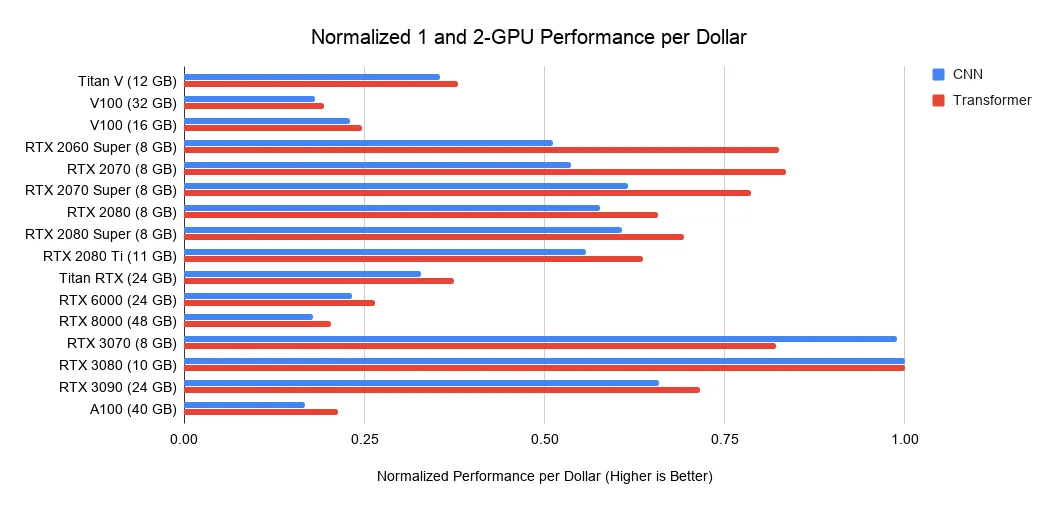
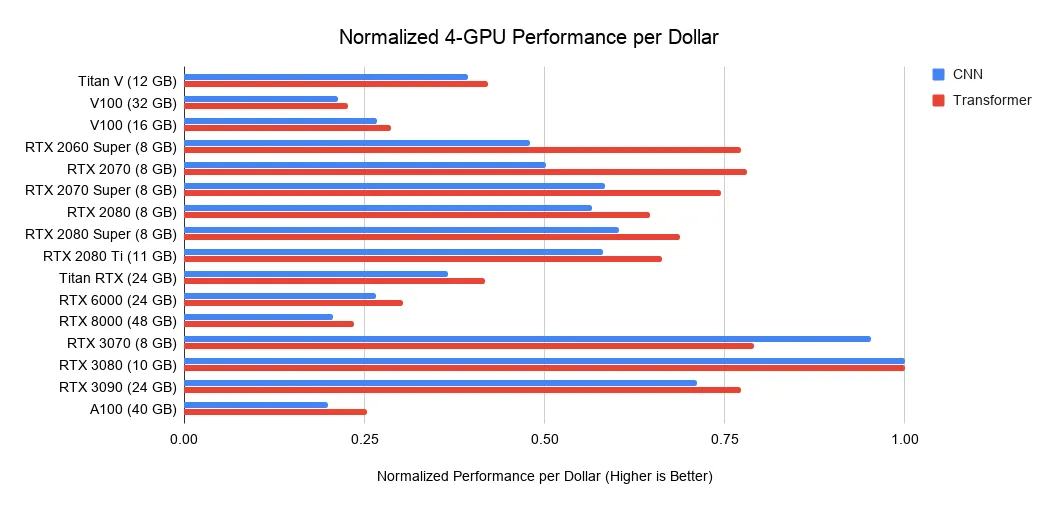
每一美元能买到多少算力?
使用预训练 transformer 和从头训练小型 transformer:>= 11GB;
训练大型 transformer 或卷积网络:>= 24 GB;
原型神经网络(transformer 或卷及网络):>= 10 GB;
Kaggle 比赛:>= 8 GB;
应用计算机视觉:>= 10GB。
GPU 购买建议
博士生个人台式机:<15%;
博士生 slurm GPU 集群:>35%;
企业级 slurm 研究集群:>60%。
长求总
作者简介

推荐阅读

评论