
又一款百度炼丹神器!
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达
在深度学习领域,有一个名词正在被越来越频繁地得到关注:迁移学习。它相比效果表现好的监督学习来说,可以减去大量的枯燥标注过程,简单来说就是在大数据集训练的预训练模型上进行小数据集的迁移,以获得对新数据较好的识别效果,因其能够大量节约新模型开发的成本,在实际应用中被更广泛地关注。基于此,百度EasyDL零门槛AI开发平台引入了超大规模视觉预训练模型,结合迁移学习工具,帮助开发者使用少量数据,快速定制高精度AI模型。
高质量数据获取难度高,迁移学习提升模型效果
在训练一个深度学习模型时,通常需要大量的数据,但数据的采集、标注等数据准备过程会耗费大量的人力、金钱和时间成本。为解决此问题,我们可以使用预训练模型。以预训练模型A作为起点,在此基础上进行重新调优,利用预训练模型及它学习的知识来提高其执行另一项任务B的能力,简单来说就是在大数据集训练的预训练模型上进行小数据集的迁移,以获得对新数据较好的识别效果,这就是迁移学习(Transfer Learning)。迁移学习作为一种机器学习方法,广泛应用于各类深度学习任务中。在具体实现迁移学习时,有多种深度网络迁移方法,其中的Fine-tune(微调)是最简单的一种深度网络迁移方法,它主要是将已训练好的模型参数迁移到新的模型来帮助新模型训练。
针对一个具体的模型开发任务,我们通常会选择在公开的大数据集上训练收敛、且效果较好的模型,作为预训练权重,在此基础上使用业务数据对模型进行Fine-tune。在Fine-tune时,默认源域(预训练模型)、目标域数据集(用户业务数据集)需要具有较强相关性,即数据同分布,这样我们才能利用预训练模型的大量知识储备,快速高效地训练出针对特定业务场景并具有优秀效果的模型。
但在实际应用场景中,很多用户会面临数据集与源数据集分布不同的问题。比如,预训练模型的数据都是自然风景,但用户的数据集都是动漫人物。类似这种源数据集和目标数据差别较大的问题,在具体应用中较易导致负向迁移,具体表现为训练收敛慢,模型效果差等。
因此,一个包含各类场景、覆盖用户各类需求的超大规模数据集就十分重要,通过这个包罗万象的超大规模数据集训练所得的模型,才能够更好地适应来自各行各业用户的需求,更好地Fine-tune用户的业务数据集,帮助用户在自己的数据集上得到效果更好的模型。
百度超大规模预训练模型便在此背景下产生,在视觉方向,百度自研超大规模视觉预训练模型覆盖图像分类与物体检测两个方向。图像分类的预训练模型,用海量互联网数据,包括10万+的物体类别,6500万的超大规模图像数量,进行大规模训练所得,适应于各类图像分类场景;物体检测的预训练模型,用800+的类别,170万张图片以及1000万+物体框的数据集,进行大规模训练所得,适应于各类物体检测应用场景。相对于普通使用公开数据集训练的预训练模型,在各类数据集上都有不同程度效果提升,模型效果和泛化性都有显著提升。
真实测试数据展示百度超大规模视觉预训练模型的强大能力
(以下实验数据集均来自不同行业)
图像分类
在图像分类模型中,使用百度超大规模预训练模型的Resnet50_vd相比普通模型在各类数据集上模型效果平均提升12.76%,使用百度超大规模预训练模型的Resnet101_vd,相比于普通预训练模型,平均提升13.03%,使用百度超大规模预训练模型的MobilenetV3_large_1x,相比于普通预训练模型,平均提升8.04%。
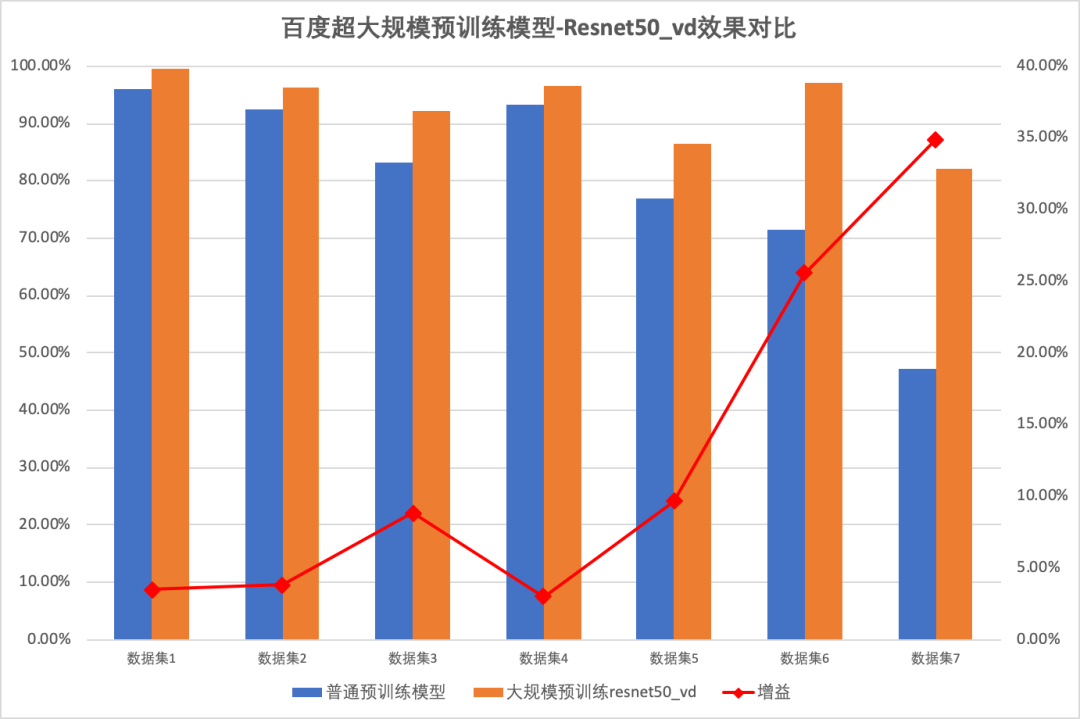
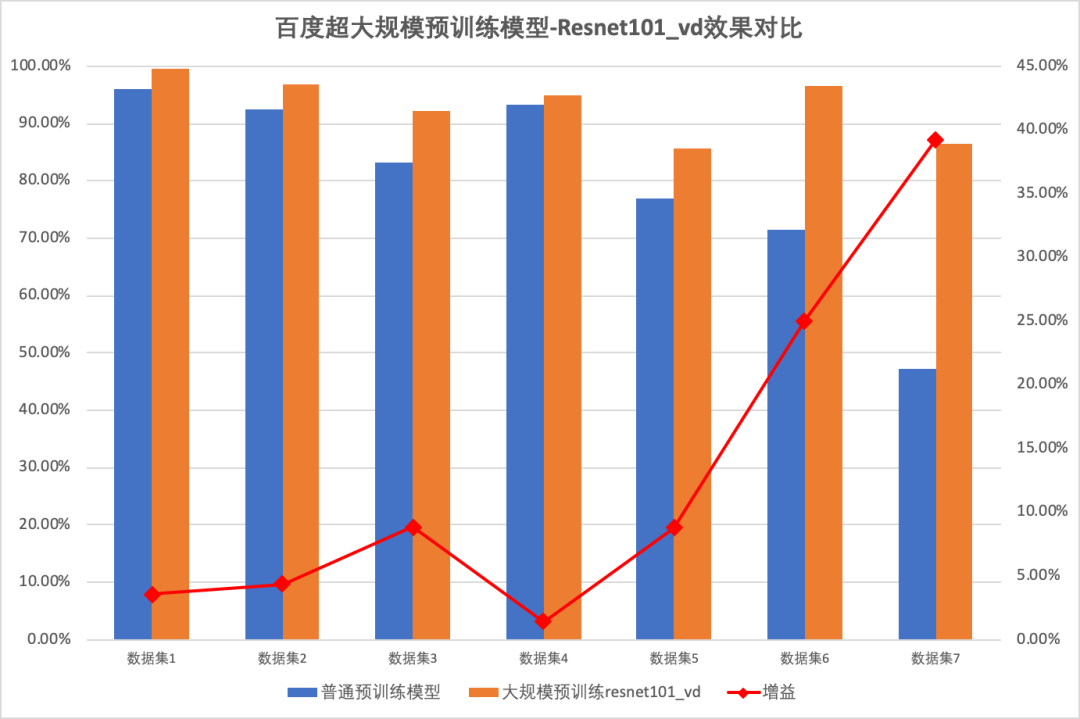
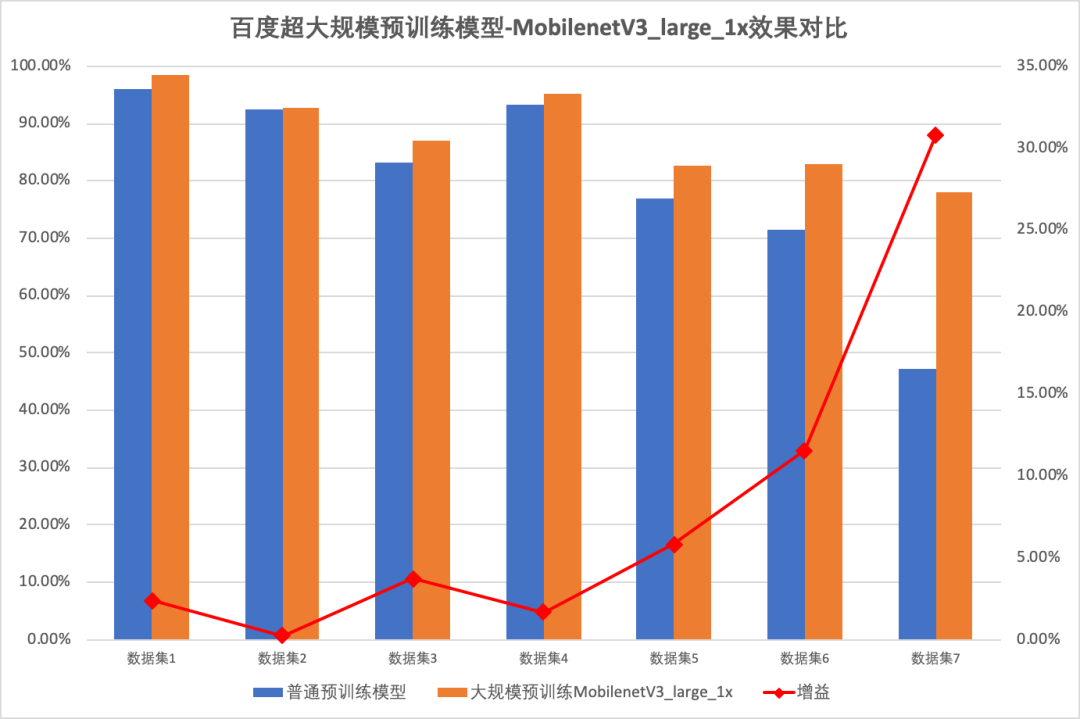
基于百度超大规模预训练模型训练出来的ResNet50_vd,ResNet101_vd和MobileNetV3_large_x1_0,其中比较特殊的几个模型,EffcientNetB0_small是去掉SE模块的EffcientNetB0,在保证精度变化不大的同时,大幅提升训练和推理速度,ResNeXt101_32x16d_wsl 是基于超大量图片的弱监督预训练模型,准确率高,但预测时间相对增加,Res2Net101_vd_26w_4s则是在单个残差块内进一步构造了分层的残差类连接,比ResNet101准确度更高。
并且,为了进一步提升图像分类模型的模型效果,在训练层面,图像分类新增了mix_up和label_smoothing功能,可以在单标签分类任务中,根据模型的训练情况选择开启或者关闭。mix_up是一种数据增强方式,它从训练样本中随机抽取了两个样本进行简单的随机加权求和,并保存这个权重,同时样本的标签也对应地用相同的权重加权求和,然后预测结果与加权求和之后的标签求损失,通过混合不同样本的特征,能够减少模型对错误标签的记忆力,增强模型的泛化能力。Label_smoothing是一种正则化的方法,增加了类间的距离,减少了类内的距离,避免模型对预测结果过于confident而导致对真实情况的预测偏移,一定程度上缓解由于label不够soft导致过拟合的问题。
物体检测
在物体检测模型中,使用百度超大规模预训练模型的YOLOv3_DarkNet相比普通模型在各类数据集上模型效果平均提升4.53 %,使用百度超大规模预训练模型的Faster_RCNN,相比于普通预训练模型,平均提升1.39%。
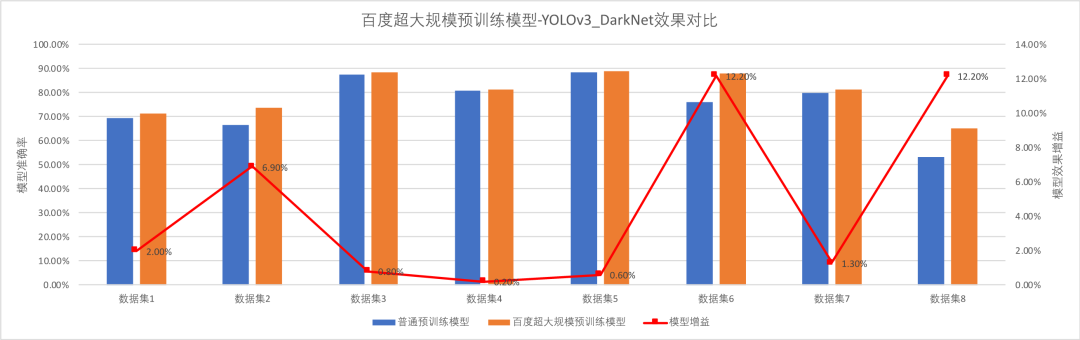
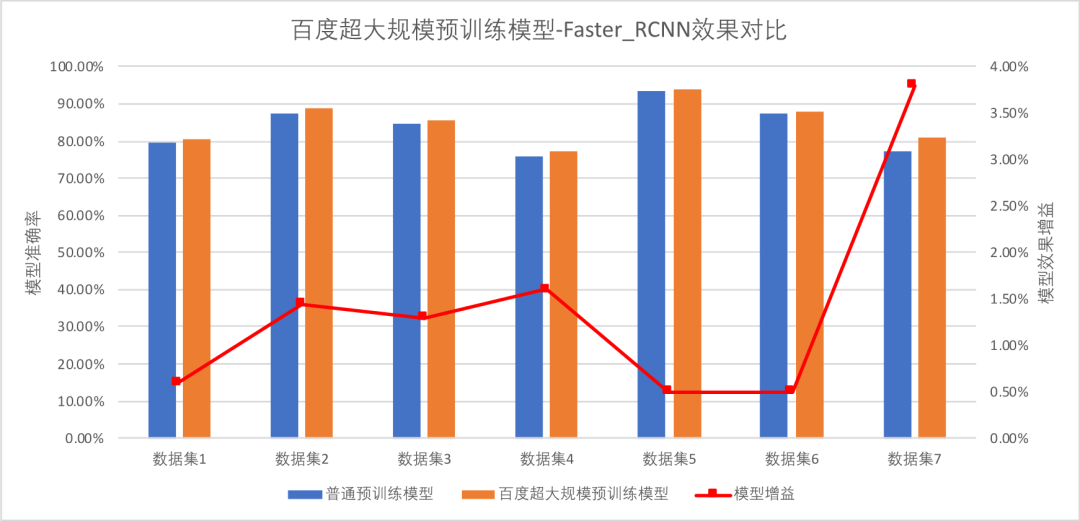
并且,在物体检测方向,EasyDL内置基于百度超大规模预训练模型训练出来的YOLOv3_Darknet、Faster_R-CNN_ResNet50_FPN,其中,Cascade_Rcnn_ResNet50_FPN通过级联多个检测器以及设置不同IOU的重采样机制,使得检测器的精度、和定位的准确度进一步提升。此外,针对用户的需求,新增两种YOLOv3的变种模型,其中,YOLOv3_MobileNetV1,是将原来的YOLOv3骨架网络替换为MobileNetv1,相比YOLOv3_DarkNet, 新模型在GPU上的推理速度提升约73%。而YOLOv3_ResNet50vd_DCN是将骨架网络更换为ResNet50-VD,相比原生的DarkNet53网络在速度和精度上都有一定的优势,在保证GPU推理速度基本不变的情况下,提升了1%的模型效果,同时,因增加了可形变卷积,对不规则物体的检测效果也有一定的正向提升。
综合多项数据可以发现,百度超大规模视觉预训练模型对比公开数据集训练的预训练模型,效果提升明显。
EasyDL零门槛高效定制高精度AI模型
百度EasyDL是基于飞桨深度学习平台,面向企业开发者推出的零门槛AI开发平台,一站式支持智能标注、模型训练、服务部署等全流程功能,内置丰富的预训练模型,支持图像分类、物体检测、文本分类、音视频分类等多类模型,支持公有云/私有化/设备端等灵活部署方式。EasyDL目前已在工业、零售、制造、医疗等领域广泛落地。
在模型的开发与应用过程中,从数据准备、模型训练到服务部署,开发者在每个环节都可能面对不同的门槛与难点。
在数据准备阶段,如何针对业务需求选择适当的训练数据并正确标注?
进入到模型训练环节,如何选择恰当的模型,精度该如何提升?
到达部署的“最后一公里”,硬件如何选型,又如何快速完成业务集成?
解答疑问的机会来了!
本周六,AI快车道降临“世界历史名城”西安,开源框架高阶营也将由百度资深研发工程师们,从开发全流程、目标检测、“全能”OCR、最前沿的NLP技术、部署工具、昆仑芯片六大方向展开深度讲解,欢迎有AI应用的、热爱深度学习技术等寻求技术突破的开发者们来【高新希尔顿酒店7层3号厅】进行交流,期待在这样一个历史、科研、教育、工业都重点发展的城市与大家共建AI之路!
同日,AI快车道【EasyDL零门槛模型开发营】也在【西安高新希尔顿酒店7层1号厅】,百度资深研发高工将会用半天时间,深入浅出讲解技术原理、结合业务与技术解析行业标杆案例,手把手带领学员完成模型开发!更有设备端模型技术原理介绍与展示、研发现身说法分享多年累计模型效果提升经验,助你短时间超高效取得EasyDL模型开发真经!
同时,也会在线上同步直播,扫描海报二维码或点击阅读原文,报名进群获取完整课表与直播链接!