
多标签文本分类介绍,以及对比训练
共 2267字,需浏览 5分钟
·
2022-02-09 17:36
今天我为大家主要介绍几种多标签文本分类的方法。
一、文本分类介绍
首先,我介绍下多元文本分类和多标签文本分类的的区别。
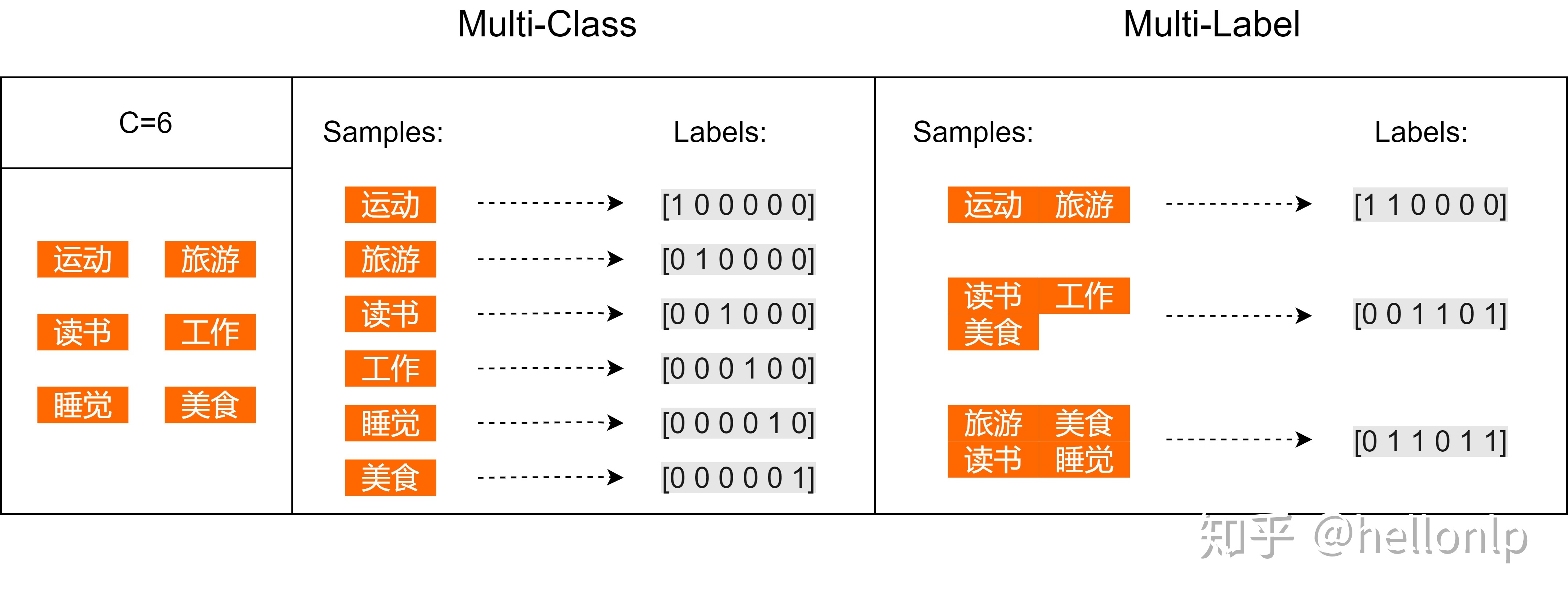
1、Multi-Class:多分类/多元分类(二分类、三分类、多分类等)
- 二分类:判断邮件属于哪个类别,垃圾或者非垃圾
- 二分类:判断新闻属于哪个类别,机器写的或者人写的
- 三分类:判断文本情感属于{正面,中立,负面}中的哪一类
- 多分类:判断新闻属于哪个类别,如财经、体育、娱乐等
2、Multi-Label:多标签分类
- 文本可能同时涉及任何宗教,政治,金融或教育,也可能不属于任何一种。
- 电影可以根据其摘要内容分为动作,喜剧和浪漫类型。有可能电影属于romcoms [浪漫与喜剧]等多种类型。
3、二者区别
- 多分类任务中一条数据只有一个标签,但这个标签可能有多种类别。比如判定某个人的性别,只能归类为"男性"、"女性"其中一个。再比如判断一个文本的情感只能归类为"正面"、"中面"或者"负面"其中一个。
- 多标签分类任务中一条数据可能有多个标签,每个标签可能有两个或者多个类别(一般两个)。例如,一篇新闻可能同时归类为"娱乐"和"运动",也可能只属于"娱乐"或者其它类别。
例子:
假设个人爱好的集合一共有6个元素:运动、旅游、读书、工作、睡觉、美食

二、多标签文本分类
下面,我会介绍3种文本多标签分类的方法。
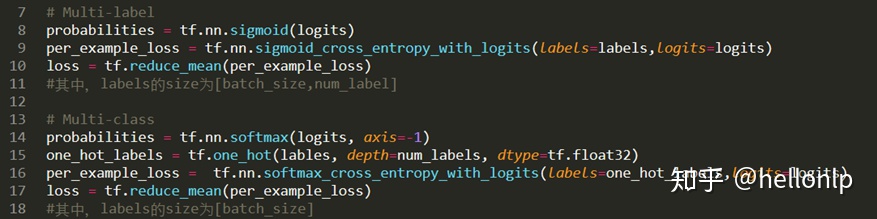
1、改变输出概率(probabilities)的计算方式和交叉熵的计算方式
- tf.nn.sigmoid_cross_entropy_with_logits测量离散分类任务中的概率误差,其中每个类是独立的而不是互斥的。这适用于多标签分类问题。
- tf.nn.softmax_cross_entropy_with_logits测量离散分类任务中的概率误差,其中类之间是互斥的(每个条目恰好在一个类中)。这适用多分类问题。
- 在简单的二进制分类中,sigmoid和softmax没有太大的区别,但是在多分类的情况下,sigmoid允许处理非独占标签(也称为多标签),而softmax处理独占类。

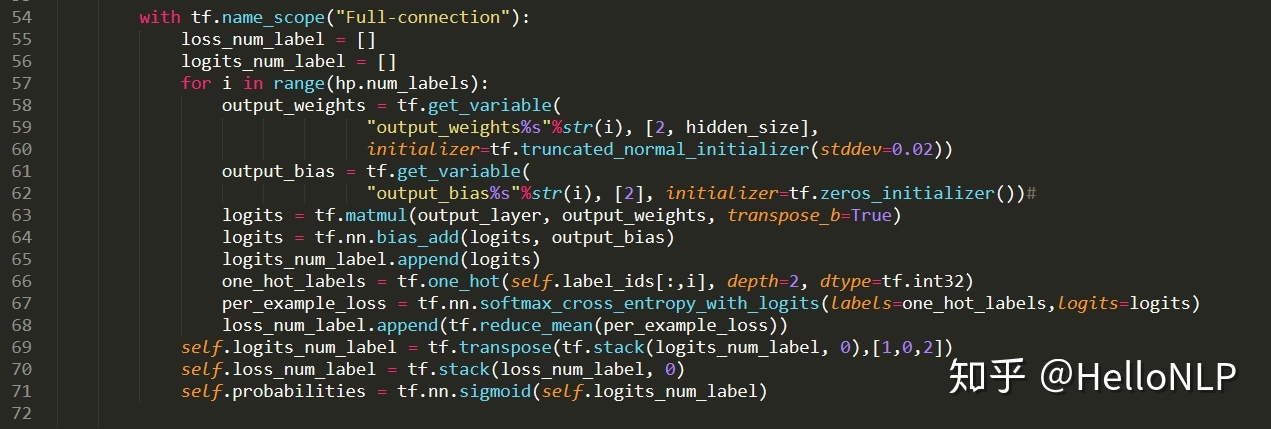
2、改变输出的全连接层。
- 在输出层设置多个全连接层,每一个全连接层对应一个标签。
- 损失函数为所有标签损失函数的平均值。

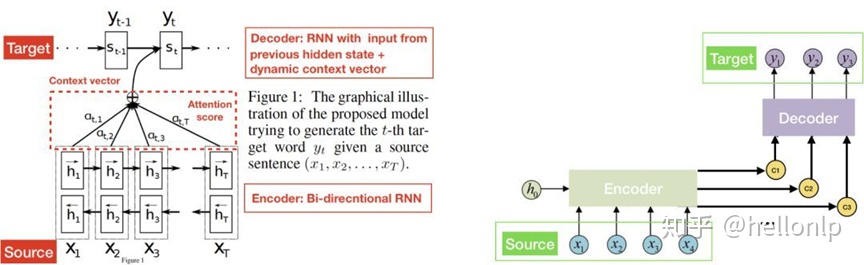
3、使用框架:Attention + seq2seq(Beam Search)
- 上下文语义信息 -> 多标签之间的关系。多标签一般去看下并非独立。
- 将多标签当作一个序列(类似一句话)。

三、实践
以上3种方法,都有自己的优缺点。可能不同的人会有不同的想法,有的人会觉得第1种方法最好,有的人会觉得第2种会更种好,还有剩下一部分人会觉得第3种方法最好。我们有自己不同的理解,是因为我们都有自己的想法。(有想法可以留言评论)
至于哪一种方法最好呢,实践出真理。所以,之后,我会在同一个Pretraining LM的基础上,通过修改下游任务的框架,按照以上3种方法逐一实现(附代码)。
四、文章
1、改变输出概率(probabilities)的计算方式和交叉熵的计算方式
- 下游任务使用全连接层:
- 下游任务使用TextCNN:
2、改变输出的全连接层
HelloNLP:多标签文本分类 [ALBERT+Denses](附代码)3、基于Seq2Seq+Attention框架
HelloNLP:多标签文本分类 [ALBERT+Seq2Seq+Attention]四、模型对比
接下来的实验结果是基于一个多标签的文本分类,其中标签数量为96个。
1、损失函数图

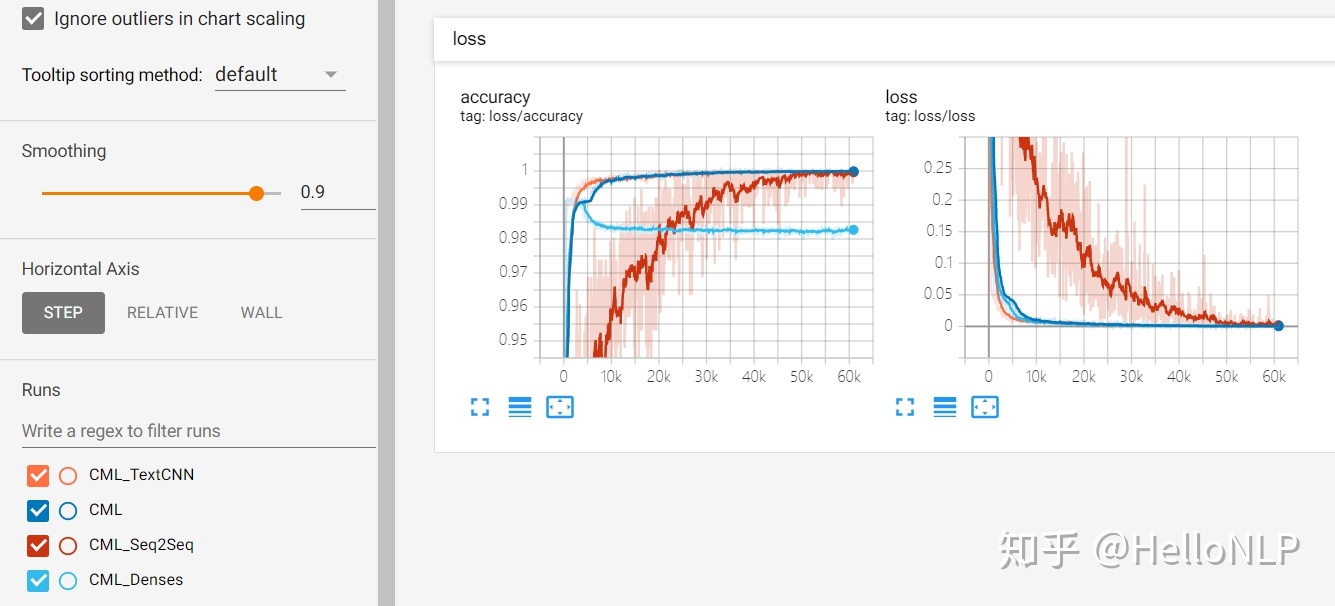
一共训练了4个模型,分别是ALBERT、ALBERT+TextCNN、ALBERT+Seq2Seq+Attention和ALBERT+Denses,他们在上图中的对应关系分别为:CML、CML_TextCNN、CML_SeqSeq和CML_Denses。训练过程中,每一个框架使用的同样的batch_size、learning_rate。
在上图中,从表面上看,基于ALBERT、ALBERT+TextCNN和ALBERT+Denses这三种框架下的Loss收敛的很快,这个是因为计算loss时,会考虑到标签为0的情况,即标签为空的情况(在项目中,很多样本为空标签)。
2、精确率、召回率和F1值
2.1、 评估方法
这里的精确率、召回率和F1值都是针对有标签的。
在TP的情况下,存在两种情况,一种是预测标签和真实标签完全一致,另一种是预测标签和真实标签只有部分一致。这两种情况下我们计算的方式为:
# 第一种情况
TP = TP + 1
# 第二种情况
TP = TP + 0.5
FN = FN + 0.5这样做的目前主要是因为多标签分类中,存在标签部分召回或者过多召回(某一个样本)。
2.2、评估值

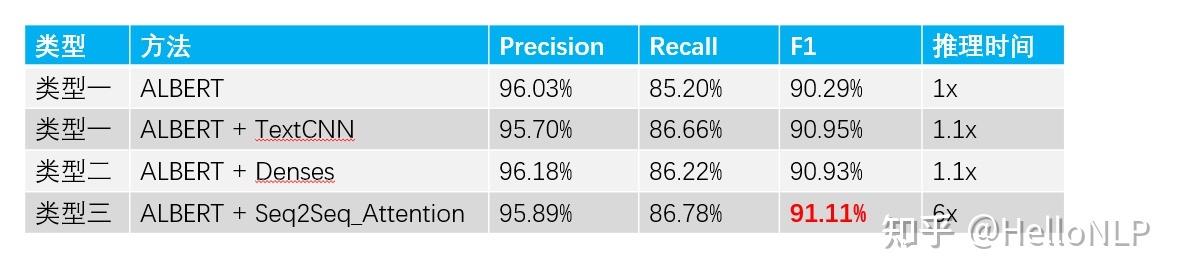
从上表中可以看到,基于ALBERT+Denses的效果远远好于基于ALBERT的。另外,基于ALBERT+TextCNN较好于的ALBERT+Denses的效果。
- ALBERT+TextCNN和ALBERT+Seq2Seq_Attention的效果接近。
- 在推理速度上面,前面三个框架基本接近,ALBERT+Seq2Seq_Attention的速度比他们慢3倍。
3、结论
- 如果对推理速度的要求不是非常高,基于ALBERT+Seq2Seq_Attention框架的多标签文本分类效果最好。
- 如果对推理速度和模型效果要求都非常高,基于ALBERT+TextCNN会是一个不错的选择。