
啥?Transformers又来刷CV的榜了?
点击上方“视学算法”,选择加"星标"或“置顶”
重磅干货,第一时间送达

导读
本文系统性的介绍了transformer从首次提出到现在比较火热的一些新改进的工作:Swin Transformer和CvT,详细的讲述了他们的原理及优缺点。
作者简介:王辉,中国人民大学硕士二年级在读,导师是赵鑫教授,研究方向为推荐系统。
https://www.zhihu.com/people/hui-hui-39-79
引言
Transformer[1]模型的提出,深刻地改变了NLP领域,特别是随后的一系列基于Transformer的大规模预训练语言模型,在NLP中开启了一种新的模型训练范式:先在大规模无标注文本上pre-train模型,再使用任务特定的小数据对模型进行fine-tuning。之所以说在“NLP中开启了”是因为在CV中,这种训练模式早已成为一种主流方法,这也算是NLP借鉴了CV领域的成功的经验。如今CV的研究者们看着Transformer在NLP中取得了如此大的成功,便想看看其在CV中的潜力,于是便将Transformer引入到了CV中。最近的一些改进更是刷新了CV中几大任务的榜,如Swin Transformer刷新了COCO上的目标检测,ADE20K上的语义分割...
1 CV中首秀
Transformer在CV中的首秀便是Vision Transformer(ViT)[2],作者们力求对结构最小的改动,保证了Transformer的原汁原味。具体做法是将一张图片分割成为多个互不重叠的patches,这里的patch就可以认为是NLP中的token,将patch排列成一个序列,经过一个Linear Embedding得到patches embedding(看了一下开源的code,这个过程还是用的CNN),为了做图片的分类任务,依然是仿照BERT那种加 的方式,在patch序列的起始端加了个特殊的标记 (这个标记对应位置的输出将被用来做分类),之后就是加上喜闻乐见的位置编码过Transformer做encode了。
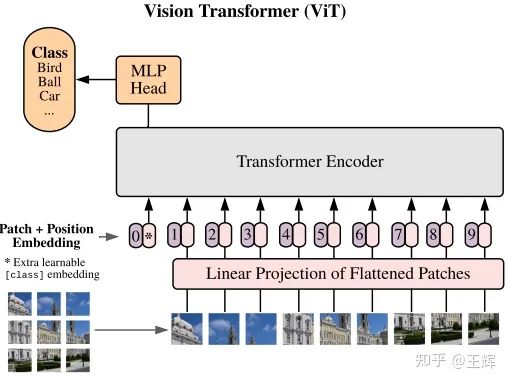
2 ViT 存在的问题
首先是Transformer本身自有的复杂度问题。假设处理的序列长度为 ,隐状态向量维度为 ,则Transformer的计算复杂度为 ,故其复杂度为序列长度 的平方级。这使得序列长度很大时,直接使用Transformer变得很困难, 降低这个复杂度是当前NLP中研究的一个热点。这个问题在ViT中依然存在,设想待处理的图片分辨率很高,这样分割出的patch序列就会很长,力求原汁原味的Vision Transformer就无法处理了。 ViT采取的这种固定分割patch的模式,很难适应CV中视域scale不定的问题,典型的场景就是object detection,在固定分割的模式下,一个目标物体可能会被分到多个patch中,但ViT中采取的global self-attention无法很好地将这些相邻的patch表现出的local信息联系进行表征。
最近的两个工作就对上述的问题分别对ViT进行了不同程度的改进,刷新了CV中几个任务的榜。
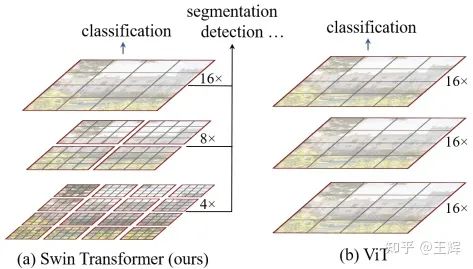
3 层次化Transformer
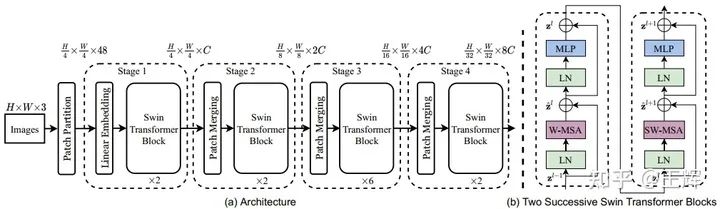
首先是微软提出的Swin Transformer[3],在Transformer层之间采用一种patch merge的机制将相邻的patch特征整合,实现了类似CNN中的下采样的效果,构建了一种层次化的特征表示,这样不同层的输出就可以满足不同的特征需求,希望像主流的CNN框架那样,基于Transformer为CV不同任务提供统一的backbone。
3.1 降低复杂度
针对复杂度问题,作者们提出了一种shifted window的机制,如上图中灰色小格代表一个patch,红色框代表一个window。在ViT中self-attention是对所有输入的patch计算的,而Swin Transformer设计的window机制,使得self-attention只需对某个local window内的patch计算。
假设图片大小是 ,特征维度是 ,patch大小是 ,则patch数为 (在patch大小固定时,划分得到的patch数与图片大小 成正比)。Swin Transformer中的每个windows中包含 个patchs,则划分后的窗口数为 ,每个窗口中有 个patch。下面分析一下复杂度差异:
如上所述Transformer的复杂度为 ,则ViT的复杂度为 ,其复杂度是图片大小 的平方级。而在Swin Transformer中,图片被分到多个windows中,每个windows的计算复杂度为 ,共 个窗口,相乘最终复杂度为 ,可见此时复杂度变为了图片大小 的线性级,显著降低了时间复杂度。
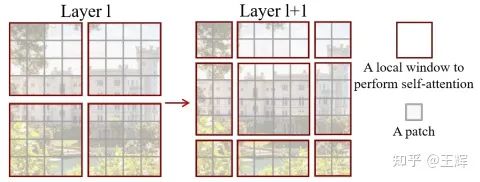
3.2 滑动窗口
刚才说到了是一种shifted window,从作者给出的示意图来看,应该是将窗口向右下角平移,这样就实现了跨窗口的特征交互,弥补了原来只能单视窗可见的局限,一定程度上扩大了感受野。这里设计是连续两个Transformer层,一个使用常规的windows,一个使用滑动后的窗口。如图所示,窗口移动过后数量从4个变为了9个,这样直接处理计算量会变为原来的2.5倍,论文本意要降低复杂度,这当然是不被允许的。
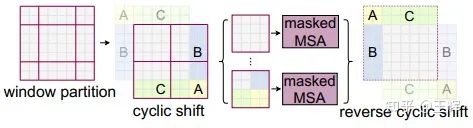
于是作者们提出了cyclic shift,具体做法如上图所示,将图中浅色A,B,C部分对应的移动到深色的A,B,C部分,这样就保证了依然是4个窗口参与计算,但这样拼接使得原本不属于相邻的图像区域变为了邻居,如图中和左下窗口中的C与灰色部分,为了避免这种无关区域间的信息交互,作者借助masked self-attention(MSA)来解决了这个问题。
最后看一眼Swin Transformer的整体结构。Swin Transformer最近是十分的火,刷榜了几个CV的任务,在代码未上传的情况下已然收获了1.3k的star(截至写作时间2021.4.11),可谓是吊足了大伙儿的胃口。不过其中一个任务的SOTA又变成了接下来出场的这位。
4 引CNN入Transformer
虽然Swin Transformer的patch merge和shifted window一定程度上可以多关注local信息间的交互,但终究建模local信息是CNN的长处,那何不更直接地把CNN和Transformer结合一下,集大家之所长,CvT[4]就直接地做了这件事,这也许就是打不过就收购吧。
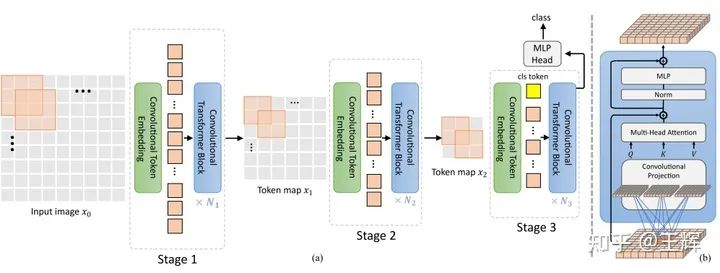
CvT在原来Transformer的基础上做了两处主要的改动,引入了卷积操作。一个是Convolutional Token Embedding,一个是Convolutional Projection。前者是对输入的图片或feature map做卷积得到输入的特征序列,可以通过不同卷积核和步长自由地控制输入序列的长度;后者是替换了输入进到multi-head self-attention之前的线性映射,使得query, key,value可以多关注local context信息交互。
4.1 Convolutional Token Embedding
CvT依然是采用了CNN常见的层次化结构,分为了3个stage,前两个stage专注于特征抽取,第三个stage仿照ViT加入了分类标记 做特定任务。借助Convolutional Token Embedding逐层降低了序列的长度,与此同时增大了特征表示的维度,实现了对更加丰富抽象特征的学习,可以适应更加复杂的问题,维度增大的同时降低序列长度,复杂度实现了一种平衡。值得一提的是,因为借助卷积实现了对local位置信息的建模,CvT丢弃了Transformer的标配——Position embedding,依然实现了很好的效果。
4.2 Convolutional Projection
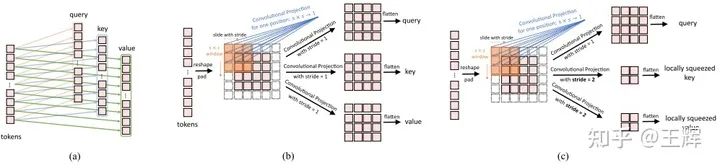
上图中(a)是普通Transformer中的线性映射,(b)是本文中的Convolutional Projection,这种方法直观感觉更适合图片这种数据类型,实现了local信息间的交互。出于效率考虑,CvT采用了[5]中提出的depth-wise separable convolution降低了卷积操作的复杂度。另外也可以方便地实现对特征进行下采样,如(c)中所示,采用步长为2降低了key和value的大小,这样同时也可以降低在Multi-head self-attention中的计算量。
结束语
这是最近CV中比较火的两个Transformer-based模型,可以看出Transformer已经引起了CV研究者的足够兴趣,可以想见今后定还会有更多更好的工作出来,基于Transformer的模型会占据更多CV任务的榜首。那么问题来了,Transformer会再度成为CV中的主流吗?
[1] Vaswani et al. Attention is all you need.
[2] Dosovitskiy et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale.
[3] Liu et al. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows.
[4] Wu et al. CvT: Introducing Convolutions to Vision Transformers.
[5] Howard et al. Mobilenets: Efficient convolutional neural networks for mobile vision applications.

点个在看 paper不断!