
【深度学习】CV和NLP通吃!谷歌提出OmniNet:Transformers的全方位表示
在机器翻译、图像识别等任务上表现SOTA!性能优于Performer、ViT和Transformer-XL等网络。

作者单位:谷歌Research和大脑团队等
论文:https://arxiv.org/pdf/2103.01075.pdf
本文提出了来自Transformer的全方位表示(OmniNet)。
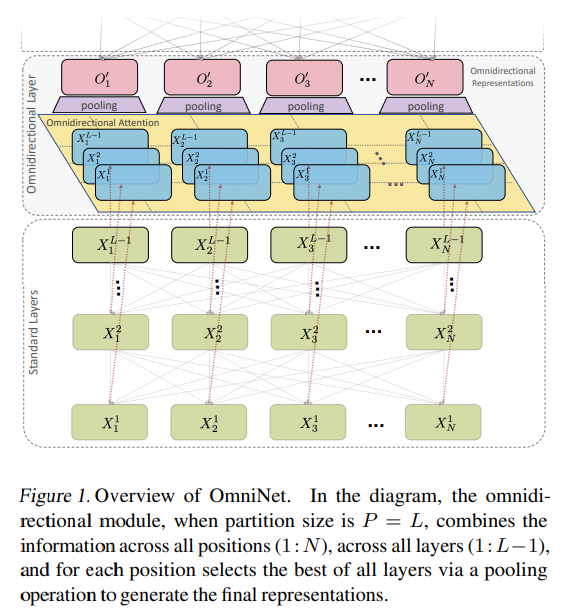
在OmniNet中,不是维护严格的水平感受野,而是允许每个token都参与整个网络中的所有token。此过程也可以解释为一种极端或集中注意力机制的形式,该机制具有网络整个宽度和深度的感受野。
为此,通过元学习器来学习全向注意力,这实质上是另一个基于自注意力的模型。为了减轻完整的感受野注意力的计算成本,我们利用有效的自注意力模型,例如基于kernel的(Choromanski等人),low-rank的注意力(Wang等人)和/或Big Bird(Zaheer)等)。
Transformer架构
Transformer块接受N×d输入,其中N表示序列中标记的数量,d表示表示的大小。每个Transformer模块都具有一个自我注意模块和一个两层前馈网络,在它们之间以位置方式应用ReLU激活。
自我注意机制首先使用线性变换将每个输入X投影到Q,K,V表示形式中,这些形式对应于查询,键和值。自我注意机制通常是多头的,其中并行执行多个相似的线性投影。第l层中每个自我关注头h的输出写为:
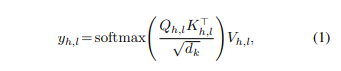
其中yh,l是头h在第l层的输出,而dk是每个头的大小。然后,将多个磁头的输出进行级联,然后通过Wo,l进行另一个线性变换,该变换将所有磁头的级联投影到dm。这是通过层归一化和残差连接来包装的,可以写为:
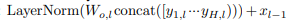
作为self- 注意模块。
Feed Forward Layers 变压器块的FFN块执行两层转换,定义为:
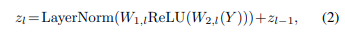
其中W1,W2是FFN层的可训练参数(权重变换)。为了清楚起见,省略了偏置参数。
OmniNet网络细节(建议看原文第三章3.2)
提名代表
保持因果关系和自动回归解码
高效变压器
分区的单子网络


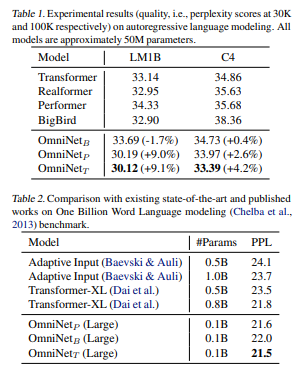
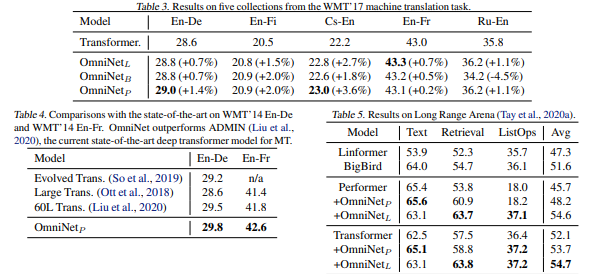
实验结果
在自回归语言建模(LM1B,C4),机器翻译, Long Range Arena(LRA)和图像识别方面进行了广泛的实验。实验表明,OmniNet在这些任务上实现了相当大的改进,包括在LM1B,WMT'14 En-De / En-Fr和 Long Range Arena上实现了最先进的性能。
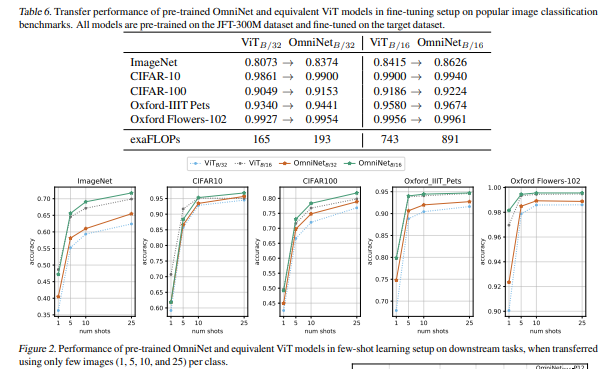
此外,在Vision Transformers中使用全向表示可以显著改善短时学习和微调设置中的图像识别任务。
往期精彩回顾
本站qq群851320808,加入微信群请扫码: