
你眼中的好模型只是「刷榜机器」?

极市导读
基准测试堪称人工智能领域的「科举制」,但这种应试教育唯分数论输赢,能训练出真正的好模型吗?>>加入极市CV技术交流群,走在计算机视觉的最前沿
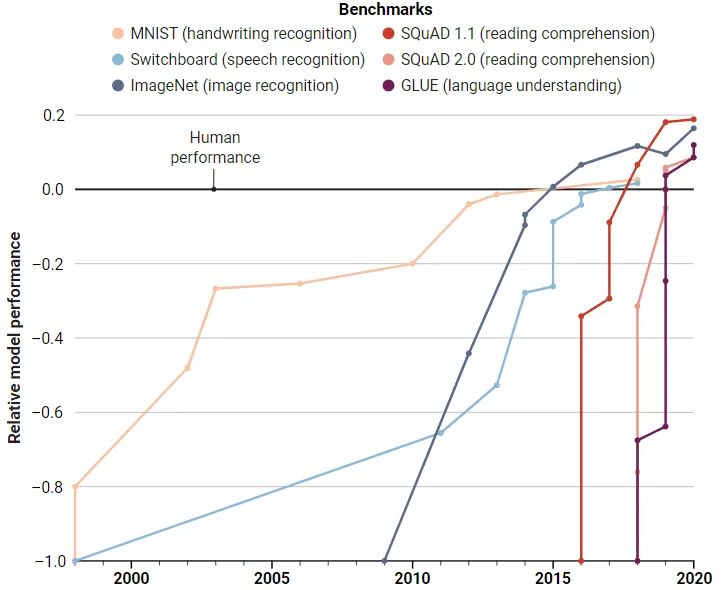
2010年,基于ImageNet的计算机视觉竞赛推出,激发了深度学习的一场算法与数据的革命,从此基准测试成为衡量AI模型性能的一个重要手段。
在NLP领域, 也有GLUE(通用语言理解评估)基准,AI模型需要在包含上千个句子的数据集上进行训练,并在九个任务上进行测试,例如判断一个句子是否符合语法,分析情感,或者两个句子之间是否是逻辑蕴涵等。
GLUE刚发布时,性能最佳的模型得分还不到70分,基准创建人,纽约大学的计算机科学家Sam Bownman当时认为这个数据集很成功,至少难倒了AI模型。
而仅仅经过一年的发展,AI模型的性能轻松达到90分,超越了人类的87.1分。
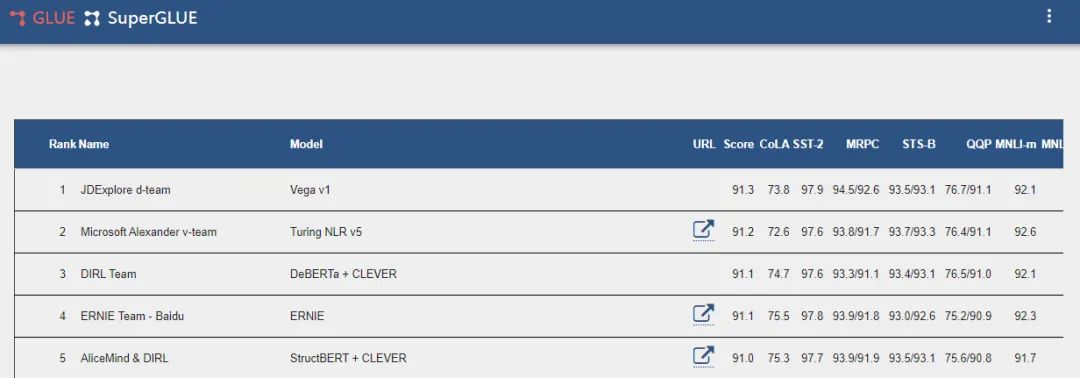
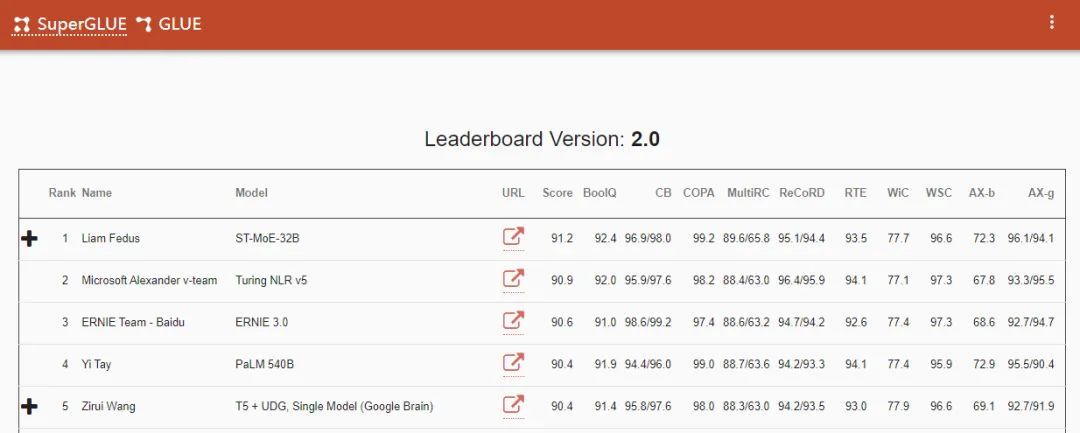
2019年,研究人员再次提高了基准测试的难度,发布SuperGLUE,一些任务要求AI模型不仅能够处理句子,还要处理来自维基百科或新闻网站的段落后回答阅读理解问题。
同样,人类在基准刚发布时领先20分,到2021年初,计算机再次击败了人类的89.8分。
难道AI模型的智力水平已经超越了人类?

在「刷榜」上,AI语言模型在经过海量书籍、新闻文章和维基百科中数十亿单词的训练后,一次次让从业者兴奋,可以生成令人惊艳的人类散文、推文、总结电子邮件,甚至在几十种语言之间进行相互翻译。
但在现实应用中部署或特定例子的测试时,又会让人感叹:AI怎么会犯如此愚蠢的错误?该怎么教会它改正?
2020年,微软的计算机科学家Marco Túlio Ribeiro发布了一篇报告,指出了包括微软、谷歌和亚马逊在内的各种sota模型内的诸多隐含错误,比如把句子里的「what's」改成「what is」,模型的输出就会截然不同,而在此前,从没有人意识到这些商业模型竟会如此糟糕。
这样训出来的AI模型就像一个只会应试教育、成绩优异的学生,可以成功通过科学家设置的各种基准测试,却不懂为什么,俗称「高分低能」。

不过大多数研究人员认为,解决方案并不是放弃基准测试,而是改善。不过改善方法上,又有了分歧。
一些人认为基准测试应该更加严格,有人认为基准测试应该能阐明模型的偏见,还有人希望基准数据集的规模要更大一些,以便应对那些没有单一标准答案的问题(如文本摘要),又或者利用多个评价指标来衡量模型的性能。
让基准变得更难
一个最明显的基准提升手段就是让它们变得更难。
AI初创公司Hugging Face的研究带头人Douwe Kiela认为现有的基准测试最离谱的一点就是让AI模型看起来已经超越了人类,但每个NLP从业者都深知,想要达到人类水平的语言智能,还有很长的路要走。
所以Kiela开始着手创建一个动态数据收集和基准测试平台Dynabench,主要针对GLUE等静态基准存在的一些问题:性能超越人类的速度太快、很容易过拟合、具有不确定或不完善的评价指标等。

Dynabench依赖于众包平台,对于每个任务(如情绪分类),众包工作人员需要提交他们认为人工智能模型会错误分类的短语或句子,成功欺骗到模型的样例被加入到基准测试中。模型在这些数据上进行训练,然后重复该过程,并且基准测试也在不断发展,不会出现排行榜过时的情况。
Dynabench平台本质上是一个科学实验:如果动态地收集数据,让人和模型处于循环中,而不是传统的静态方式,能让AI模型的研究取得更快的进展吗?
另一种改进基准的方法是缩小实验室内数据和现实场景之间的差距。现有的机器学习模型通常在同一个数据集中随机选择的示例上进行训练和测试,而在现实中,数据可能会发生分布变化。
WILDS是斯坦福大学计算机科学家Percy Liang开发的基准测试,由10个精心挑选的数据集组成,可用于测试模型识别肿瘤、动物物种分类、补全计算机代码等任务。
WILDS最关键的一步是每个数据集都来自多个源,例如肿瘤图片来自五家不同的医院,目的是考察模型在不同数据集之间的泛化能力。

WILDS 还可以测试模型的社会偏见,其中一个数据集是从新闻网站评论平台收集的数十万条有毒评论的集合,根据受辱的人口统计(黑人、白人、基督徒、穆斯林、LGBTQ 等)分为八个域。研究人员可以通过在整个数据集上训练模型然后针对一部分数据进行测试来寻找盲点,例如,检测能否识别针对穆斯林的有害评论。
打破「唯分数论」
更好的基准测试只是开发更优模型的一种途径,开发人员应当避免沉迷于排行榜的名次和分数。
埃因霍芬理工大学的计算机科学家Joaquin Vanschoren谴责论文中所谓的SOTA(state of the art) 正在扼杀创新,他呼吁AI会议中的审稿人不要再强调排行榜上的分数,而主要关注创新点。
大部分基准测试上的分数只有一个,并不能完全反映模型之间的优劣。
在Dynabench中,使用Dynascore对模型在基准测试中的性能进行评价,涵盖了多种因素:准确性、速度、内存使用、公平性和对输入变化的鲁棒性。用户可以根据对他们最重要的因素来对模型进行排行,比如Facebook 的工程师可能比智能手表设计师更看重准确性,而后者可能更看重能源效率。

另一方面,基准数据集中问题通常没有绝对的「ground truth」,所以分数的准确性也不一定可靠。一些基准设计者只是从测试数据中剔除模棱两可或有争议的例子,在数据集中也称之为噪音。
去年,伦敦玛丽女王大学的计算语言学家 Massimo Poesio 和他的同事创建了一个基准,用于评估模型从人类数据标注者之间的分歧中学习的能力。
他们将多个文本片段根据人类感觉的「好笑程度」进行排序,并以此来训练模型,要求模型判断两个文本中哪段更好笑的概率,而不是简单地提供「是或否」作为答案,每个模型都根据其估计与人类标注分布的匹配程度进行评分。
基准研究仍然小众
目前基准相关的研究首要面临的问题是缺乏激励措施。
在去年发表的一篇论文中,谷歌的研究人员采访了工业界和学术界的 53 位人工智能从业者。许多人指出,改进数据集不如设计模型更有成就感。论文的作者之一Lora Aroyo认为,机器学习社区正在改变对基准的态度,但目前仍然是一个小众研究。
去年的NeurIPS会议上推出了一个新的track,用于审查和发表有关数据集和基准主题的论文,立即为研究这些主题创造了新的动力,毕竟中了就是顶会。
联合主席 Vanschoren说,组织者预计会有几十份提交,但最后收到了超过500篇论文,这也说明了这是众望所归。

一些论文提供了新的数据集或基准,而另一些则揭示了现有数据集或基准的问题,有研究人员发现在10个流行的视觉、语言和音频基准中,测试数据中至少有 3% 的标签不正确,这些错误会影响模型的排名。
尽管许多研究人员希望通过激励措施创建更好的基准,但也有人不希望该领域过多地研究这些。
古德哈特定律(Goodhart's law)有言:一旦指标变成了目标,那它就不再是一个好指标了。

也就是说,当你尝试用各种方法教模型怎么考试时,考试本身也就失去了意义。
最后,Ribeiro表示,基准应该是从业者工具箱中的一个工具,人们用基准来代替模型的理解,通过基准数据集来测试「模型的行为」。
参考资料:https://www.science.org/content/article/computers-ace-iq-tests-still-make-dumb-mistakes-can-different-tests-help
公众号后台回复“CVPR 2022”获取论文合集打包下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
