
NVLink到底Link了啥?


几个月前,NVIDIA创始人兼首席执行官黄仁勋从厨房烤箱端出了世上首款基于NVIDIA® Ampere架构的GPU —— NVIDIA A100,顿时吸引了一众网友的前排关注,小伙伴们纷纷表示被(丧)震(心)惊(病)了(狂)!
最新A100 GPU有五大技术性突破设计:
NVIDIA Ampere架构
具有TF32的第三代Tensor Core核心
多实例GPU (MIG)
第三代NVIDIA NVLink
结构化稀疏
其中一个关键性创新就是采用了第三代NVIDIA NVLink,不知不觉就已经第三代了,今天,我们就主要来说道说道这个NVLink!
简单来说,NVIDIA® NVLink®是一个能够在GPU-GPU以及GPU-CPU之间实现高速大带宽直连通讯的快速互联机制。

随着开发人员在人工智能 (AI) 计算等应用领域中越来越依赖并行结构,各行各业中的多GPU和多CPU系统愈发普及。其中包括采用PCIe系统互联技术的4 GPU和 8 GPU系统配置来解决非常复杂的重大难题。然而,在多GPU系统层面,PCIe带宽逐渐成为瓶颈,为了解决这一问题,NVIDIA提出了NVLink技术。
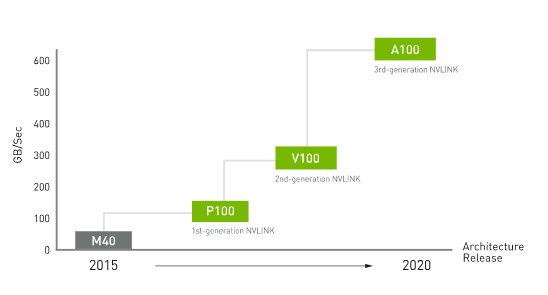
NVIDIA最早在2014年GTC大会上首次提出NVLink技术,直到2016年,发布了P100,这是搭载NVLink的第一款产品,单个GPU具有160GB/s的带宽,相当于PCIe Gen3 * 16带宽的5倍。在GTC 2017上发布的V100搭载的NVLink 2.0更是将GPU带宽提升到了300G/s,差不多是PCIe的10倍了。再到今年的线上GTC大会,A100集成了最新的第三代NVLink,单个NVIDIA A100 Tensor核心GPU支持多达12个第三代NVLink连接,总带宽为每秒600G/s,几乎是PCIe Gen 4带宽的10倍。
NVLink的受众相当广泛,不仅可以依据不同需求完成GPU-GPU节点内部的高速互联,同时还能在GPU-CPU甚至CPU-CPU之间形成高速互联。它既可以像PCIe,也可以像QPI。所有多GPU并行工作的场合,无论是价值数亿美元的超级计算机集群还是桌面的SLI都将会从中获得更高的并行通讯带宽。
可能大家觉得NVLink比较适用于对数据交换带宽敏感的HPC应用,而往往忽视掉了它在图形应用场景领域的价值,其所带来的更大的GPU之间与GPU的互联带宽可以让SLI场合,尤其是多卡SLI以及单卡多芯场合从中获益。
利用NVLink桥接器,能够连接两块NVIDIA® Quadro®显卡,从而实现显存和性能扩展,满足最大视觉计算工作负载的需求。

提到NVLink不得不提到NVSwitch, NVIDIA NVSwitch™是将多个NVLink加以整合,在单个节点内以NVLink的较高速度实现多对多的GPU通信,从而进一步提高互联性能。NVLink和NVSwitch的结合使NVIDIA得以高效地将AI性能扩展到多个GPU。

上图NVSwitch拓扑图显示的是两个GPU的连接。8个或16个GPU以相同方式通过 NVSwitch进行多对多连接。
由于PCIe带宽经常会在多GPU系统级别造成瓶颈,因此深度学习技术的快速应用使得对速度更快、可扩展性更强的互连的需求日益迫切。要扩展深度学习工作负载,需要显著提高带宽并降低延迟。
NVIDIA NVSwitch以NVLink的先进通信能力为基础,能够解决该问题。它采用可在一台服务器中支持更多GPU以及GPU之间的全带宽连接的GPU架构,可将深度学习性能提升到更高水平。每个GPU都有12个连接NVSwitch的NVLink链路,可实现高速的多对多通信。
转载申明:转载本号文章请注明作者和来源,本号发布文章若存在版权等问题,请留言联系处理,谢谢。
推荐阅读
更多架构相关技术知识总结请参考“架构师技术全联盟书店”相关电子书(35本技术资料打包汇总详情可通过“阅读原文”获取)。
内容持续更新,现下单“架构师技术全店打包汇总(全)”,后续可享全店内容更新“免费”赠阅,格仅收188元(原总价270元)。
温馨提示:
扫描二维码关注公众号,点击阅读原文链接获取“架构师技术全店资料打包汇总(全)”电子书资料详情。
