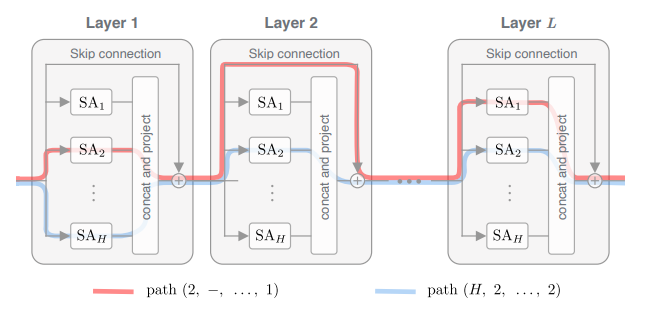
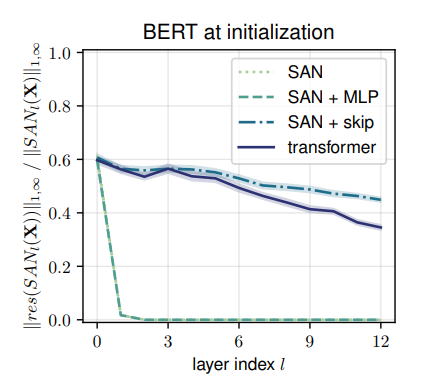
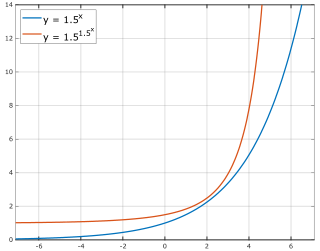
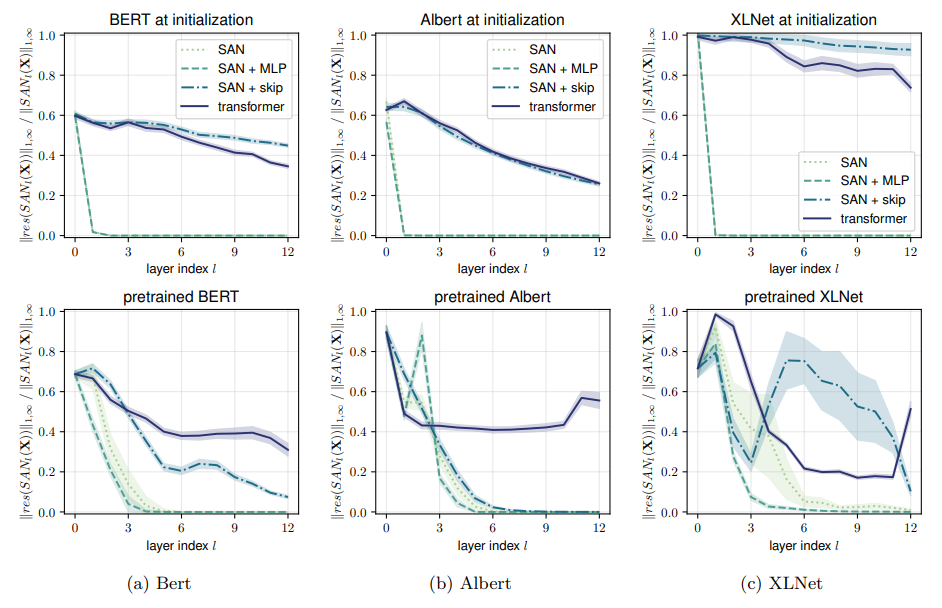
作者 | 青暮基于注意力的架构在机器学习社区中已经变得无处不在,Transformer最初在机器翻译打出名堂,随着BERT的问世几乎统治了整个NLP领域,RNN、LSTM等老前辈瑟瑟发抖,GPT-3的零样本学习能力又令人不禁怀疑其智能本质,还没反应过来,Transformer又打入CV领域,俨然要全面取代CNN的节奏,而DALL-E的出现,也算是打破语言和图像之间界限的开始。近期,人们开始分析Transformer架构的有效性。有人指出,这是基于注意力机制的归纳偏置更弱导致的,从而使其相对于RNN、LSTM、CNN等具有更广泛的适用性。换种说法就是,注意力机制能学习到更加长程的依赖关系。然而,我们真的理解了Transformer有效性背后的秘密了吗?有一篇论文提出了新的观点,标题也颇有意思:论文地址:https://arxiv.org/pdf/2103.03404v1.pdf这是在抬杠Transformer吗?当然也可能是在嘲讽最近人们起标题开始偷懒的现象。简单来说,这篇论文提出了一种理解自注意力网络的新方法,并指出:实验证明,在没有跳过连接(残差连接)和多层感知机(MLP)架构的情况下,自注意力网络的表达能力随深度增加而呈双指数形式衰减,或者网络输出以立方速率收敛到秩为1的矩阵,即输出退化。另一方面,跳过连接和MLP的存在会阻止这种输出退化。作者表示,他们发现自注意力有很某种很强的归纳偏置。下图描绘了没有MLP模块的Transformer架构的基本结构。图1:每层具有H个注意力头和L层的深度自注意力网络(SAN)中的两条路径。在每一层,一条路径可以通过一个注意力头或绕过该层。在每个注意力层之后添加一个MLP模块即可构成Transformer架构。下图展示了将BERT改造为纯自注意力网络(SAN)后的秩崩溃现象。所谓的很强的归纳偏置是指什么呢?作者证明了自注意力网络的输出可以分解为较小的项之和,每个项涉及跨层级的一系列注意力头的操作。通过这种分解,证明了自注意力对“token均匀性”具有很强的归纳偏置。此外,双指数形式的收敛又有多快呢?我们可以看看下图来体会一下,总之比指数形式快多了。总之,这篇论文是在说,不是“attention is all you need”,而是“attention+跳过连接+MLP”is all you need。当然,保守点的话可以这么说,Transformer至今为止表现出的有效性,无论是零样本学习、多模态学习还是模态迁移,都离不开跳过连接和MLP的支持。
1
讨论
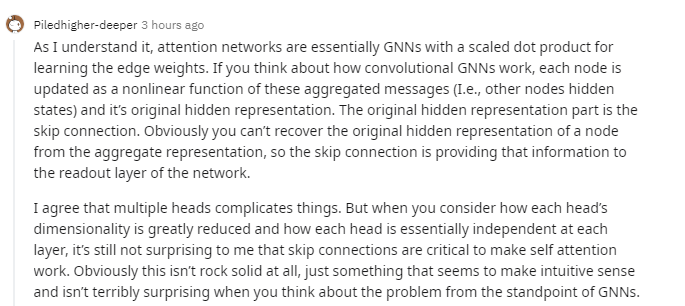
这篇论文在社交网络上引发了众多讨论,比如谷歌研究科学家Christian Szegedy表示:“论文在说仅有自注意力是不够的,但或许仅用注意力是可以的。”佐治亚理工学院ML博士Aran Komatsuzaki回应道:“原始Transformer论文将FFN组件(即全连接网络)称为‘隐藏维度上的注意力’,所以我同意你的看法。”随后,Christian Szegedy又列举了另一篇论文:“Large Memory Layers with Product Keys”,这篇论文介绍了可以轻松集成到神经网络中的结构化记忆模块(structured memory),记忆模块可以在不显著增加模型参数和计算开销的情况下显著提高架构的容量。研究人员发现,只有12层的记忆增强的Transformer模型在语言建模任务中优于24层的基线Transformer模型,并且推理速度更快。所以这是在说,“attention+structured memory”is all you need?然而,讨论戛然而止。我们转到reddit来吃吃瓜。看到这么一个具有挑衅意味的标题,当然是不调侃不放过。网友@Beor_The_Old表示:“哈哈,好兴奋啊,我们接下来就要看到一堆人去水'X is not all you need'的论文啦!”@fmai低调回应:“兄弟,这种好事我早就染指。”AI科技评论的建议是,找找现有的“X is all you need”论文,照着立项就是了,大概有几十个坑位,赶紧抢占吧。言归正传,@Piledhigher-deeper表示,考虑到注意力权重过滤掉的信息量,可以认为论文的结论是正确的。网友@Piledhigher-deeper表示,注意力网络本质上是采用了scaled dot product 的GNN,用于学习连接权重。考虑一下图卷积网络的工作原理,它将每个节点更新为(其他节点的隐藏状态)聚合消息及其原始隐藏表示形式的非线性函数。原始的隐藏表示部分即跳过连接。显然,我们无法从聚合表示中还原节点的原始隐藏表示。因此,跳过连接会将信息提供给网络的读出层。多个注意力头会模型复杂化。但是,当考虑在训练过程中每个注意力头的尺寸显著减小以及每个注意力头在每一层上基本独立时就能明白,跳过连接对于使自注意力发挥作用至关重要。总之,当从GNN的角度考虑问题时,这并不令人感到意外。读者们,你们怎么看呢?






 下载APP
下载APP