CeiT:训练更快的多层特征抽取ViT
【GiantPandaCV导语】
来自商汤和南洋理工的工作,也是使用卷积来增强模型提出low-level特征的能力,增强模型获取局部性的能力,核心贡献是LCA模块,可以用于捕获多层特征表示。相比DeiT,训练速度更快。
引言
针对先前Transformer架构需要大量额外数据或者额外的监督(Deit),才能获得与卷积神经网络结构相当的性能,为了克服这种缺陷,提出结合CNN来弥补Transformer的缺陷,提出了CeiT:
(1)设计Image-to-Tokens模块来从low-level特征中得到embedding。
(2)将Transformer中的Feed Forward模块替换为Locally-enhanced Feed-Forward(LeFF)模块,增加了相邻token之间的相关性。
(3)使用Layer-wise Class Token Attention(LCA)捕获多层的特征表示。
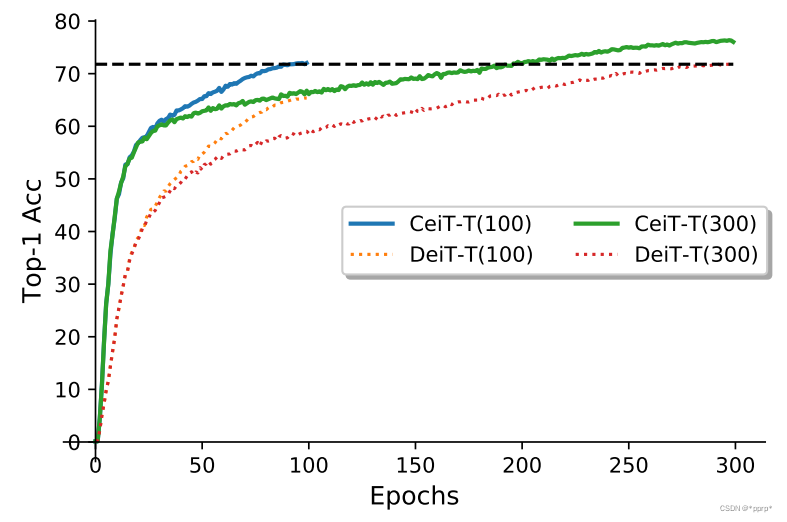
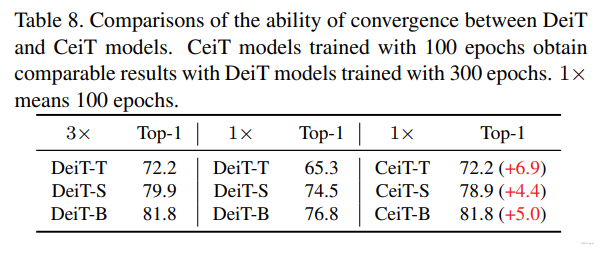
经过以上修改,可以发现模型效率方面以及泛化能力得到了提升,收敛性也有所改善,如下图所示:
方法
1. Image-to-Tokens
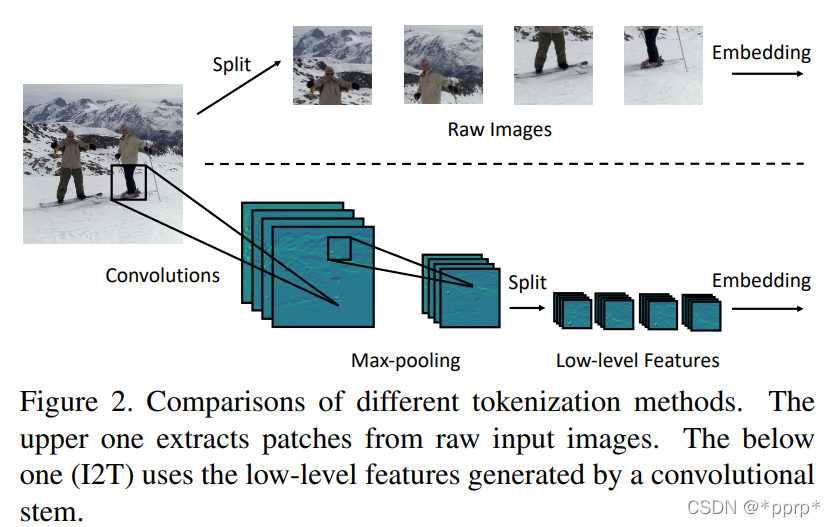
使用卷积+池化来取代原先ViT中7x7的大型patch。
2. LeFF
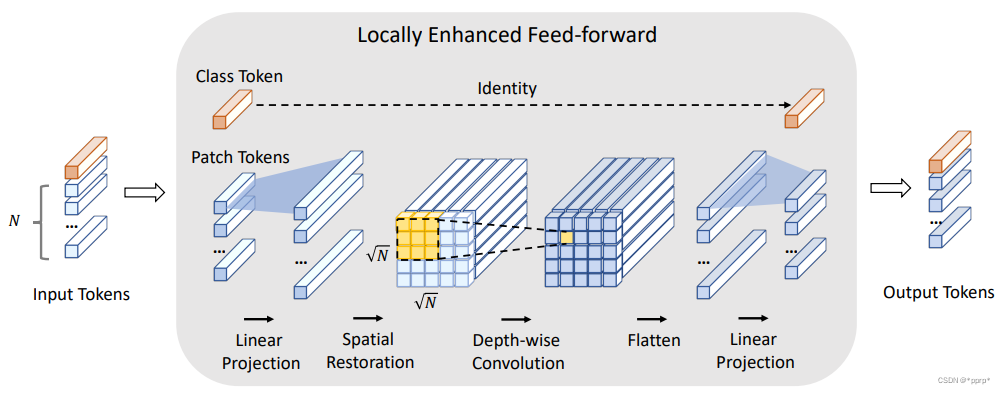
将tokens重新拼成feature map,然后使用深度可分离卷积添加局部性的处理,然后再使用一个Linear层映射至tokens。
3. LCA
前两个都比较常规,最后一个比较有特色,经过所有Transformer层以后使用的Layer-wise Class-token Attention,如下图所示:
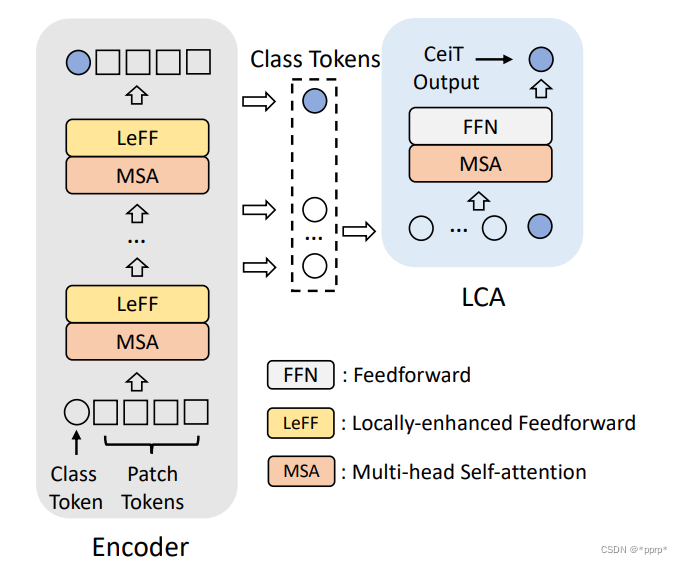
LCA模块会将所有Transformer Block中得到的class token作为输入,然后再在其基础上使用一个MSA+FFN得到最终的logits输出。作者认为这样可以获取多尺度的表征。
实验
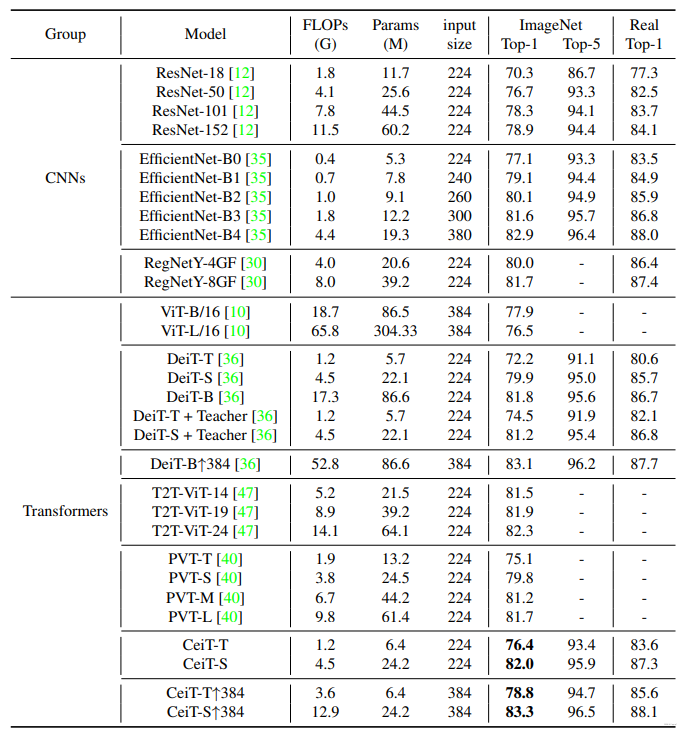
SOTA比较:
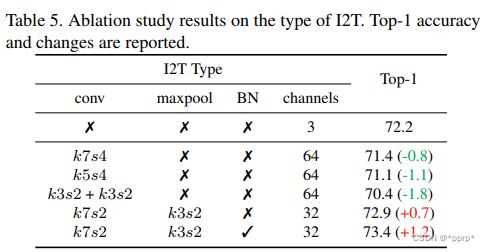
I2T消融实验:
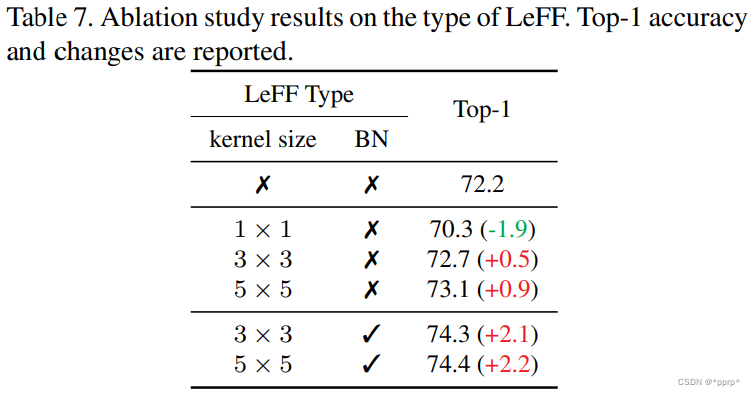
LeFF消融实验:
LCA有效性比较:

收敛速度比较:
代码
模块1:I2T Image-to-Token
# IoT
self.conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, conv_kernel, stride, 4),
nn.BatchNorm2d(out_channels),
nn.MaxPool2d(pool_kernel, stride)
)
feature_size = image_size // 4
assert feature_size % patch_size == 0, 'Image dimensions must be divisible by the patch size.'
num_patches = (feature_size // patch_size) ** 2
patch_dim = out_channels * patch_size ** 2
self.to_patch_embedding = nn.Sequential(
Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = patch_size, p2 = patch_size),
nn.Linear(patch_dim, dim),
)
模块2:LeFF
class LeFF(nn.Module):
def __init__(self, dim = 192, scale = 4, depth_kernel = 3):
super().__init__()
scale_dim = dim*scale
self.up_proj = nn.Sequential(nn.Linear(dim, scale_dim),
Rearrange('b n c -> b c n'),
nn.BatchNorm1d(scale_dim),
nn.GELU(),
Rearrange('b c (h w) -> b c h w', h=14, w=14)
)
self.depth_conv = nn.Sequential(nn.Conv2d(scale_dim, scale_dim, kernel_size=depth_kernel, padding=1, groups=scale_dim, bias=False),
nn.BatchNorm2d(scale_dim),
nn.GELU(),
Rearrange('b c h w -> b (h w) c', h=14, w=14)
)
self.down_proj = nn.Sequential(nn.Linear(scale_dim, dim),
Rearrange('b n c -> b c n'),
nn.BatchNorm1d(dim),
nn.GELU(),
Rearrange('b c n -> b n c')
)
def forward(self, x):
x = self.up_proj(x)
x = self.depth_conv(x)
x = self.down_proj(x)
return x
class TransformerLeFF(nn.Module):
def __init__(self, dim, depth, heads, dim_head, scale = 4, depth_kernel = 3, dropout = 0.):
super().__init__()
self.layers = nn.ModuleList([])
for _ in range(depth):
self.layers.append(nn.ModuleList([
Residual(PreNorm(dim, Attention(dim, heads = heads, dim_head = dim_head, dropout = dropout))),
Residual(PreNorm(dim, LeFF(dim, scale, depth_kernel)))
]))
def forward(self, x):
c = list()
for attn, leff in self.layers:
x = attn(x)
cls_tokens = x[:, 0]
c.append(cls_tokens)
x = leff(x[:, 1:])
x = torch.cat((cls_tokens.unsqueeze(1), x), dim=1)
return x, torch.stack(c).transpose(0, 1)
模块3:LCA
class LCAttention(nn.Module):
def __init__(self, dim, heads = 8, dim_head = 64, dropout = 0.):
super().__init__()
inner_dim = dim_head * heads
project_out = not (heads == 1 and dim_head == dim)
self.heads = heads
self.scale = dim_head ** -0.5
self.to_qkv = nn.Linear(dim, inner_dim * 3, bias = False)
self.to_out = nn.Sequential(
nn.Linear(inner_dim, dim),
nn.Dropout(dropout)
) if project_out else nn.Identity()
def forward(self, x):
b, n, _, h = *x.shape, self.heads
qkv = self.to_qkv(x).chunk(3, dim = -1)
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h = h), qkv)
q = q[:, :, -1, :].unsqueeze(2) # Only Lth element use as query
dots = einsum('b h i d, b h j d -> b h i j', q, k) * self.scale
attn = dots.softmax(dim=-1)
out = einsum('b h i j, b h j d -> b h i d', attn, v)
out = rearrange(out, 'b h n d -> b n (h d)')
out = self.to_out(out)
return out
class LCA(nn.Module):
# I remove Residual connection from here, in paper author didn't explicitly mentioned to use Residual connection,
# so I removed it, althougth with Residual connection also this code will work.
def __init__(self, dim, heads, dim_head, mlp_dim, dropout = 0.):
super().__init__()
self.layers = nn.ModuleList([])
self.layers.append(nn.ModuleList([
PreNorm(dim, LCAttention(dim, heads = heads, dim_head = dim_head, dropout = dropout)),
PreNorm(dim, FeedForward(dim, mlp_dim, dropout = dropout))
]))
def forward(self, x):
for attn, ff in self.layers:
x = attn(x) + x[:, -1].unsqueeze(1)
x = x[:, -1].unsqueeze(1) + ff(x)
return x
参考
https://arxiv.org/abs/2103.11816
https://github.com/rishikksh20/CeiT-pytorch/blob/master/ceit.py
为了感谢读者的长期支持,今天我们将送出三本由 机械工业出版社 提供的:《从零开始构建深度前馈神经网络》 。点击下方抽奖助手参与抽奖。没抽到并且对本书有兴趣的也可以使用下方链接进行购买。

本书通过Python+NumPy从零开始构建神经网络模型,强化读者对算法思想的理解,并通过TensorFlow构建模型来验证读者亲手从零构建的版本。前馈神经网络是深度学习的重要知识,其核心思想是反向传播与梯度下降。本书从极易理解的示例开始,逐渐深入,帮助读者充分理解并熟练掌握反向传播与梯度下降算法,为后续学习打下坚实的基础。