
如何在超大分辨率的图片中检测目标?
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文通过一篇YOLT的文章引出超大分辨率的图片遇到目标检测任务该如何处理?此类问题一般出现在遥感领域和医疗影像中居多,我们先来分析超大图像的目标检测存在哪些问题,然后学习一下YOLT是如何解决这些问题的,最后结合现有技术探讨目前的可行性方案。
曾经有小伙伴问过我针对超大分辨率的图像如何做目标检测任务?
我们先思考一下超大分辨率数据在哪些场景中会出现,比如卫星地图做建筑物、楼宇的检测:
在医疗影像中做病灶体的检测:
在无人机航拍图中做船舶、车辆、房屋等检测:

是否可以沿用通用框架做该类图片的目标检测呢?
输入如此大分辨率的图片到网络中,最直接的问题就是机器的显存爆掉,无法进行训练任务。
如果你真的有一个非常牛逼的集群直接训练大尺寸图像,最后的预测结果恐怕也不尽如人意,原因出在大尺寸图像中的目标往往只占5-10个像素点,检测网络一旦经过多次下采样后,这些小目标的特征很难被提取到。
卫星地图等数据非常稀有珍贵,不像无人驾驶的开源数据有几十万几百万张的量级,如何高效的利用高质量的训练图片也是关键所在。
所以直接硬上通用模型检测出来的效果可能是这样的,要么伴随着图片的resize,目标被缩放没了;要么基于N×N网格的预测造成密集连续目标的漏检:

此类任务的难点或者优化方向在哪里?
它的核心在于四个方向:
如何处理高分辨的输入
如何提高密集小目标检测
如何解决类别不平衡问题
如何利用少量的训练数据
下面我们通过一篇名为You Only Look Twice的文章来分析上述几个问题,名称有点蹭热度的嫌疑哦,不过谁让YOLO系列那么火,大家都喜欢在它的框架上改改发文章呢!
《Rapid Multi-Scale Object Detection In Satellite Imagery》这篇文章描述了大尺寸图像目标检测的常规方法,总的来说就是对超大分辨率的图像进行滑窗裁剪成多个子图,然后对每一个子图进行目标检测,最后将所有子图的结果拼接后进行NMS过滤。
数据端
对超大分辨率图片进行滑窗裁剪,如下图所示,一个16000×16000像素的图片,采用416×416像素的滑窗,最后生成约1500个子图。

文章指出在滑窗裁剪的时候必须有15%的重叠区域,原因是如果一个目标刚好处于窗口边缘被切分成2块,本身目标所占像素就少又被截断会造成更加难以检测。但是重复部分会带来同一个目标出现多个检测框的问题,目前通过将所有子图的检测结果合并起来采用NMS处理进行过滤。
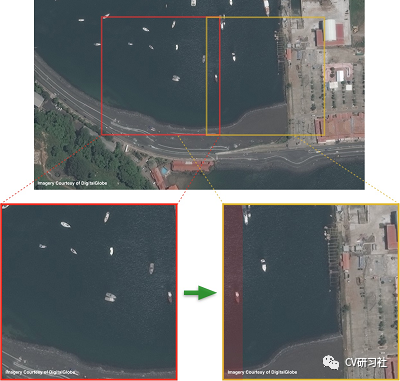
在卫星、遥感、航拍等图片中,目标物体往往存在方向信息,如何提高目标检测的旋转不变性呢?在YOLT中通过数据增广的方式旋转图片生成更多形状的物体从而缓解问题。但是小编认为该方法治标不治本,输出结果仍然是规则的矩形框,一旦遇到长条形物体,比如轮船。预测的矩形框会引入很多冗余区域。可以尝试在损失函数中增加旋转角进行学习。

网络端
基于YOLOv2的结构做了一些改进,在YOLO系列或者很多检测网络都进行了32倍的下采样,但是在遥感地图等超大分辨率图片中,目标物体所占像素本身就很少,经过32倍下采样后,基本无法有效检测。所以YOLT减少了下采样的比例收缩到16倍并增加网络的层数提供特征提取能力。
文章借助YOLOv2中的PassThrough层,融合深浅特征图的特征目的是提升对小目标的检测效果。当然这一操作完全可以考虑由PAN替代,在FPN上采样融合的特征金字塔之后,又增加了一个下采样融合的特征金字塔。
本文并没有提到类别不平衡问题,但是任何目标检测任务其实都存在前后背景的不平衡,一般会从三种方法进行考虑,其一是做数据的上采样和下采样来平衡不同类别之间的数据量;其二是采用某些数据增广的手段来增多前景目标在一张图像中的占比;其三是通过设计损失函数通过权重控制不同类别的优化力度。
较常见的方式就是像上述文章提到的对一张超大分辨率的图片切割成多个子图,但是在这一过程中存在几个问题,比如:
目标位于切割边缘怎么办?
切割的图片大小如何设置?
目标切割的问题在上面已经提过,可以用重叠切割的方法解决目标被截断的问题。
假设数据集的图片尺寸不同的前提下,我们可以从结果端反向思考切割尺寸的问题,一般会设置一个固定的子图尺寸比如416×416,但是原图可能无法刚好切割成整数个子图,所以对最边缘的子图可以采用letterbox的方式缩放到416的尺寸,相比直接resize能够保留物体特征。
在目标检测领域中,小目标检测一直都是其中一个难点。针对该问题,近些年也提出了不少优化的方式:
图像金字塔进行多尺度训练。将原始图像生成多个不同分辨率的图像金字塔,再对每层金字塔用固定输入分辨率的分类器在该层滑动来检测目标。不过此方法需要对图像做多次的特征提取,速度太慢。该方法也有改进版本,如SNIP网络只训练合适尺寸的目标,当真值的尺寸和Anchor接近时才训练检测器,过大过小的均丢弃。
特征金字塔融合浅层和深层信息,如FPN和PAN等。通过各层融合的方式从浅层网络中学习更多的细节特征,从深层网络中学习更多的语义特征。
设计与小目标尺寸匹配的Anchor。不同任务的检测目标尺寸均有差异,可以根据先验知识,采用手工或者聚类的方式离线得到一定个数的Anchor。
采用空洞卷积减少下采样次数,其目的是考虑下采样会丢失图片的部分信息,而空洞卷积能够在不增加参数量的同时具有更大的感受野,提供降低采样次数的一种思路。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~