
如何在GPU资源受限情况下微调超大模型
大数据文摘授权转载自数据派THU 作者:Stanislav Belyasov 翻译:陈之炎 校对:赵茹萱


梯度积累/微批量; 梯度检查点; 模型并行训练; 管道作业; 张量并行化 混合精度训练; 内存卸载; 优化器8位量化。
简单模式:无法适配批大小为1 专业模式:参数也没办法适配
概述
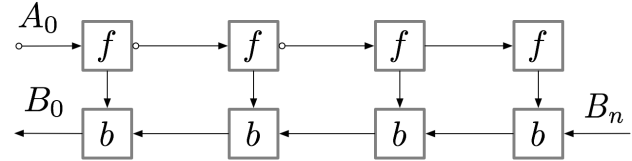
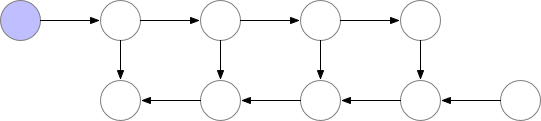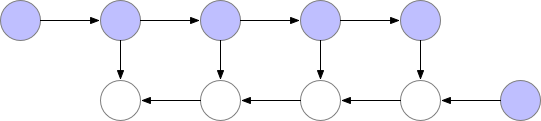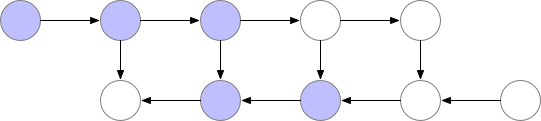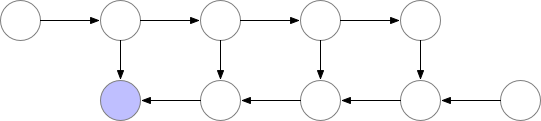
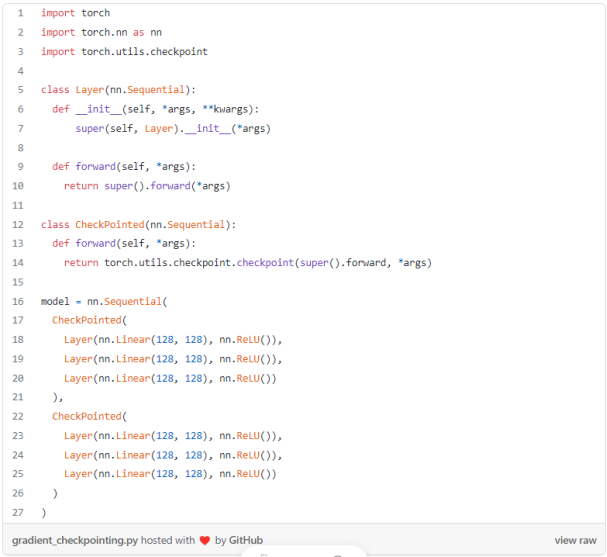
梯度检查点
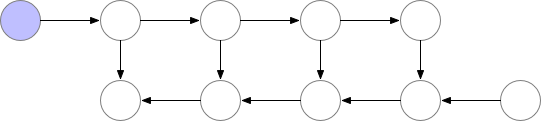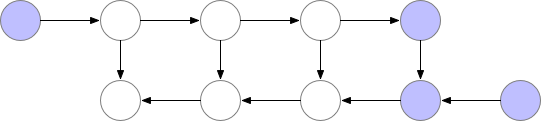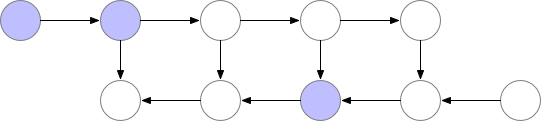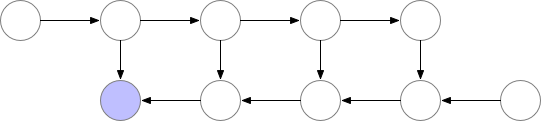
例程:

概述
什么是梯度累积?
例程:


重点
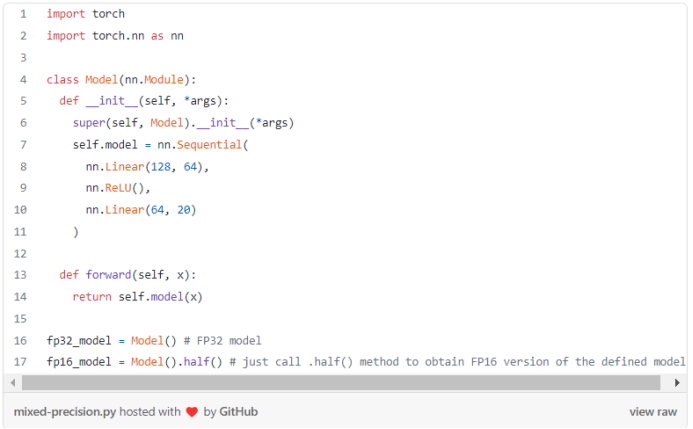
概述
主要优势
减少内存使用; 性能提速(更高的算术强度或更小的通信占用); 使用专用硬件进行更快地计算。
例程:

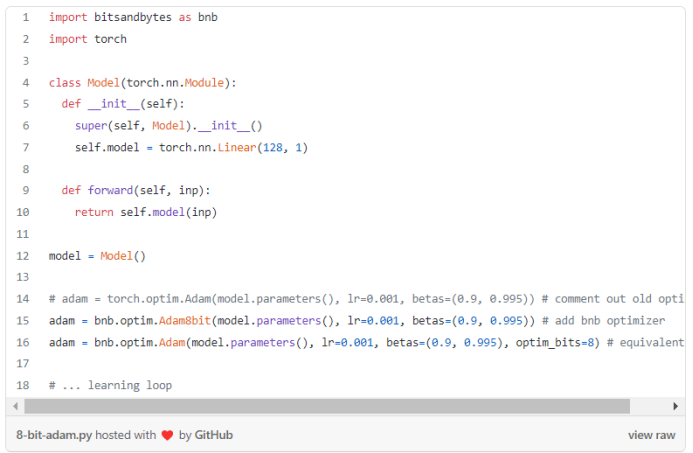
例程:
综合上述全部方法,对GPU上的GPT-2-XL进行微调。
梯度检查点; 混合精度训练(我设了一个技巧:使用相同模型的两个样本。首先,用.half将它加载到GPU上,将其命名为gpu_model;其次,在CPU上,将其命名为cpu_model。评估好GPU模型之后,将 gpu_model的梯度加载到cpu_model中,运行optimizer.step(),将更新后的参数加载到gpu_model上); 使用batch_size=64,minibatch_size=4的梯度累积,需要通过 accumulation_steps来缩放损失; 8位Adam优化器。

评论