Youtube的value-based强化学习推荐系统
| 研究方向:推荐系统、强化学习
本文介绍Youtube在2019年放出的两篇强化学习推荐系统中基于value-based的一篇,论文标题:SLATEQ: A Tractable Decomposition for Reinforcement Learning with Recommendation Sets (IJCAI 2019)

原文地址:
https://arxiv.org/pdf/1905.12767.pdf
https://www.ijcai.org/Proceedings/2019/0360.pdf
强化学习推荐系统快速入门
强化学习算法可以大体分为value-based和policy-based,value-based方法在训练阶段的学习目标是学到一个函数,知道当前状态和动作之后,这个函数可以输出状态下这个动作所能带来的期望的长期价值,记为Q值,或者状态动作值函数;在决策阶段,在一个新的状态下,我们可以根据训练好的函数,尝试可选动作集合中的每一个动作,最终采取Q值最大的动作,这样就可以带来最大的长期收益。本文主要讨论value-based的强化学习推荐系统。
上面的介绍中涉及到的强化学习中的主要元素及其在推荐系统中的对应部分:
动作(action):推荐内容,如抖音中的一条视频,或淘宝中的一个商品页(包含多个物品) 奖励(reward):用户的即时反馈,如用户是否点击,或者浏览时间 状态(state):强化学习推荐系统的agent的状态是对环境以及自身所处情况的刻画,可以简单理解为用户历史行为日志
论文要点
强化学习的推荐系统主要优势在于可以考虑长期收益,如用户的长期参与度。但是在一些需要推荐多个物品的场景下,例如youtube的网站首页,会一次放出几十个视频,此时模型需要考虑不同视频的组合,而一个物品的排列组合就是一个动作,这时待选动作的数目就会十分巨大。而Youtube的这篇论文主要考虑如何对原始的value-based方法的Q函数进行分解,来更好的处理这种一个动作就是一个物品组合的推荐场景。在实验阶段,youtube考虑使用离线的模拟实验(训练用户模拟器)和youtube的在线实验,发现用户参与度相对于传统的短期推荐系统有明显增益。
问题分析
在动作空间中,包含k个物品的推荐列表就有种可能,这个运算符在youtube这种k值一般在几十(刚才去数了一下,首页50+)的网站就很离谱,更不要提前面的了。
动作空间这么大,就会带来一些问题:
很难进行充分的探索;另外,如果想要在大量的推荐列表之间进行泛化,就需要有这些推荐列表的稠密表示,但是很多列表并不会在现实中出现,我们并不知道这些没出现过的列表会得到怎样的奖励,也就是说,我们没有关于这些列表的转移元组。 如何找到Q最大的物品组合,这是一个组合优化问题。如果不另加结构性的假设或近似,这个问题会难以求解,无法满足线上服务时延要求。
解决方案
为此,文中提出了两个关键假设,基于这两个假设,就可以把Q值分解为两部分:item-wise的Q值部分,和关于所有item的整体Q值部分,从而降低求解最优推荐列表的时间复杂度。两个假设分别是:
Single choice(SC): 即假设用户每次只选择一个物品,或者不选择。 Reward/transition dependence on selection (RTDS): 奖励和状态的转移只依赖于用户选择的物品。
直观上两个假设看起来都比较符合直觉,没有对现实场景做太大的简化。
基于RTDS假设,奖励的分布和状态的转移分布就可表示为:
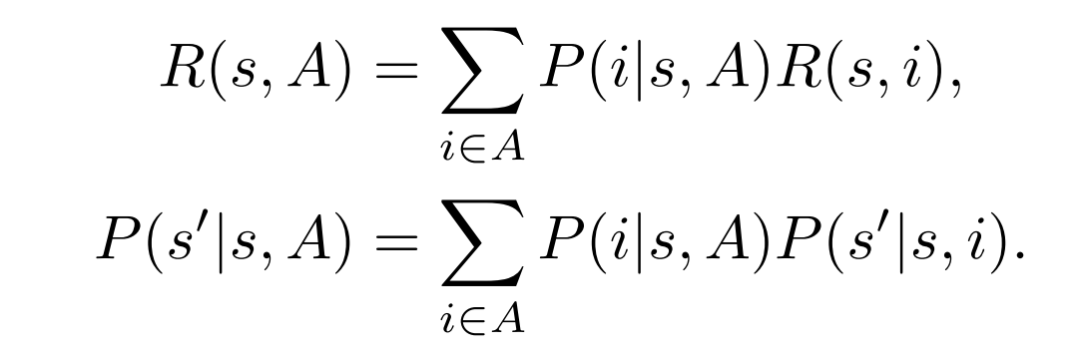
进一步就可以定义出item-wise的Q函数:
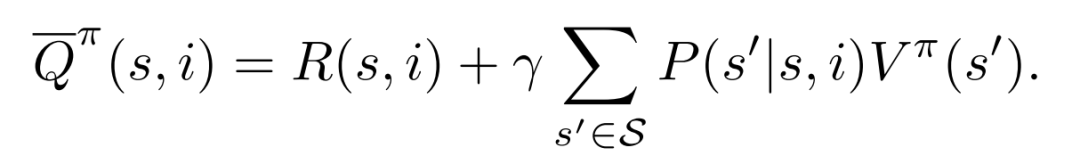
如果用item-wise的Q函数来表示,就得到了:
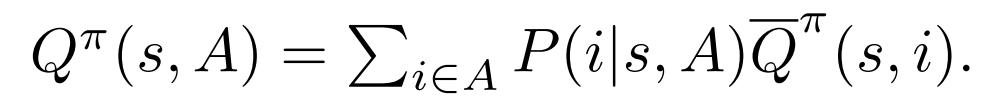
推导过程用到了SC与RTDS假设,主要是从11式到12式的推导需要用这两个假设:
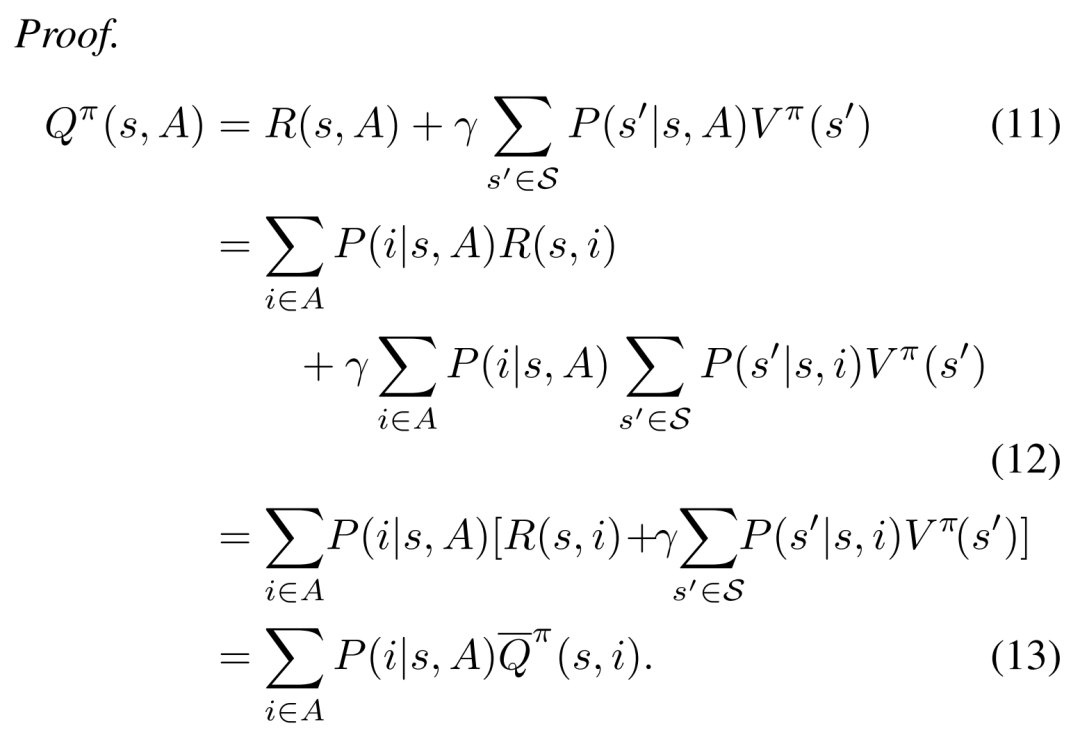
看了这个推导,给人的感觉就是作者在思考问题并写这些11式的公式时发现时间复杂度太大,然后顺其自然的想到了这两条假设。
最终的结果只依赖于,其中的只是一个物品而已,而非一个组合,用传统的TD error就可以训练出;最终结果还包括,也就是预测状态下,给定列表用户选择各个物品的概率,这就是一个pctr预测问题了,有很多成熟的解决方案。
在训练时,为了得到最优的策略,我们也要训练最优策略对应的Q函数,而这只需要在训练过程中,依据Q最大的就是最好的的准则,来贪心的选择即可。
最终的长期收益优化目标:
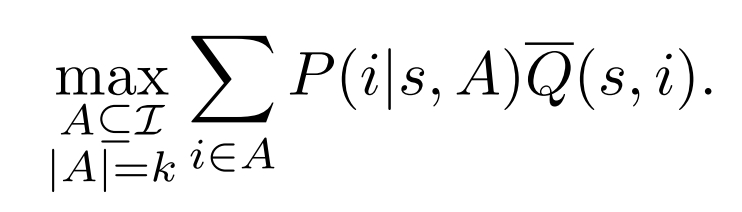
最终这样一个优化目标可以被看做一个分数线性规划问题,并且可以在多项式时间内解决:
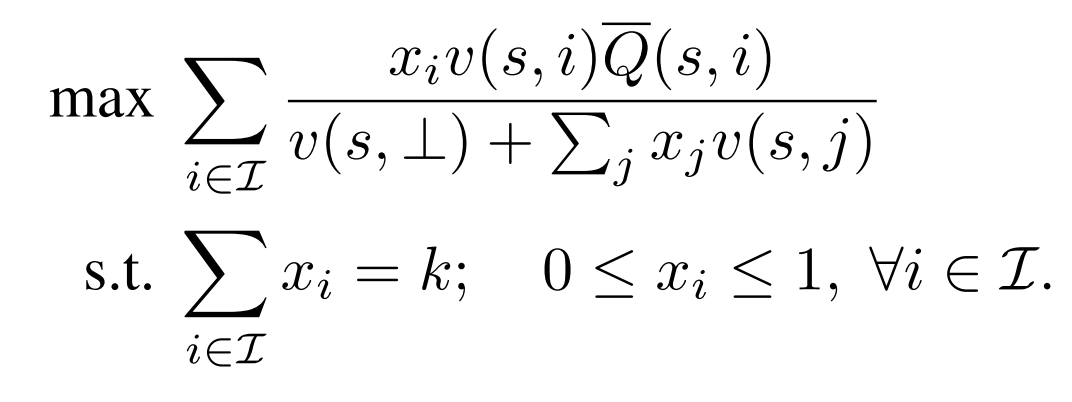
这里代表用户对一个物品的未正则化的点击概率。
虽然这里物品的集合数目巨大,但是现实中这里的物品集合应该是粗排并且被一些产品策略过滤之后的结果,因此数目会比总物品数少很多。关于优化问题的简化过程,细节请参考原文。
在线上服务时,为了避免每次请求都有接一个多项式时间复杂度的线性规划问题,文章还提出了两种近似的方法:
Top-K: 计算每个物品的期望奖励,选择倒序排序最大的k个作为最终的推荐列表。在选择物品列表的第L个物品并需要计算物品奖励时,不会考虑前L-1个物品。 Greedy: 考虑物品列表的第L个时,考虑其边际收益,边际收益会考虑前L-1个物品计算得到:
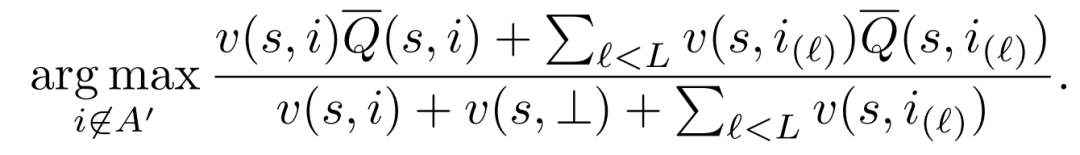
实验效果
实验包括两部分,离线部分与在线部分:离线部分构建了一个用户模拟器来模拟用户行为,在线部分是在youtube网站上线来取得效果的。用户模拟器是根据用户的历史行为数据通过简单训练的方式训练方式得到的,此前也介绍过一篇类似的文章,这里不再过多介绍。
离线实验
这里对比了随机模型,近视模型(MYOP,把奖励的折扣因子设置为0,这样模型就不会考虑长期奖励),SARSA以及Q-Learning在训练阶段就使用不同的决策方式,和使用不同的线上服务方式(第一个字母,T: top-K; G: greedy; O: Optimal; 第二个字母,T: traing; S: serving)的对比实验:
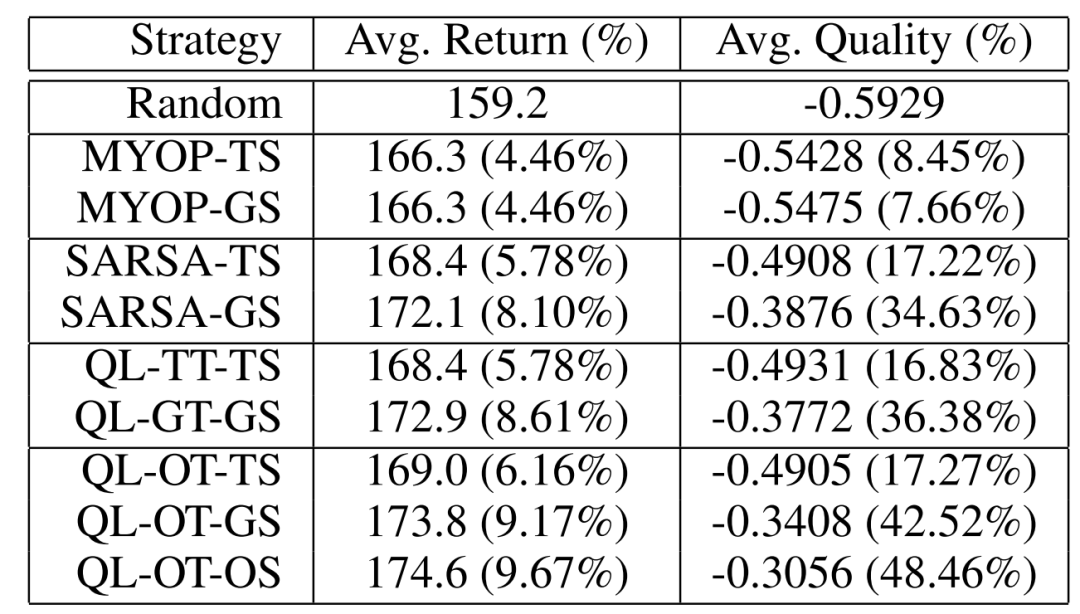
可以看到,greedy的线上服务方式相比于优化的方式,性能损失不大;而top-k的方式损失很大。
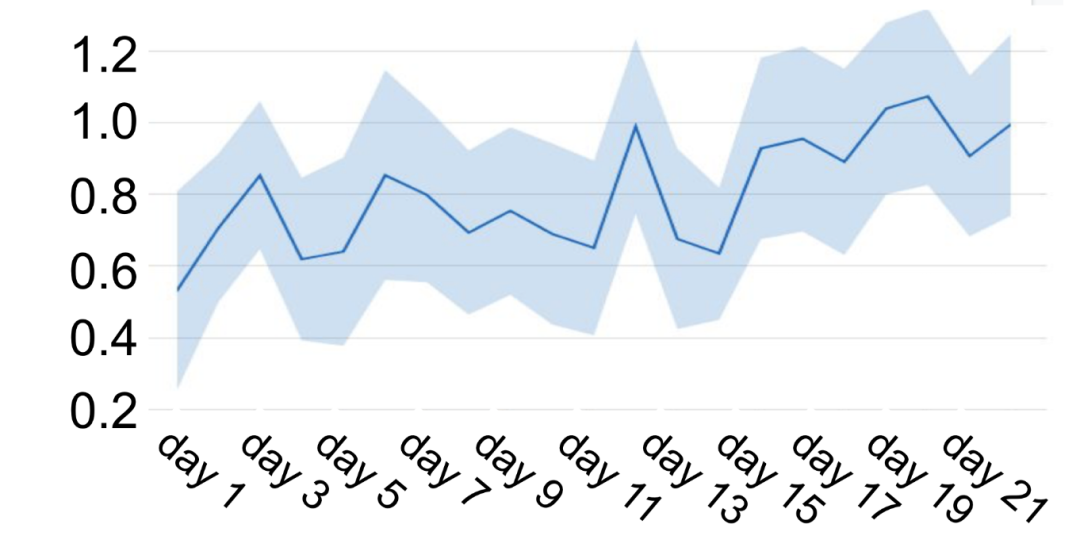
在线实验
对比的指标是用户参与度,baseline是youtube当前的监督模型,可以看到性能提升还是十分显著的,也证明了强化学习在推荐系统上落地是可以带来收益的: