
深入理解YouTube推荐系统算法!
一、背景介绍
数据规模:YouTube 的用户和视频量级都是十亿级别的,需要分布式学习算法和高效的部署。
新颖性:推荐系统需要及时对新上传的视频和用户的新行为作出响应。
数据噪音:由于稀疏和外部因素影响,用户的历史行为很难预测。大部分 YouTube 视频只有隐式反馈(即用户对视频的观看行为),缺少显式反馈(即用户对视频的评分)。此外,视频的元信息不够有结构性。我们的算法需要对训练数据的这些因素稳健(robust)。
二、系统概览
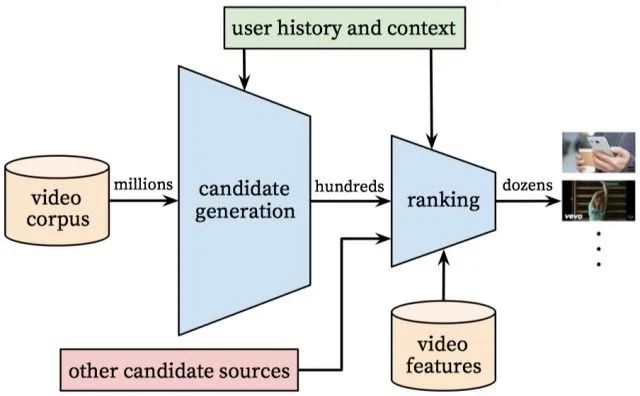
三、Matching
商品的Embedding空间和用户的Embedding空间如何保证在同一个空间。
需要计算与所有商品的内积,存在性能问题。
诸如奇异值分解的方法,输入协同矩阵,特征比较单一。
 和其上下文
和其上下文  ,在
,在  时刻,将视频库
时刻,将视频库  中指定的视频
中指定的视频  划分为第
划分为第  类的概率。公式如下:
类的概率。公式如下:
其中
 表示(用户,上下文)的高维embedding,
表示(用户,上下文)的高维embedding,  表示每个候选视频的embedding向量。
表示每个候选视频的embedding向量。  表示第
表示第  个视频的embedding向量,这里每个视频都有一个embeeding向量表示。
个视频的embedding向量,这里每个视频都有一个embeeding向量表示。 ,作为输入送到softmax classifier,用以生成初步候选集作为视频召回结果。 中所有的视频,并且用户上下文向量与视频向量之间的点积,exp等操作造成计算量过大,因此如何高效训练成为一个问题。其解决方法采用了负采样机制(sample negative classes )提升训练速度,并使用重要性加权(importance weighting)的方式校正这个采样。对于每个样本,对真实标签和采样得到的负类,最小化其交叉熵损失函数。相比经典 Softmax,这有几百倍的速度提升。
,作为输入送到softmax classifier,用以生成初步候选集作为视频召回结果。 中所有的视频,并且用户上下文向量与视频向量之间的点积,exp等操作造成计算量过大,因此如何高效训练成为一个问题。其解决方法采用了负采样机制(sample negative classes )提升训练速度,并使用重要性加权(importance weighting)的方式校正这个采样。对于每个样本,对真实标签和采样得到的负类,最小化其交叉熵损失函数。相比经典 Softmax,这有几百倍的速度提升。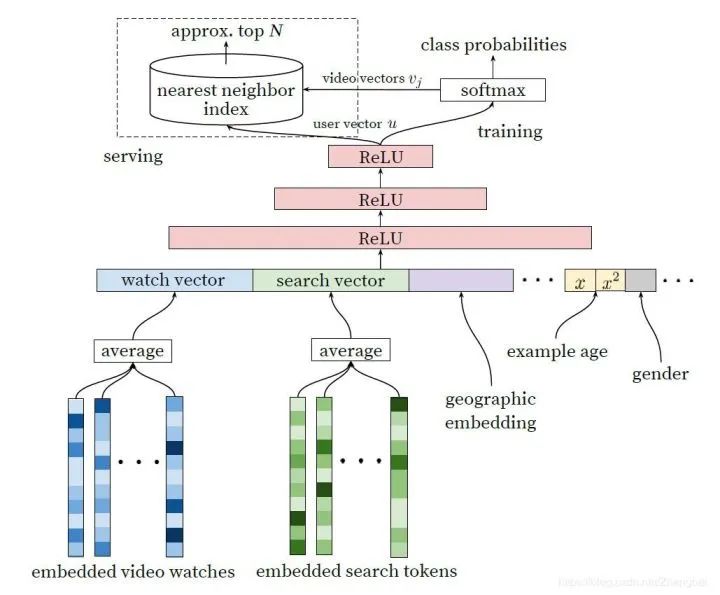
用户观看视频序列ID:对视频ID的embedding向量进行mean pooling,得到视频观看向量(watch vector)。
用户搜索视频序列ID:对视频ID的embedding向量进行mean pooling,得到视频搜索向量(search vector)。
用户地理特征和用户设备特征:均为一些离散特征,可以采用embedding方法或者直接采用one-hot方法(当离散维度较小时),得到用户的地理向量和设备向量
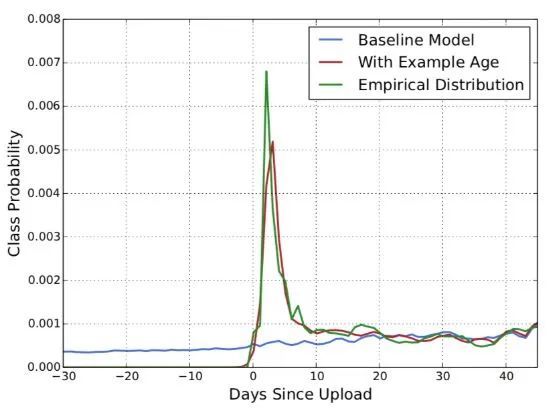
Example Age:在推荐系统中很重要的一点是视频的新颖性,用户更倾向于观看新视频,但机器学习模型都是基于历史观看视频记录学习,所以在某种程度上,模型和业务是相悖的,所以文中构建了一个特征example age,简单的可以理解为是视频的年龄,初始值设为0,随着时间的增长,记录视频的年龄。加入之后效果十分明显,如图所示
5. 人口属性特征:用于提供先验,使其对新用户也能做出合理的推荐。具体来说,对用户 的地理区域和使用的设备进行 Embedding 并将特征进行拼接(concatenation)。
 和用户的 embedding 向量 ,召回任务预测用户 在 时刻观看的视频: 。 ,其维度为 pool_size
和用户的 embedding 向量 ,召回任务预测用户 在 时刻观看的视频: 。 ,其维度为 pool_size ,其中pool_size为训练集视频资源的大小,
,其中pool_size为训练集视频资源的大小,  为embedding的维度。我们还可以得到所以用户的输出向量 ,其中每个用户向量的维度为 维,和视频的embedding 向量维度一致。 和用户向量 进行相似度计算,为了满足时延要求,在进行实际的召回计算时采用的是最近邻查询的方式。对于每个用户向量 ,对视频库中的所有视频根据向量
为embedding的维度。我们还可以得到所以用户的输出向量 ,其中每个用户向量的维度为 维,和视频的embedding 向量维度一致。 和用户向量 进行相似度计算,为了满足时延要求,在进行实际的召回计算时采用的是最近邻查询的方式。对于每个用户向量 ,对视频库中的所有视频根据向量  做最近邻算法,得到top-N的视频作为召回结果。
做最近邻算法,得到top-N的视频作为召回结果。使用更广的数据源:不仅仅使用推荐场景的数据进行训练,其他场景比如搜索等的数据也要用到,这样也能为推荐场景提供一些explore。
为每个用户生成固定数量训练样本:我们在实际中发现的一个practical lessons,如果为每个用户固定样本数量上限,平等的对待每个用户,避免loss被少数active用户domanate,能明显提升线上效果。
抛弃序列信息:我们在实现时尝试的是去掉序列信息,对过去观看视频/历史搜索query的embedding向量进行加权平均。这点其实违反直觉,可能原因是模型对负反馈没有很好的建模。
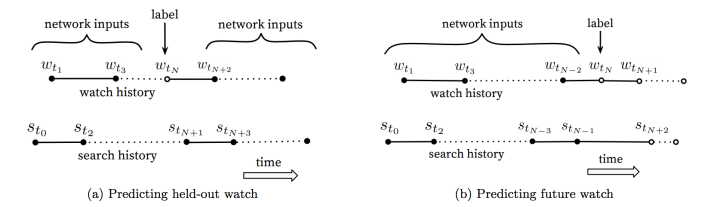
不对称的共同浏览(asymmetric co-watch)问题:所谓asymmetric co-watch值的是用户在浏览视频时候,往往都是序列式的,开始看一些比较流行的,逐渐找到细分的视频。下图所示图(a)是hled-out方式,利用上下文信息预估中间的一个视频;图(b)是predicting next watch的方式,则是利用上文信息,预估下一次浏览的视频。我们发现图(b)的方式在线上A/B test中表现更佳。而实际上,传统的协同过滤算法,都是隐含采样图(a)的held-out的方式,忽略了不对称的浏览模式。
四、Ranking
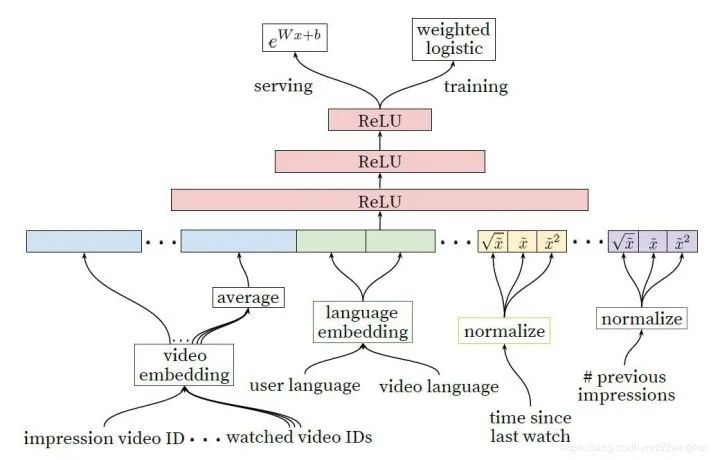
 ,其中
,其中  是样本数量, 是正样本数量,
是样本数量, 是正样本数量, 是观看时长。假设正样本集很小,那么我们学到的优势就近似
是观看时长。假设正样本集很小,那么我们学到的优势就近似  ,
,  是点击概率,
是点击概率,  是观看时间的期望值。因为 很小,那么这个乘积就约等于。我们用指数函数
是观看时间的期望值。因为 很小,那么这个乘积就约等于。我们用指数函数  作为最终的激活函数来产生近似观看时长的估计值。
作为最终的激活函数来产生近似观看时长的估计值。取值数量:分为单值特征,比如当前待展示待打分的视频ID;和多值特征,比如用户过去观看的N个视频ID;
特征描述内容:我们还根据它们描述项目的属性(“印象”)还是用户/上下文(“查询”)的属性来对特征进行分类。每个请求计算一次查询特征,同时为每个已评分项目计算展现特征。
用户历史行为:用户之前和那些items有过交互,或者和相似的items的交互;
上此观看时间:自上次观看同channel视频的时间,原理类似“注意力机制;
之前视频已经被曝光给该用户的次数:如果一个视频之前展示过,用户没有观看,那么用户在下次展示的时候依旧不会观看的概率比较大,其原理类似“exploration”。
的ID个数的对数呈正比增加,即log(unique(values))。这些视频是通过在训练之前扫描一次数据建立的简单查找表。对视频集按照ID在点击展现中出现的频率进行倒序排列,仅保留频率最高的topN个ID,其他的ID就被从视频集中去掉了。不在视频集中的值,简单的被embedding成值为0的向量。像在候选集生成阶段一样,多值离散特征映射成embedding之后,在输入网络之前需要做一下加和平均。 分布的特征
分布的特征  ,等价转化成
,等价转化成 ,用微积分使其均匀的分布在[0,1)区间上。在训练之前,扫描一次数据,用线性插值的方法,基于特征值的分位数近似的计算出该积分。的平方、的平方根,特征的超线性和子线性的函数使得网络有更强的表达能力。输入连续特征的幂值,被证明是能提高离线精度的。这样看似毫无逻辑的特征竟然也有用,可能真的是丰富了特征的表达吧,只能这么理解了。
,用微积分使其均匀的分布在[0,1)区间上。在训练之前,扫描一次数据,用线性插值的方法,基于特征值的分位数近似的计算出该积分。的平方、的平方根,特征的超线性和子线性的函数使得网络有更强的表达能力。输入连续特征的幂值,被证明是能提高离线精度的。这样看似毫无逻辑的特征竟然也有用,可能真的是丰富了特征的表达吧,只能这么理解了。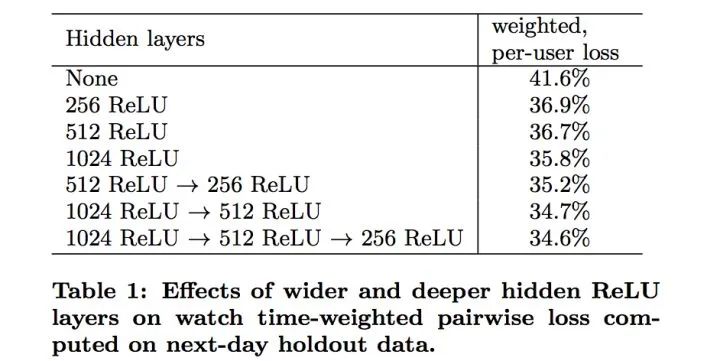
参考文献
[Covington et al., 2016] Paul Covington, Jay Adams, Emre Sargin. Deep Neural Networks for YouTube Recommendations. RecSys: 191-198, 2016.
zhuanlan.zhihu.com/p/52
zhuanlan.zhihu.com/p/61
整理不易,点赞三连↓