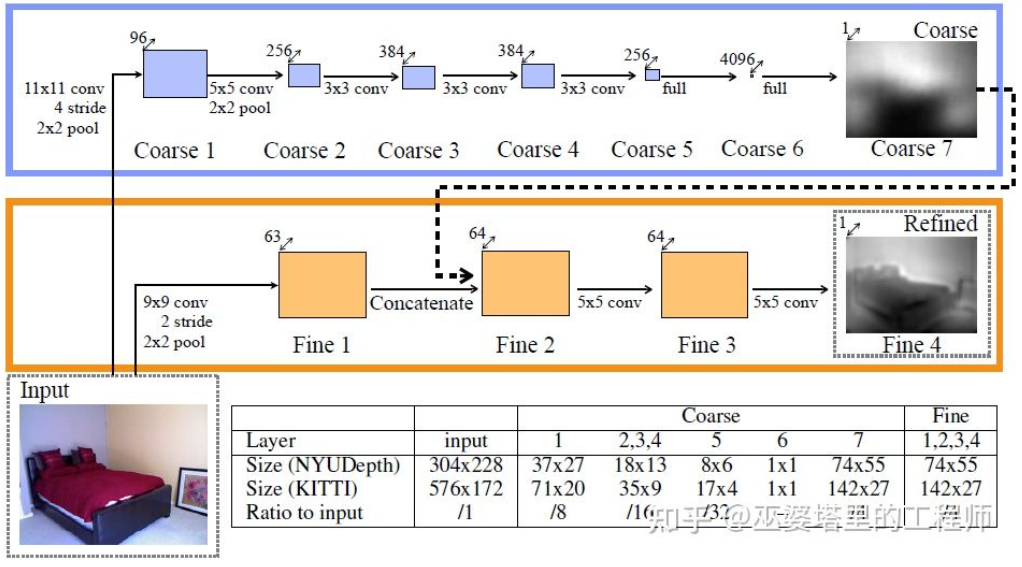
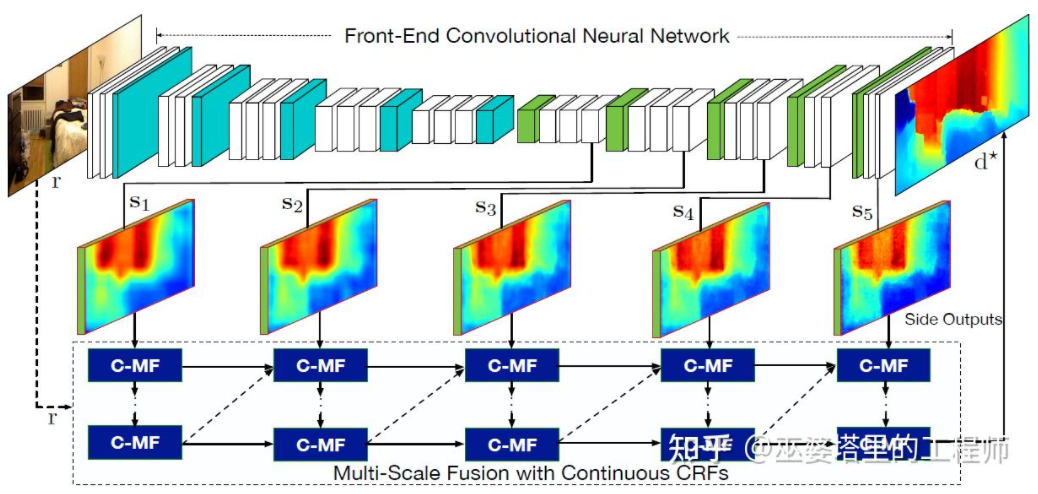
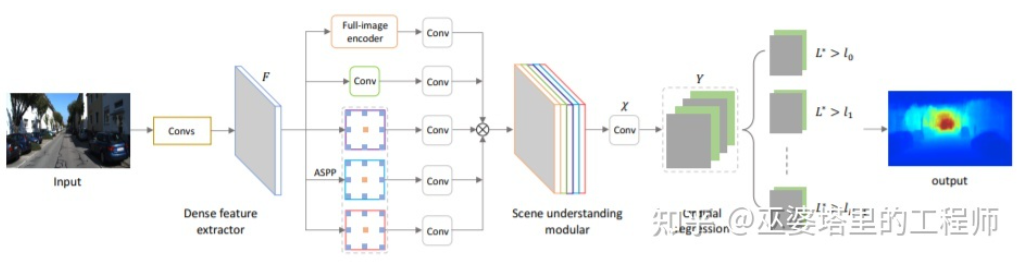
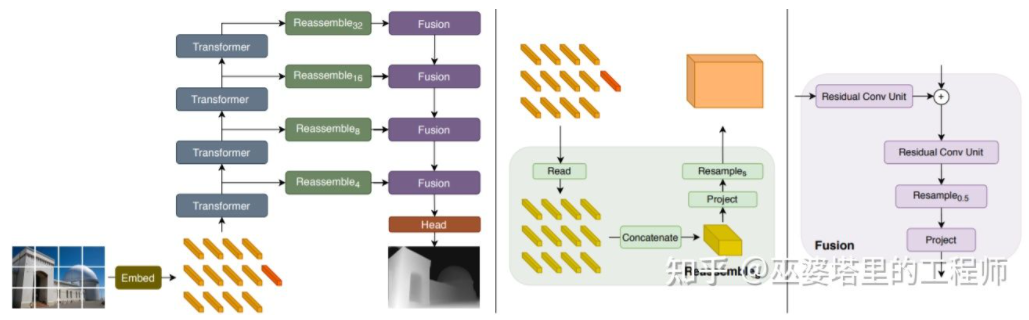
上一小节里介绍了单目3D物体检测的代表性方法,其思路从早期的图像变换,3D模型匹配和2D/3D几何约束,到近期的直接通过图像预测3D信息。这种思路上的变化很大程度上来源于卷积神经网在深度估计上的进展。之前介绍的单阶段3D物体检测网络中大多都包含了深度估计的分支。这里的深度估计虽然只是在稀疏的目标级别,而不是稠密的像素级别,但是对于物体检测来说已经足够了。除了物体检测,自动驾驶感知还有另外一个重要任务,那就是语义分割。语义分割从2D扩展到3D,一种最直接的方式就是采用稠密的深度图,这样每个像素点的语义和深度信息就都有了。综合以上两点,单目深度估计在3D感知任务中起到了非常重要的作用。从上一节3D物体检测方法的介绍可以类推,全卷积的神经网络也可以用来进行稠密的深度估计。下面我们来介绍一下这个方向的发展现状。单目深度估计的输入是一张图像,输出也是一张图像(一般与输入相同大小),其上的每个像素值对应输入图像的场景深度。这个任务有些类似图像语义分割,只不过语义分割输出的是每个像素的语义分类。当然,输入也可以是视频序列,利用相机或者物体运动带来的额外信息来提高深度估计的准确度(对应视频语义分割)。前面提到过,从2D图像预测3D信息是一个病态问题,因此传统的方法会利用几何信息,运动信息等线索,通过手工设计的特征来预测像素深度。与语义分割类似,超像素(SuperPixel)和条件随机场(CRF)这两个方法也经常被用来提高估计的精度。近年来,深度神经网络在各种图像感知任务上都取得了突破性的进展,深度估计当然也不例外。大量的工作都表明,深度神经网络可以通过训练数据学习到比手工设计更加优越的特征。这一小节主要介绍这种基于监督学习的方法。其它一些非监督学习的思路,比如利用双目的视差信息,单目双像素(Dual Pixel)的差异信息,视频的运动信息等等,留待后面再来介绍。这个方向早期的一个代表性工作是由Eigen等人提出的基于全局和局部线索融合的方法[21]。单目深度估计歧义性主要来自于全局的尺度。比如,文中提到一个真实的房间和一个玩具房间可能从图像上看来差别很小,但是实际的景深却差别很大。虽然这是一个极端的例子,但是真实的数据集中依然存在房间和家具尺寸的变化。因此,该方法提出将图像进行多层卷积和下采样,得到整个场景的描述特征,并以此来预测全局的深度。然后,通过另外一个局部分支(相对较高的分辨率)来预测图像局部的深度。这里全局深度会作为局部分支的一个输入来辅助局部深度的预测。全局和局部信息融合[21]文献[22]进一步提出采用卷积神经网络输出的多尺度特征图来预测不同分辨率的的深度图([21]中只有两种分辨率)。这些不同分辨率的特征图通过连续MRF进行融合后得到与输入图像对应的深度图。多尺度信息融合[22]以上两篇文章都是采用卷积神经网络来回归深度图,另外一个思路是把回归问题转换为分类问题,也就是将连续的深度值划分为离散的区间,每个区间作为一个类别。这个方向的代表性工作是DORN[23]。DORN框架中的神经网络也是一个编码解码的结构,不过细节上有些差别,比如采用全连接层解码,膨胀卷积进行特征提取等。DORN深度分类前面提到,深度估计与语义分割任务有着相似之处,因此感受野的大小对深度估计来说也是非常重要的。除了以上提到的金字塔结和膨胀卷积,最近非常流行的Transformer结构具有全局的感受野,因此也非常适合此类任务。文献[24]中就提出采用Transformer和多尺度结构来同时保证预测的局部精确性和全局一致性。Transformer for Dense Prediction
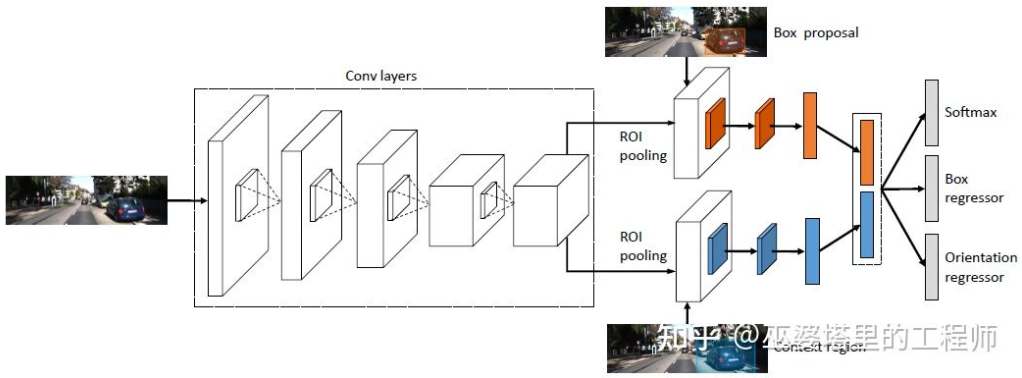
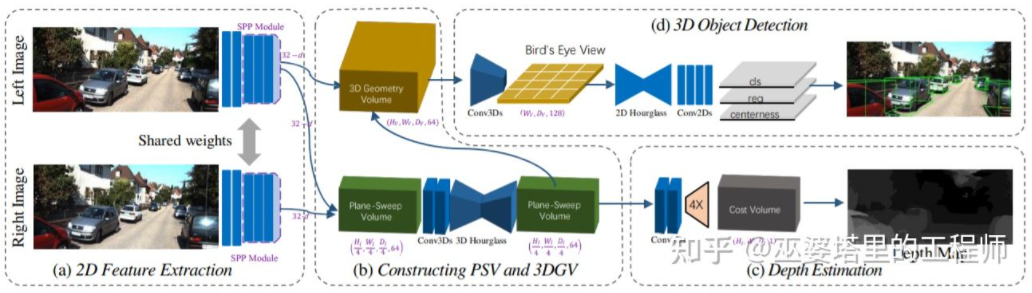
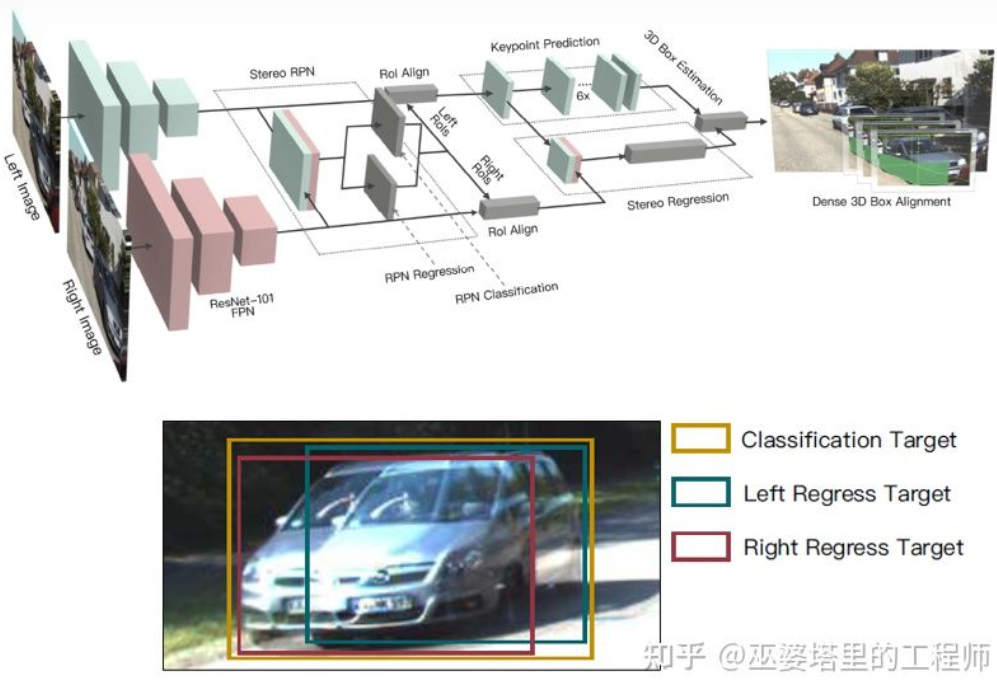
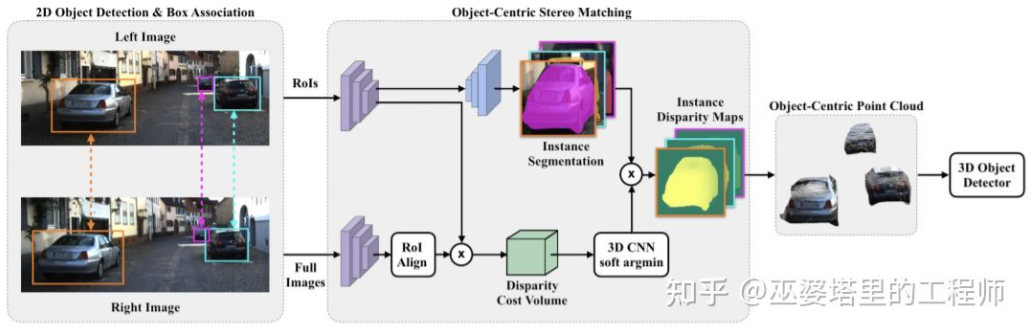
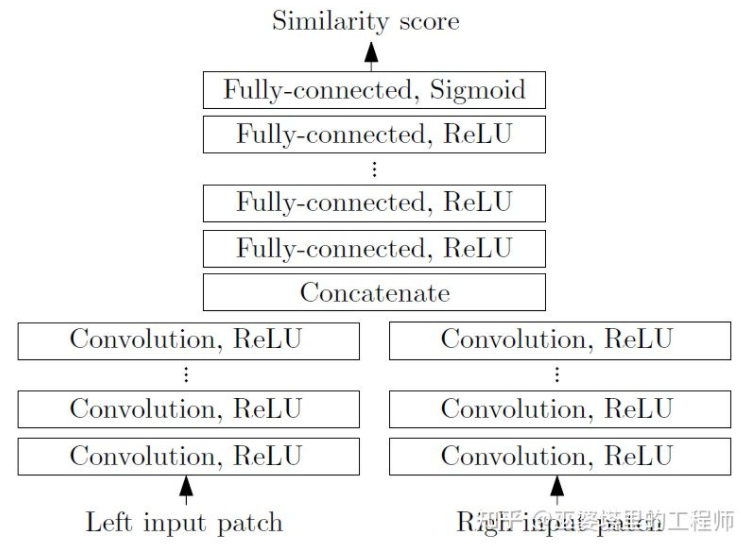
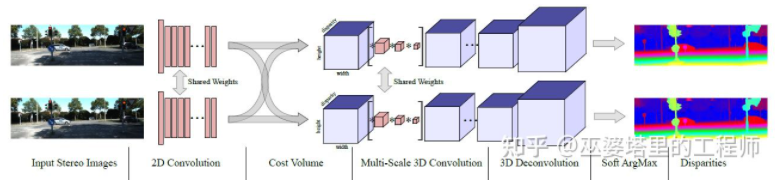
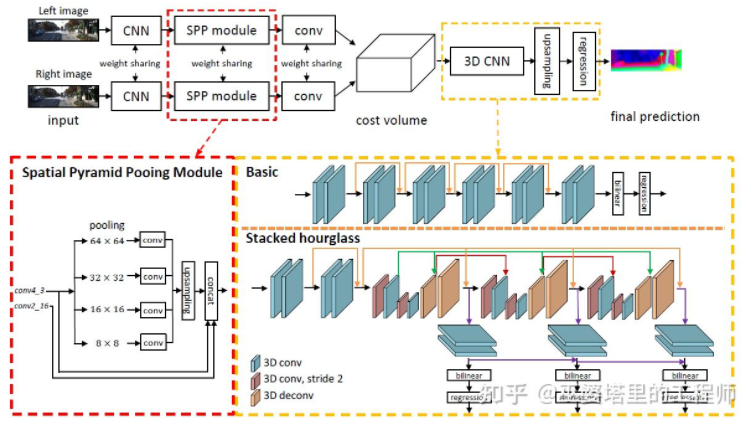
与单目感知算法类似,深度估计在双目感知中也是关键的步骤。从上一小节对双目物体检测的介绍来看,很多算法都采用了深度估计,包括场景级的深度估计和物体级的深度估计。下面就简单回顾一下双目深度估计的基本原理和几个代表性的工作。双目深度估计的原理其实也很简单,就是根据左右两张图像上同一个3D点之间的距离d(假设两个相机保持同一高度,因此只考虑水平方向的距离),相机的焦距f,以及两个相机之间的距离B(基线长度),来估计3D点的深度。在双目系统中,f和B是固定的,因此只需要估计距离d,也就是视差。对于每个像素点来说,需要做的就是找到另一张图像中匹配的点。距离d的范围是有限的,因此匹配的搜索范围也是有限的。对于每一个可能的d,都可以计算每个像素点处的匹配误差,因此就得到了一个三维的误差数据,称之为Cost Volume。在计算匹配误差时,一般都会考虑像素点附近的局部区域,一个最简单的方法就是对局部区域内所有对应像素值的差进行求和:MC-CNN[29]把匹配过程形式化为计算两个图像块的相似度,并且通过神经网络来学习图像块的特征。通过标注数据,可以构建一个训练集。在每个像素点处,都生成一个正样本和负样本,每个样本都是一对图像块。其中正样本是来自同一个3D点的两个图像块(深度相同),负样本则是来自不同3D点的图像块(深度不同)。负样本的选择有很多,为了保持正负样本的平衡,只随机采样一个。有了正负样本,就可以训练神经网络来预测相似度。这里的核心思想其实就是通过监督信号来指导神经网络学习适用于匹配任务的图像特征。MC-CNNMC-Net主要有两点不足:1)Cost Volumn的计算依赖于局部图像块,这在一些纹理较少或者模式重复出现的区域会带来较大的误差;2)后处理的步骤依赖于手工设计,需要花费大量时间,也很难保证最优。GC-Net[30]针对这两点进行了改进。首先,在左右图像上进行多层卷积和下采样操作,以更好的提取语义特征。对于每一个视差级别(以像素为单位),将左右特征图进行对齐(像素偏移)后再进行拼接,就得到了该视差级别的特征图。所有视差级别的特征图合并在一起,就得到了4D的Cost Volumn(高度,宽度,视差,特征)。Cost Volumn只包含了来自单个图像的信息,图像之间并没有交互。因此,下一个步骤是采用3D卷积处理Cost Volumn,这样可以同时提取左右图像之间的相关信息以及不同视差级别之间的信息。这一步的输出是3D的Cost Volumn(高度,宽度,视差)。最后,我们需要在视差这个维度上求Argmin,以得到最优的视差值,但是标准的Argmin是无法求导的。GC-Net中采用Soft Argmin,解决的求导的问题,从而使整个网络可以进行端对端的训练。GC-NetPSMNet[31]与GC-Net的结构非常相似,但是在两个方面进行了改进:1)采用金字塔结构和空洞卷积来提取多分辨率的信息并且扩大感受野。得益于全局和局部特征的融合,Cost Volumn的估计也更加准确。2)采用多个叠加的Hour-Glass结构来增强3D卷积。全局信息的利用被更进一步强化了。总的来说,PSMNet在全局信息的利用上做了改进,从而使视差的估计更多依赖于不同尺度的上下文信息而不是像素级别的局部信息。PSMNetCost Volumn中的,视差级别是离散的(以像素为单位),神经网络所学习的是在这些离散点上的Cost分布,而分布的极值点就对应了当前位置的视差值。但是视差(深度)值其实应该是连续的,用离散的点来估计会带来误差。CDN[32]中提出了连续估计的概念,除了离散点的分布以外,还估记了每个点处的偏移。离散点和偏移量一起,就构成了连续的视差估计。CDN参考文献[1] Kim et al., Deep Learning based Vehicle Position and Orientation Estimation via Inverse Perspective Mapping Image, IV 2019.[2] Roddick et al., Orthographic Feature Transform for Monocular 3D Object Detection, BMVC 2019.[3] Wang et al., Pseudo-LiDAR from Visual Depth Estimation: Bridging the Gap in 3D Object Detection for Autonomous Driving, CVPR 2019.[4] You et al., Pseudo-LiDAR++: Accurate Depth for 3D Object Detection in Autonomous Driving, ICLR 2020.[5] Weng and Kitani, Monocular 3D Object Detection with Pseudo-LiDAR Point Cloud, ICCV 2019.[6] Vianney et al., RefinedMPL: Refined Monocular PseudoLiDAR for 3D Object Detection in Autonomous Driving, 2019.[7] Chabot et al., Deep MANTA: A Coarse-to-fine Many-Task Network For Joint 2D and 3D Vehicle Analysis From Monocular Image, CVPR 2017.[8] Kundu et al., 3D-RCNN: Instance-level 3D Object Reconstruction via Render-and-Compare, CVPR 2018.[9] Qin et al., MonoGRNet: A Geometric Reasoning Network for Monocular 3D Object Localization, AAAI 2019.[10] Barabanau et al., Monocular 3D Object Detection via Geometric Reasoning on Keypoints, 2019.[11] Bertoni et al., MonoLoco: Monocular 3D Pedestrian Localization and Uncertainty Estimation, ICCV 2019.[12] Mousavian et al., 3D Bounding Box Estimation Using Deep Learning and Geometry, CVPR 2016.[13] Naiden et al., Shift R-CNN: Deep Monocular 3D Object Detection with Closed-Form Geometric Constraints, ICIP 2019.[14] Choi et al., Multi-View Reprojection Architecture for Orientation Estimation, ICCV 2019.[15] Chen et al., Monocular 3D Object Detection for Autonomous Driving, CVPR 2016.[16] Brazil and Liu, M3D-RPN: Monocular 3D Region Proposal Network for Object Detection, ICCV 2019.[17] Qin et al., Triangulation Learning Network: from Monocular to Stereo 3D Object Detection, CVPR 2019.[18] Jörgensen et al., Monocular 3D Object Detection and Box Fitting Trained End-to-End Using Intersection-over-Union Loss, 2019.[19] Wang et al., FCOS3D: Fully Convolutional One-Stage Monocular 3D Object Detection, 2021.[20] Liu et al., SMOKE: Single-Stage Monocular 3D Object Detection via Keypoint Estimation, CVPRW 2020.[21] Eigen, et al.,Depth Map Prediction from a Single Image using a Multi-Scale Deep Network, NIPS 2014.[22] Xu et al., Monocular Depth Estimation using Multi-Scale Continuous CRFs as Sequential Deep Networks, TPAMI 2018.[23] Fu et al., Deep Ordinal Regression Network for Monocular Depth Estimation, CVPR 2018.[24] Ranftl et al., Vision Transformers for Dense Prediction, ICCV 2021.[25] Chen et al., 3D Object Proposals using Stereo Imagery for Accurate Object Class Detection, TPAMI 2017.[26] Chen et al., DSGN: Deep Stereo Geometry Network for 3D Object Detection, CVPR 2020.[27] Li et al., Stereo R-CNN based 3D Object Detection for Autonomous Driving, CVPR 2019.[28] Aon et al., Object-Centric Stereo Matching for 3D Object Detection, CVPR 2020.[29] Zbontar and LeCun. Stereo matching by training a convolutional neural network to compare image patches, JMLR 2016.[30] Kendall, et al., End-to-end learning of geometry and context for deep stereo regression, ICCV 2017.[31] Chang and Chen et al., Pyramid Stereo Matching Network, 2018.[32] Garg et al., Wasserstein Distances for Stereo Disparity Estimation, NeurIPS, 2020.转载自知乎、汽车电子与软件,文中观点仅供分享交流,不代表本公众号立场,如涉及版权等问题,请您告知,我们将及时处理。


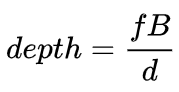
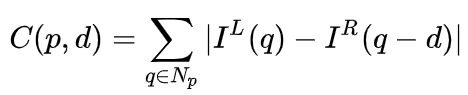

 下载APP
下载APP