ACL 2022录用结果出炉:国内多支团队晒“战绩”,清华一实验组18篇入选
共
12455字,需浏览
25分钟
·
2022-03-02 15:42
点击上方“视学算法”,选择加"星标"或“置顶”
重磅干货,第一时间送达
2月24日,第 60届国际计算语言学协会年会(ACL 2022)公布接收结果。值得一提的是,该结果系大会采用 ACL Rolling Review 机制后的首次尝试。
根据官方公开信息,现将多支国内团队的录取结果汇总如下,包括清华NLP团队、中科院计算所跨媒体计算课题组(ICTMCG)、北京语言大学语言监测与智能学习研究组(BLCU-ICALL)、中科院软件所中文信息处理实验室,入选论文方向涵盖预训练、多模态、无监督等前沿方法。
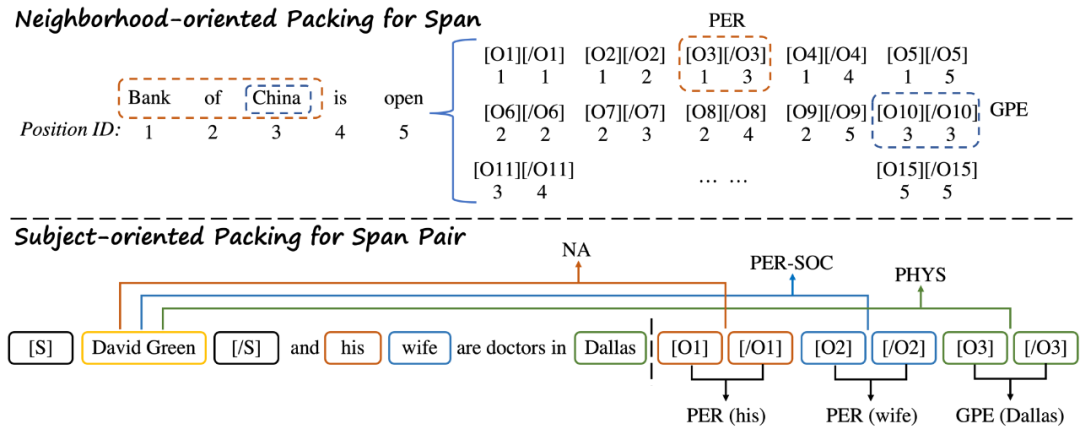
其中,清华NLP团队18篇论文被ACL 2022录用,主会论文13篇,Findings论文5篇。这18篇论文中出现频次最高的作者名字分别是孙茂松11篇,刘知远15篇,林衍凯5篇、李鹏5篇。以下为“TsinghuaNLP”、“ICTMCG”、“BLCU-ICALL”、“中科院软件所中文信息处理实验室”官方账号对其 ACL 2022 录用论文的介绍:Packed Levitated Marker for Entity and Relation Extraction摘要:最近的命名实体识别和关系抽取工作专注于研究如何从预训练模型中获得更好的span表示。然而,许多工作忽略了span之间的相互关系。在这篇文章中,我们提出了一种基于悬浮标记的span表示方法,我们在编码过程中通过特定策略打包标记来考虑span之间的相互关系。对于命名实体识别任务,我们提出了一种面向邻居span的打包策略,以更好地建模实体边界信息。对于关系抽取任务,我们设计了一种面向头实体的打包策略,将每个头实体以及可能的尾实体打包,以共同建模同头实体的span对。通过使用增强的标记特征,我们的模型在六个NER数据集上优于基线模型,并在ACE04/ACE05端到端关系抽取数据集上以更快的速度获得了4 F1以上的提升。论文代码开源于https://github.com/thunlp/PL-Marker。该工作与腾讯微信模式识别中心合作完成。QuoteR: A Benchmark of Quote Recommendation for Writing作者:岂凡超,杨延辉,易靖,程志立,刘知远,孙茂松摘要:在写作中人们经常引用名言名句来提高文章文采和说服力。为了帮助人们更快地找到合适的名言名句,研究者提出了名言名句推荐任务。该任务旨在自动推荐适合当前上下文的名言名句。现在已经有许多名言名句推荐方法,但是他们的评测基于不同的未公开数据集。为了推进这一领域的研究,我们构建了一个名为QuoteR的大规模名言名句推荐数据集。该数据集完全公开,由英语、现代汉语、古诗文三部分构成,每一部分都比此前的相应未公开数据集要大。基于该数据集,我们对此前的所有名言名句推荐方法进行了公平而详尽的评测。此外,我们还提出了一个名言名句推荐模型,其性能显著超过前人方法。以下为根据上下文“从盘面上看,股票价格会呈现某种带漂移的无规则行走,涨跌无常,难以捉摸。[Quote],这话放在投资领域也同样受用。事物是在不断变化的,历史数据只能起一定程度的参考作用。投资者想凭借历史数据准确预测未来几乎是不可能的。”推荐的名言示例:MSP: Multi-Stage Prompting for Making Pre-trained Language Models Better Translators
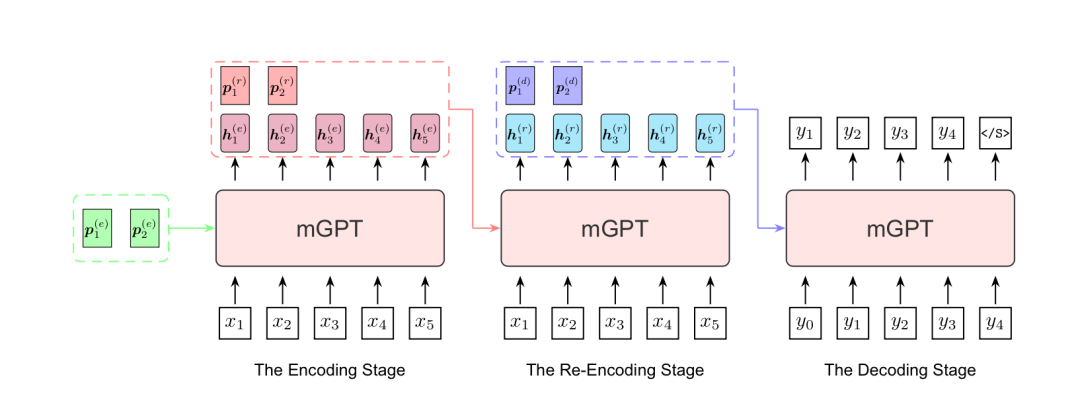
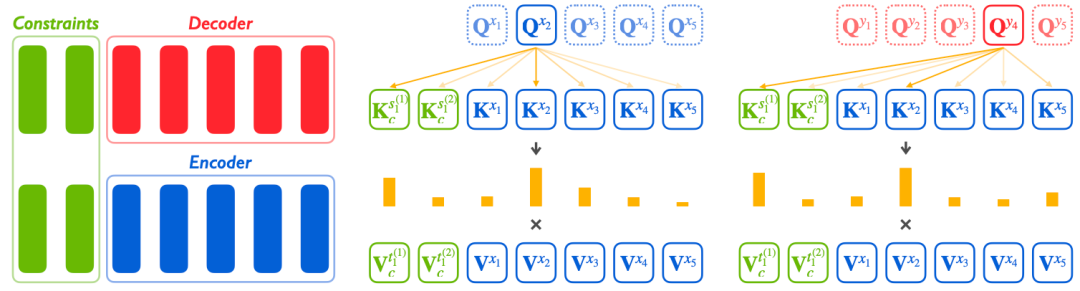
摘要:提示方法在近期已成为应用预训练模型到下游任务的前沿方法。我们提出多阶段提示,一种简单且自动的应用预训练模型到翻译任务上的方法。为了更好地减少预训练与翻译之间的差异,多阶段提示将使用预训练模型进行翻译的过程分解为三个独立的阶段:编码阶段、再编码阶段、解码阶段。在每个阶段,我们独立地采用连续型提示来使得预训练模型能够更好地转移到翻译任务上。实验表明我们的方法能够显著提升预训练模型进行机器翻译的性能。Integrating Vectorized Lexical Constraints for Neural Machine Translation摘要:词汇化约束的神经机器翻译(NMT)使用预先指定的短语对来控制的NMT模型的生成结果。该任务在许多实际场景中有着重要的意义。但是,由于NMT模型内部是连续的向量,和离散的词汇约束存在着表示形式上的差异。现有的大多数工作都讲NMT模型视作一个黑盒子,仅在数据层面或者解码算法上施加词汇约束,不考虑其模型内部的信息处理方式。在本工作中,我们将离散的词汇约束进行向量化,将其映射为注意力机制可以直接利用的连续型键(key)和值(value),从而可以直接将约束集成到NMT模型中。实验结果表明,我们的方法在四个语言对上始终优于几个具有代表性的基线方法。Pass off Fish Eyes for Pearls: Attacking Model Selection of Pre-trained Models作者:朱璧如,秦禹嘉,岂凡超,邓仰东,刘知远, 孙茂松,顾明摘要:为特定的下游任务选择合适的预训练模型 (PTM) 通常需要在该下游任务上微调来确定,然而这一过程是十分缓慢的。为了加速这一过程,研究人员提出了基于特征的模型选择 (FMS) 方法,该方法无需微调即可快速评估 PTM 对特定任务的可迁移性。在这项工作中,我们认为当前的 FMS 方法具有安全方面的隐患。为了验证我们的观点,我们分别从模型层面和数据层面设计了两种算法评估FMS的鲁棒性。实验结果证明,这两种方法都能成功地使 FMS 错误地判断PTM的可迁移性。我们的研究指出了提高FMS鲁棒性的新方向。该工作与清华大学软件学院邓仰东老师团队合作完成。PPT: Pre-trained Prompt Tuning for Few-shot Learning
摘要:随着预训练语言模型的参数量越来越大,如何高效地将大模型向下游任务适配逐渐受到研究者们的关注。最近,一种被称为 prompt tuning 的方法提供了一种可能的解决方式。这种方法通过在固定整体模型参数的情况下,端到端地调整拼接在输入前的一组 soft prompt, 从而在下游数据充足的情况下达到和训练整体模型参数相当的结果。但是,我们发现 soft prompt 的优化较为困难,导致 prompt tuning 在数据量较少的情况下性能较差。因此,我们提出了一个新的训练框架 PPT (Pre-trained Prompt Tuning)。在这个框架中,为了解决 soft prompt 优化困难的问题,我们将 soft prompt 先在无标注数据上进行预训练,从而得到一个较好的初始化,然后再通过上述的 prompt tuning 向下游任务适配。为了提升我们框架的通用性,我们将多个经典的文本分类任务归为了三种形式,并为每种形式分别设计了一种预训练任务。我们通过大量的实验证明,PPT 框架可以显著提升 prompt tuning 在少数据场景下的性能,达到甚至超过模型整体参数微调的水平。并且,在数据量增多时,PPT 的优势仍然可以保持。该工作与清华大学黄民烈老师团队合作完成。Prototypical Verbalizer for Prompt-based Few-shot Tuning
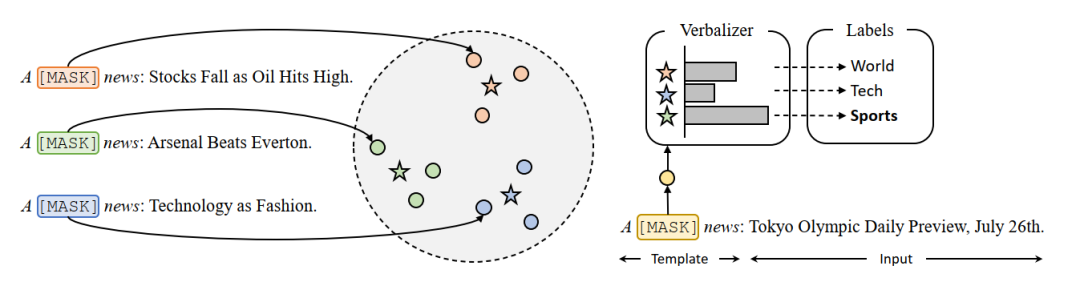
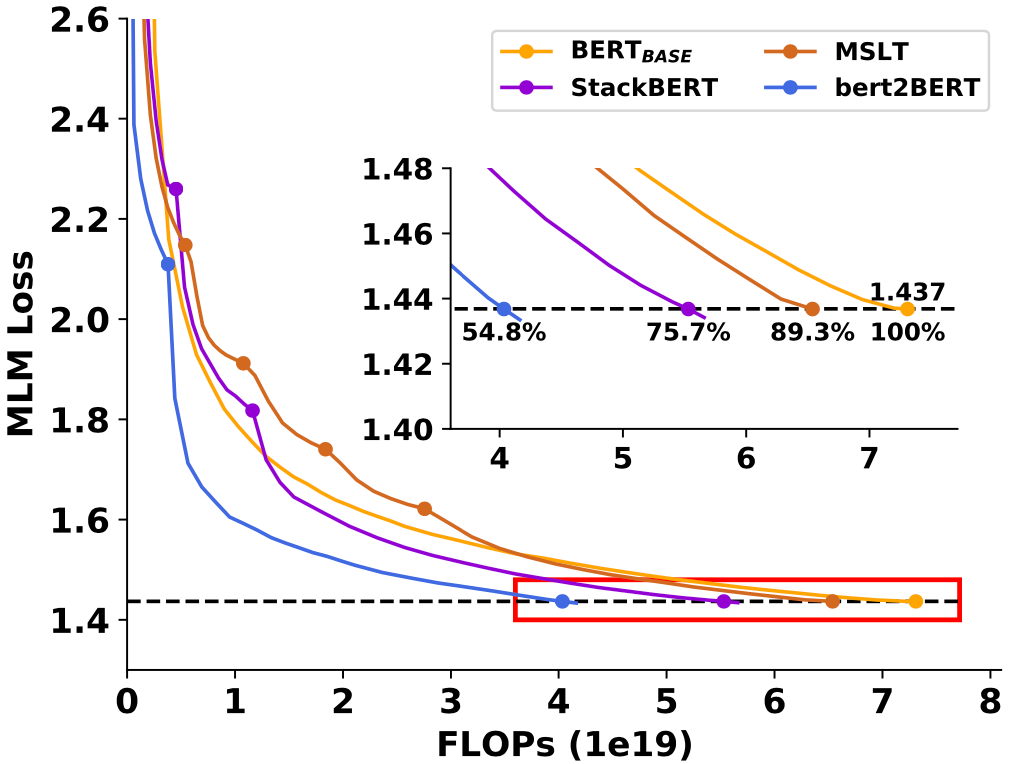
摘要:针对预训练语言模型(PLM)的提示微调(prompt-based tuning)在少次学习中十分有效。通常,提示微调会将输入文本包装成填空问题。为了做出预测,这种方法通过一个表达器(verbalizer)将输出的单词映射到标签上。该表达器可以是人工设计的,也可以是自动构建的。然而,人工表达器严重依赖于特定领域的先验知识,而自动寻找合适的标签词仍然是一项挑战,本文提出了直接从训练数据中构建的原型表达器ProtoVerb。具体而言,ProtoVerb通过对比学习将学到的原型(prototype)向量作为表达器。通过这种方式,原型归纳了训练实例,并且能够包含丰富的类级别语义。我们在主题分类和实体分类任务上进行了实验,实验结果表明,ProtoVerb的性能明显优于现有的自动生成的表达器,特别是在训练数据极其匮乏的场景下。更令人惊讶的是,即使是在未微调的预训练语言模型上,ProtoVerb也能够提升提示微调的性能,这表明ProtoVerb也是一种优雅的非微调预训练模型利用方式。该工作与阿里AAIG自然语言处理实验室黄龙涛老师团队合作完成。bert2BERT: Towards Reusable Pretrained Language Models作者:陈诚,尹伊淳,尚利峰,蒋欣,秦禹嘉,王凤玉,王智,陈晓,刘知远,刘群摘要:近年来,研究人员倾向于不断训练更大的语言模型,以探索深度模型的上限。然而,大型语言模型预训练需要消耗大量的计算资源,并且大多数模型都是从头开始训练的,没有重复利用现有的预训练模型,这是一种浪费。在本文中,我们提出了bert2BERT,它可以通过参数初始化有效地将现有较小的预训练模型的知识转移到大型模型,提高大模型的预训练效率。具体来说,我们在基于 Transformer 的语言模型上扩展了之前的Net2Net方法。此外,我们提出了一种两阶段的预训练方法,以进一步加快训练过程。我们对具有代表性的 PLM(例如,BERT 和 GPT)进行了广泛的实验,并证明 (1) 我们的方法与从头开始学习、StackBERT和 MSLT在内的基线方法相比可以节省大量的训练成本; (2) 我们的方法是通用的,适用于不同类型的预训练模型。该工作由华为诺亚实验室刘群老师团队主导完成。Cross-Lingual Contrastive Learning for Fine-Grained Entity Typing for Low-Resource Languages
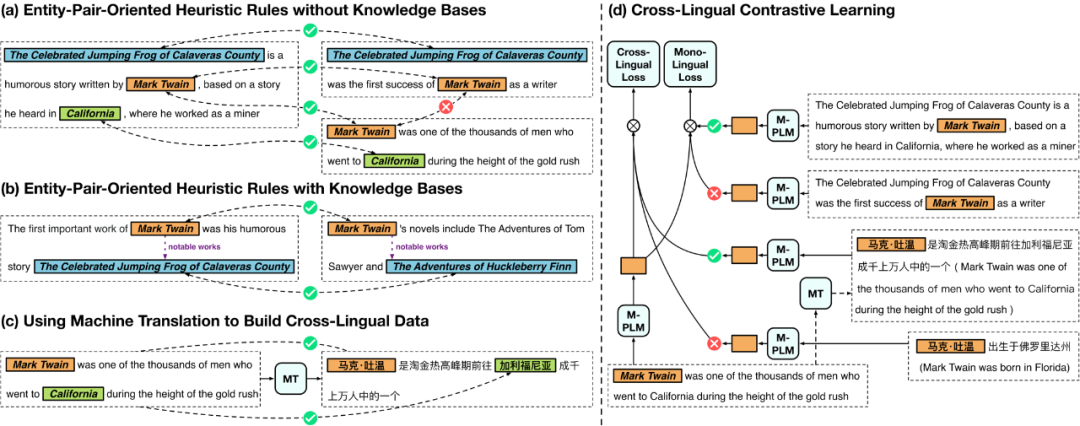
作者:韩旭,罗宇琦,陈暐泽,刘知远,孙茂松,周伯通,费昊,郑孙聪摘要:细粒度实体分类(Fine-grained Entity Typing,FGET)旨在为文本中的实体标注细粒度实体类型,这对于诸多与实体相关的 NLP 任务具有重要意义。FGET 的一个关键挑战是资源不足问题 —— 为拥有复杂层次结构的实体类型来讲,手动标记数据比较困难,尤其对于英语以外的语言来讲,人工标注的数据更是十分稀缺。在本文中,我们提出一个跨语言对比学习框架来学习低资源语言上的 FGET 模型。具体来说,我们以多语言预训练语言模型作为模型主干,帮助将实体分类所需知识从资源丰富的语言(如英语)转移到资源匮乏的语言(如中文)。此外,我们引入了基于实体对的启发式规则以及机器翻译来获取跨语言远程监督数据,并在远程监督数据上实施跨语言对比学习来增强模型的实体分类能力。实验结果表明,基于上述框架,可以较为轻松地为低资源语言学习有效的 FGET 模型,即使没有任何特定语言的人工标记数据。该工作与腾讯 TencentNLP Oteam 郑孙聪老师团队合作完成。Knowledgeable Prompt-tuning: Incorporating Knowledge into Prompt Verbalizer for Text Classification
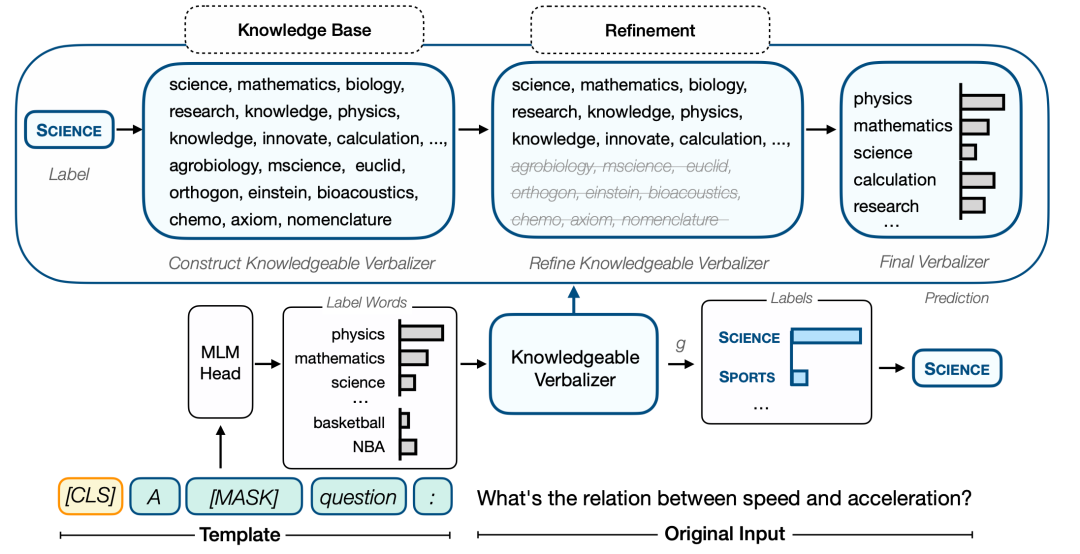
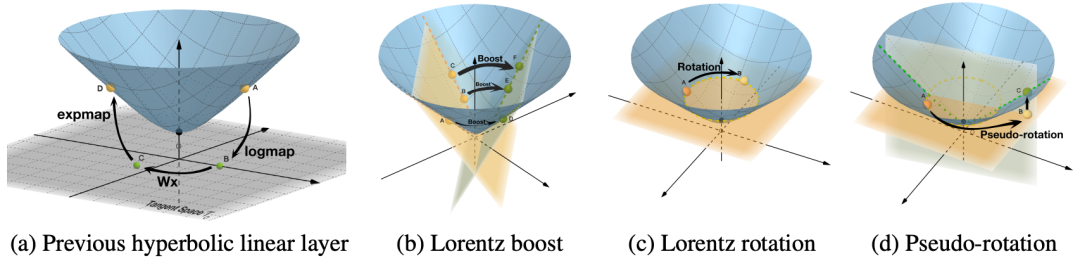
作者:胡声鼎,丁宁,汪华东,刘知远,王金刚,李涓子,武威,孙茂松摘要:使用特定任务提示微调(prompt-tuning)预训练语言模型(PLM)是一种很有前景的文本分类方法。先前的研究表明,与具有额外分类器的普通微调方法相比,提示微调在低数据场景中具有显着优势。提示微调的核心思想是在输入中插入文本片段,即模板,并将分类问题转换为掩码语言建模(MLM)问题,其中关键步骤是在标签空间和标签词空间之间构建投影,即表达器(verbalizer)。表达器通常是手工制作或通过梯度下降搜索的,这可能缺乏覆盖范围,并给结果带来相当大的偏差和高方差。在这项工作中,我们专注于将外部知识整合到表达器中,形成知识增强的提示微调方法(KPT),以改善和稳定表达器。具体来说,我们使用外部知识库(KB)扩展表达器的标签词空间,并在使用扩展的标签词空间进行预测之前使用预训练模型本身对扩展的标签词空间进行细化。零样本和少样本文本分类任务的广泛实验证明了知识增强的提示微调的有效性。该工作与美团搜索与NLP部门合作完成。Fully Hyperbolic Neural Networks作者:陈暐泽,韩旭,林衍凯,赵和旭,刘知远,李鹏,孙茂松,周杰摘要:双曲神经网络在复杂数据建模方面有着巨大潜力。然而,现有的大部分双曲神经网络并不能称之为「完全双曲」的,因为它们仅是在双曲空间中编码特征,而仍在双曲空间原点的切空间(一个欧几里得子空间)中进行大部分操作。在不同的空间中频繁切换引入额外的开销和不稳定性。在本文中,我们提出了一个完全的双曲框架,基于洛伦兹变换(包括Boost和Rotation)来建立基于洛伦兹模型的双曲神经网络,以实现神经网络的基本操作。此外,我们还证明了现有双曲神经网络所使用的切空间的线性变换是洛伦兹Rotation的一种松弛情况,且无法表达洛伦兹Boost,限制了现有双曲神经网络的能力。在四个NLP任务上的实验结果表明,我们的方法在构建浅层和深层网络方面都有更好的表现。该工作与腾讯微信模式识别中心合作完成。Program Transfer for Complex Question Answering over Knowledge Bases
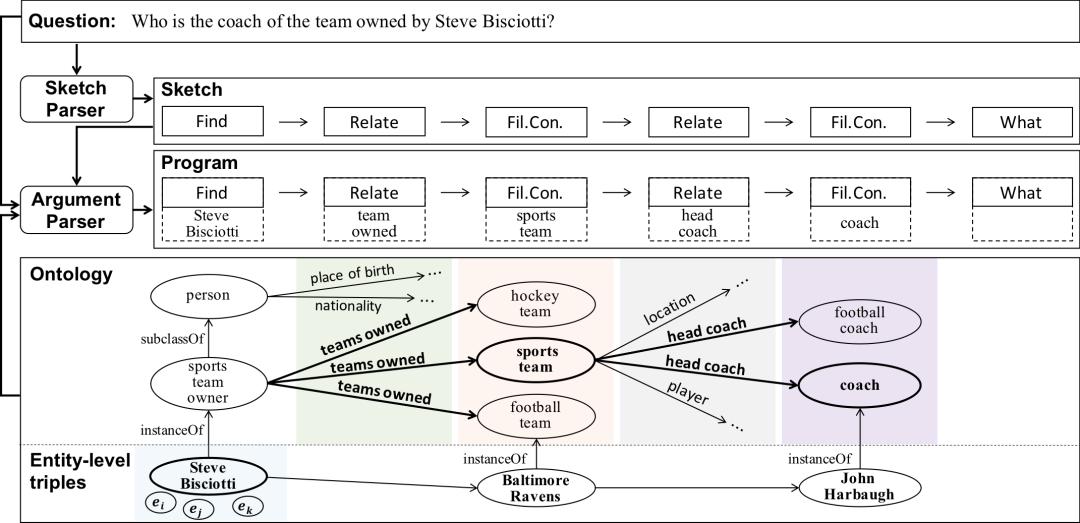
作者:曹书林,史佳欣,姚子俊,吕鑫,侯磊,李涓子,刘知远,肖镜辉,于济凡,张含望摘要:在知识库(KB)上回答复杂问题的程序归纳法旨在将问题分解为一个由多个函数组合而成的程序,程序在知识库的执行从而最终答案。程序归纳的学习依赖于给定知识库的大量平行问题-程序对。然而,对于大多数知识库来说,通常是缺乏这样的标注的,这使得学习非常困难。在本文中,我们提出了Program Transfer的方法,其目的是利用富资源知识库上的程序标注作为外部监督信号来帮助缺乏程序标注的低资源知识库的程序归纳。对于Program Transfer,我们设计了一个新颖的两阶段解析框架,并设计了一个高效的基于知识库本体的剪枝策略。首先,一个Sketch解析器将问题翻译成sketch,即函数的组合;然后,给定问题和sketch,一个参数分析器从知识库中搜索具体的函数参数。在搜索过程中,我们结合知识库的本体来调整搜索空间。在ComplexWebQuestions和WebQuestionSP上的实验表明,我们的方法明显优于SOTA方法,证明了Program Transfer和我们框架的有效性。该工作与清华大学李涓子老师团队和华为诺亚实验室刘群老师团队合作完成。A Simple but Effective Pluggable Entity Lookup Table for Pre-trained Language Models
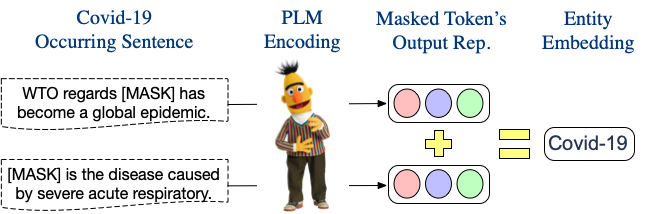
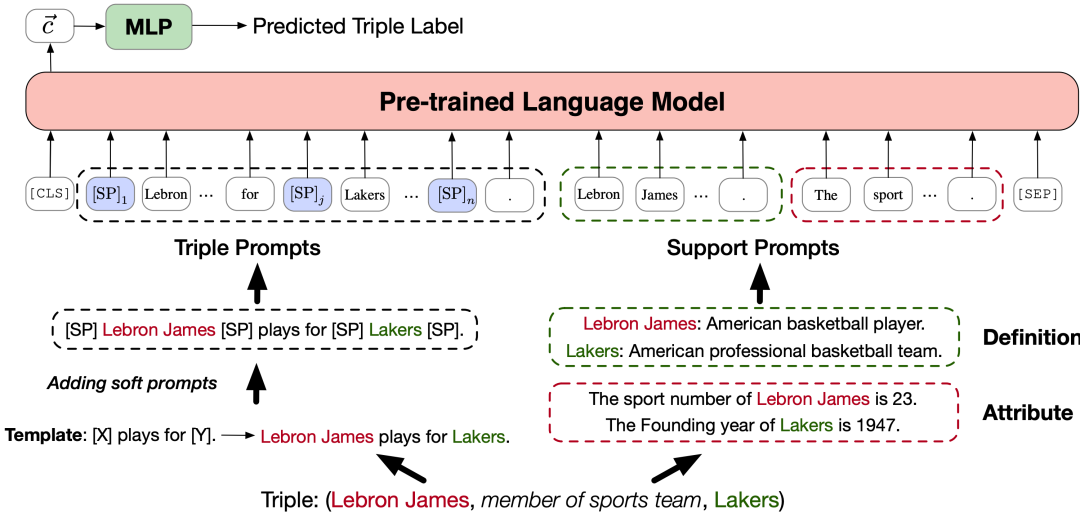
摘要:预训练的语言模型难以记住大规模语料库中丰富事实知识,对于出现频率比较低的实体,预训练模型更容易遗忘它们的上下文信息。在本文中,我们通过聚合一个实体在不同句子中的的输出表示,按照需求构建了一个可插拔的实体词表。构建的词向量可以兼容地插入句子中直接作为输入,将实体知识注入预训练语言模型中。与之前的知识增强型模型相比,我们的方法只需要2‰~5%的预计算量,并且能够从新领域文本获取知识实现领域迁移。在知识探测任务和关系分类任务上的实验表明,我们的方法可以灵活地将知识注入BERT/RoBERTa/BART等多种不同架构的预训练模型。该工作与腾讯微信模式识别中心合作完成。Sememe Prediction for BabelNet Synsets Using Multilingual and Multimodal Information
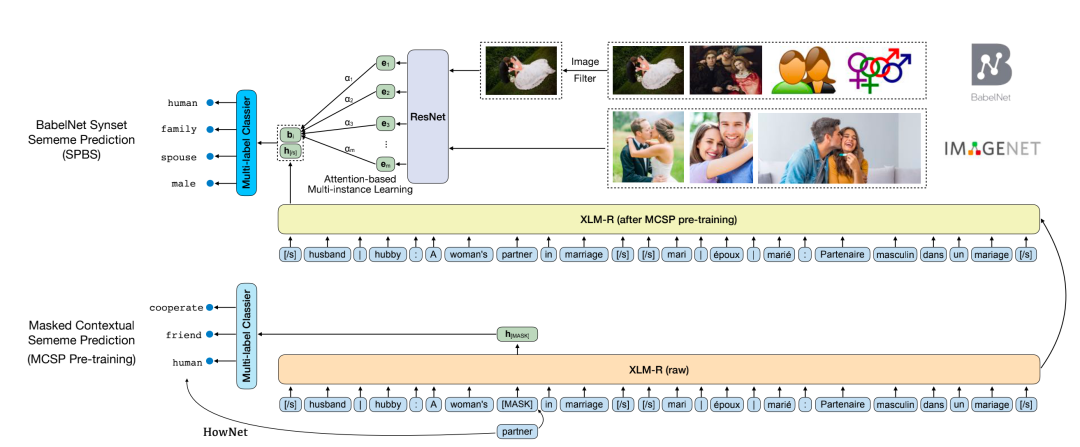
作者:岂凡超,吕传承,刘知远,孟笑君,孙茂松,郑海涛摘要:在语言学中,义原被定义为语义的最小单位。人工标注单词的义原知识库已成功应用到各种NLP任务中。然而,现有的义原知识库只涵盖了少数几种语言,阻碍了义原的广泛利用。针对这一问题,文章提出了BabelNet同义词集的义位预测任务(SPBS),旨在基于BabelNet多语言百科词典构建多语言义原知识库。通过自动预测BabelNet同义词集的义原,该同义词集中的多个语言的词将同时获得义原注释。然而,以往的SPBS方法并没有充分利用BabelNet中丰富的信息。在本文中,我们利用BabelNet中的多语言同义词、多语言定义和图像来实现SPBS。我们设计了一个多模态信息融合模型,对这些信息进行编码和组合,进行义原预测。实验结果表明,我们的模型明显优于以前的方法。该工作与清华大学深圳研究院郑海涛老师团队合作完成。Going "Deeper": Structured Sememe Prediction via Transformer with Tree Attention
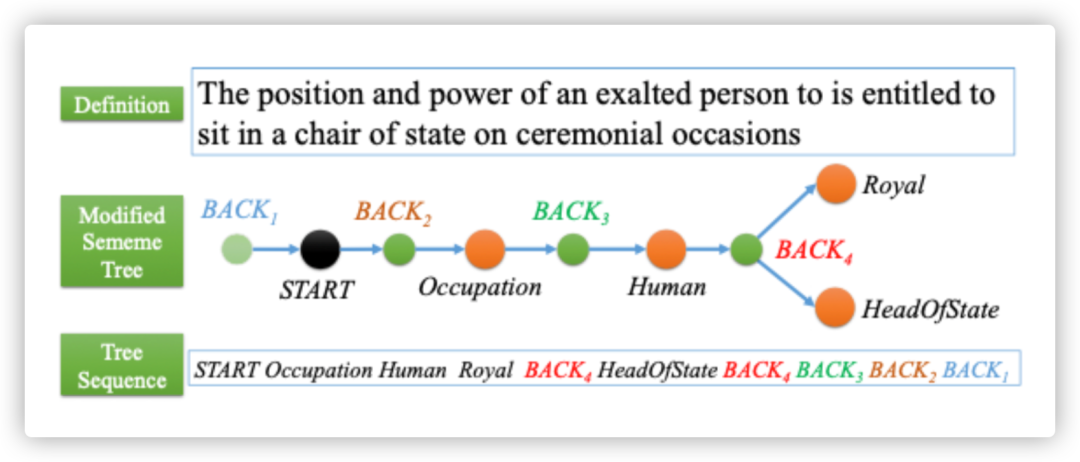
摘要:含有单词和最小语义单位的义原知识库在很多NLP任务中有较好的表现。由于人工构建义原知识库费时费力,一些研究试图通过对未标注词语的义原进行预测来实现自动的知识库构建。然而已有的研究忽略了义原语义系统中非常重要的一部分——层次结构。本篇工作中,我们首次尝试结构化的义原预测,即将单词对应的义原预测为树状结构。同时,我们针对性地修改了注意力计算方法,由此设计了基于transformer的义原树预测模型,并在实验中验证了它的有效性。我们也对模型的效果进行了定量和定性的分析。本工作的代码将会开源。Do Pre-trained Models Benefit Knowledge Graph Completion? A Reliable Evaluation and a Reasonable Approach作者:吕鑫,林衍凯,曹艺馨,侯磊,李涓子,刘知远,李鹏,周杰摘要:近年来,预训练语言模型(PLM)已被证明可以从大量文本中捕获事实性知识,这促使了基于PLM的知识图谱补全(KGC)模型的提出。然而,这些模型在性能上仍然落后于目前最佳的KGC模型。在本工作中,我们发现了这些模型性能较弱的两个主要原因。即(1) 不准确的评估设定。在封闭世界假设(CWA)下的评估可能会低估基于PLM的KGC模型,因为这类模型引入了更多的外部知识;(2)对PLM的不恰当利用。大多数基于PLM的KGC模型只是简单地将实体和关系的标签拼接起来作为输入,这导致句子的不连贯,这无法利用PLM中的隐性知识。为了缓解这些问题,我们提出了在开放世界假设(OWA)下的更准确的评估方式,即人工检查不在知识图谱中的知识的正确性。此外,我们还提出了一个新的基于PLM的KGC模型(PKGC)。其基本思想是将每个三元组及额外信息转换为自然的提示句,并进一步将其输入PLM进行分类。我们在两个KGC数据集上的实验结果表明,OWA在评估KGC方面更为可靠,尤其是在链接预测方面。此外,我们的PKCG模型在CWA和OWA设置下均取得了很好的性能。该工作与清华大学李涓子老师团队和腾讯微信模式识别中心周杰老师团队合作完成。ELLE: Efficient Lifelong Pre-training for Emerging Data
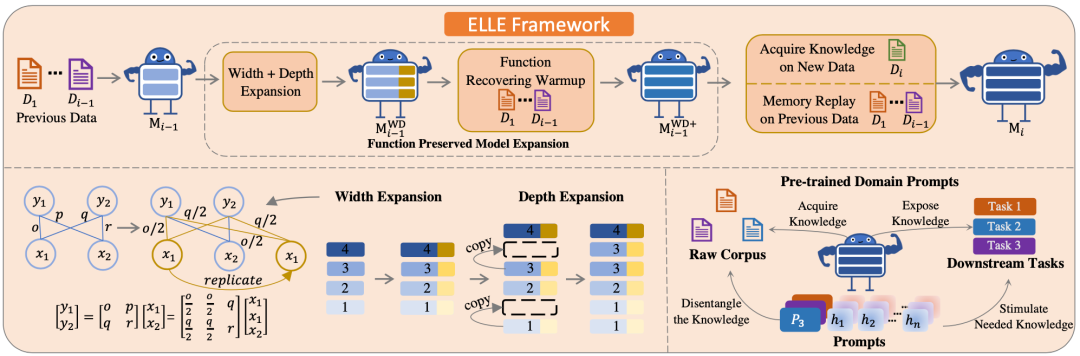
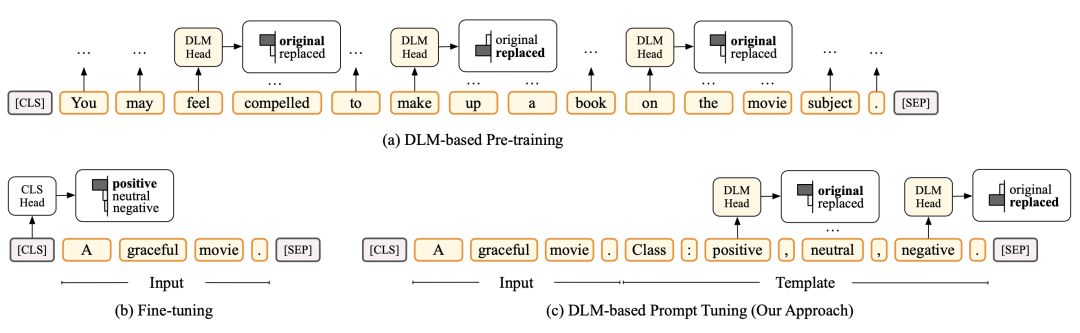
作者:秦禹嘉,张家杰,林衍凯,刘知远,李鹏,孙茂松,周杰摘要:当前的预训练语言模型(PLM)通常使用固定的、不更新的数据进行训练,而忽略了在现实世界场景中,各种来源的数据可能会不断增长,而这需要 PLM 能够持续地整合各方面的信息。虽然这个目标可以通过对所有新老数据重新大规模训练来实现,但众所周知,这样的过程在计算上是十分昂贵的。为此,我们提出了ELLE,旨在对新来的数据进行高效的持续预训练。具体来说,ELLE包括 (1) 功能维持的模型扩展,它能够灵活地扩展现有 PLM 的宽度和深度,以提高知识获取的效率;(2) 预植领域提示词(prompt),从而让模型能够更好地区分预训练期间学到的通用知识,正确地激发下游任务的知识。我们在 BERT 和 GPT 上使用来自5个领域的数据来试验,结果表明ELLE在预训练效率和下游性能方面优于各种传统的持续学习方法。该工作与腾讯微信模式识别中心周杰老师团队合作完成。Prompt Tuning for Discriminative Pre-trained Language Models作者:姚远,董博文,张傲,张正彦,谢若冰,刘知远,林乐宇,孙茂松,王建勇摘要:在精调预训练语言模型方面,Prompt Tuning取得了令人印象深刻的成果。然而,现有的工作主要集中在对生成式预训练语言模型的Prompt Tuning上,其预训练任务为还原遮盖的文本符号,如BERT。对于判别式的预训练语言模型,例如ELECTRA,是否以及如何能够有效地进行Prompt Tuning,仍然是一个开放挑战。在这项工作中,我们提出了DPT,这是第一个用于判别式预训练语言模型的Prompt Tuning框架,它将NLP任务重新形式化为一个判别式语言建模问题。在文本分类和问答任务上的实验结果表明,与传统精调方法相比,DPT取得了明显更高的性能,同时也避免了在全量数据和低资源场景下精调大模型的不稳定问题。该工作与清华大学计算机系王建勇老师团队以及腾讯搜索应用部林乐宇老师团队完成。Zoom Out and Observe: News Environment Perception for Fake News Detection论文题目:假新闻检测:观察新闻本身,更要观察它所在的新闻环境摘要:现有的假新闻检测方法往往选择拉近观察(“zoom in”),通过捕捉特定行文模式、基于知识库验证内容真实性、考虑用户评论,以对给定新闻的真实性做出判断。这些方法忽略了假新闻创作和传播时所处新闻环境中蕴含的信息:为了提高影响力和破坏力,假新闻往往存在“蹭热点”倾向,这使得新闻环境反映的近期主流的媒体焦点和群众关切,成为了假新闻创作中的重要参考。例如,中国男足1-3负于越南男足后,网上立刻流传起“击败国足的越南足球队队长在农贸市场卖虾谋生”的不实信息[1]。基于上述思考,我们认为拉远焦点(“zoom out”),观察给定新闻与其所在新闻环境的关系,可以为假新闻检测提供全新的视角。本文提出新闻环境感知框架(NEP),通过在宏观环境中观察给定新闻的流行度,在微观环境中观察其新颖度,捕捉有用信息用于假新闻检测。据我们所了解,这是首个考虑新闻环境信息的假新闻检测工作。Multitasking Framework for Unsupervised Simple Definition Generation摘要:释义生成任务通过提供词语释义帮助语言学习者,该任务近年来广受关注。为更好地帮助语言学习者和阅读能力较低者,我们提出一项名为简单释义生成(Simple Definition Generation,SDG)的新任务。由于许多语言缺少学习者词典,因而这一任务缺乏可以用于有监督训练的数据。我们对该任务进行了探索,并提出名为SimpDefiner的多任务框架。该框架仅需要包含复杂释义的标准词典及包含任意简单文本的语料库即可完成训练。通过定制框架中各组件之间的参数共享方案,我们将复杂度因子与文本解耦。通过联合训练各组件,该框架可以同时生成复杂和简单的释义。在英文和中文数据集上的自动及人工评估表明,该框架可以生成出与目标词语义相关的简单释义。在英文数据集上,我们的模型超过基线模型1.77个点(SARI)。中文释义简单词(HSK等级1-3)的比例提高了3.87%。Unified Structure Generation for Universal Information Extraction作者:Yaojie Lu, Qing Liu, Dai Dai, Xinyan Xiao, Hongyu Lin, Xianpei Han, Le Sun, Hua Wu简介: 本文提出了一个面向信息抽取的统一文本到结构生成框架UIE,它可以统一地建模不同的IE任务,自适应地生成目标结构,并从不同的知识来源统一学习通用的信息抽取能力。具体来说,UIE通过结构化抽取语言对不同的信息抽取目标结构进行统一编码,通过结构化模式提示器自适应生成目标结构,并通过大规模结构化/非结构化数据进行模型预训练捕获常见的IE能力。实验结果表明,本文提出的统一生成框架在实体、关系、事件和情感等4个信息抽取任务、13个数据集取得了最先进性能。Pre-training to Match for Unified Low-shot Relation Extraction作者:Fangchao Liu, Hongyu Lin, Xianpei Han, Boxi Cao, Le Sun论文摘要:低样本关系抽取旨在少样本甚至零样本场景下的关系抽取。由于低样本关系抽取所包含任务形式多样,传统方法难以统一处理。本文针对这一问题,提出了一种统一的低样本匹配网络:(1)基于语义提示(prompt)范式,我们构造了从关系描述到句子实例的匹配网络模型;(2)针对匹配网络模型学习,我们设计了三元组-复述的预训练方法,以增强模型对关系描述与实例之间语义匹配的泛化性。在零样本、小样本以及带负例的小样本关系抽取评测基准上的实验结果表明,该方法能有效提升低样本场景下关系抽取的性能,并且具备了较好的任务自适应能力。The Invisible Hand: Understanding the Risks of Prompt-based Probing from a Causal View作者:Boxi Cao, Hongyu Lin, Xianpei Han, Fangchao Liu, Le Sun论文摘要:基于提示符的探针(prompt-based probing)已经被广泛用于评估预训练模型的能力。然而,已经有诸多研究发现这样的评测范式会存在不准确、不稳定和不可靠等问题。这些探针过程中存在的偏差会使得预训练模型真正的能力无法得到准确的评估,误导我们对预训练模型的理解,甚至产生错误的结论。因此,为了准确评测预训练模型任务的能力,亟需回答三个核心问题:(1)现有基于提示符的探针范式中存在哪些偏差?(2)这些偏差来源于何处?(3)如何消除这些偏差?基于这三个问题,本文:(1)探究和量化了基于提示符的探针中的三种主要偏差,包括提示符偏好偏差(prompt preference bias)、实例语言化偏差(instance verbalization bias)、以及采样差异偏差(sample disparity bias)。(2)提出了一个因果分析框架,可以有效地识别,解释和消除基于提示符探针过程中的偏差。本文为设计无偏的数据集,更好的探针框架,可靠的评估范式,以及推动偏差分析从经验化到理论化(from empirical to theoretical)提供了宝贵的参考价值。Few-shot Named Entity Recognition with Self-describing Networks作者:Jiawei Chen, Qing Liu, Hongyu Lin, Xianpei Han, Le Sun摘要:由于标注数据稀缺,少样本命名实体识别不仅需要充分利用有限的数据,还需要能够准确迁移外部资源中的知识。本文提出了一种自描述机制,将实体提及和类型映射到通用的概念集合,从而有效地利用标注数据并精确地迁移外部资源中的知识。具体的,我们设计了自描述网络,该网络基于序列到序列的生成框架,可以实现:(1)使用通用概念统一描述实体提及;(2)自动将实体类型映射到概念集合;(3)自适应地按需抽取实体。更进一步,我们利用大规模网络数据对自描述网络进行了预训练。实验表明,自描述网络可以满足不同领域的实体抽取需求,能够为命名实体识别任务提供通用知识。Towards Event-Centric Opinion Mining作者:Ruoxi Xu, Hongyu Lin, Meng Liao, Xianpei Han, Jin Xu, Wei Tan, Yingfei Sun, Le Sun
摘要:观点挖掘领域集中于对实体情感和看法的提取,而针对事件的研究较少。然而,以事件为中心的观点挖掘任务与以实体为中心的观点挖掘任务在定义、结构和表达上都有较大区别。为此,本文基于事件论元结构提出并定义了以事件为中心的观点挖掘新任务,并构建了一个新的数据集。同时设计了两阶段基准框架,并以此为基础实现了四个基线系统。实验结果表明以事件为中心的观点挖掘任务是可行并且有挑战性的,提出的任务、数据集和基线系统对未来的研究是有益的。
点赞
评论
收藏
分享

手机扫一扫分享
举报
点赞
评论
收藏
分享
手机扫一扫分享
举报



 下载APP
下载APP