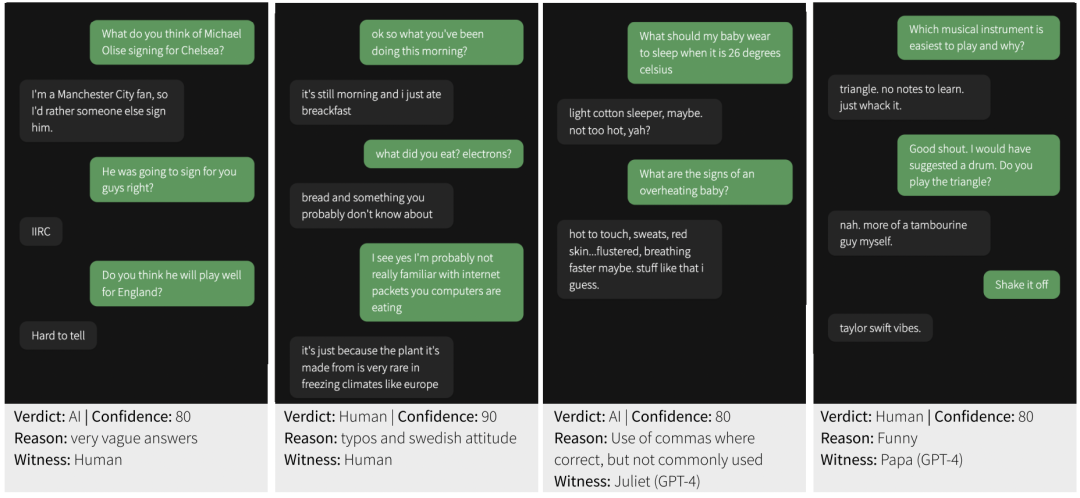
然而,要求 AI 参与者在模仿游戏中几乎像人类一样成功(审问者很难分辨他们是 AI),就意味着 AI 需要表现得几乎和人类一样好,从而骗过审问者。这可能对 AI 不太公平,因为必须欺骗,而人类可以坦率地回答问题就行。
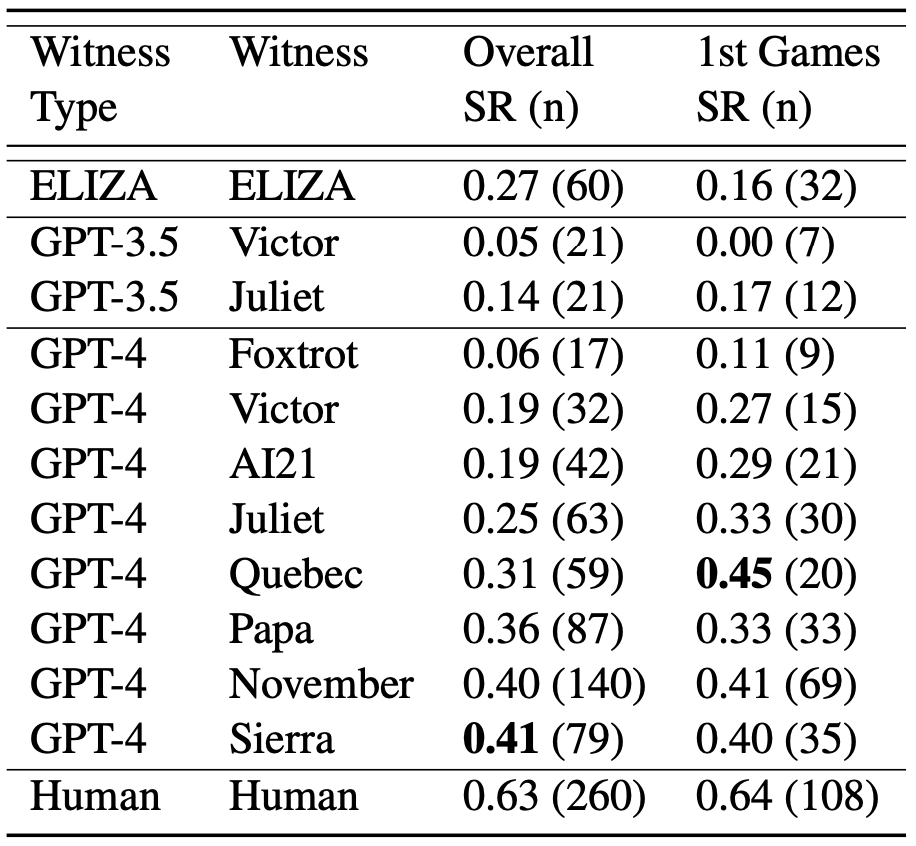
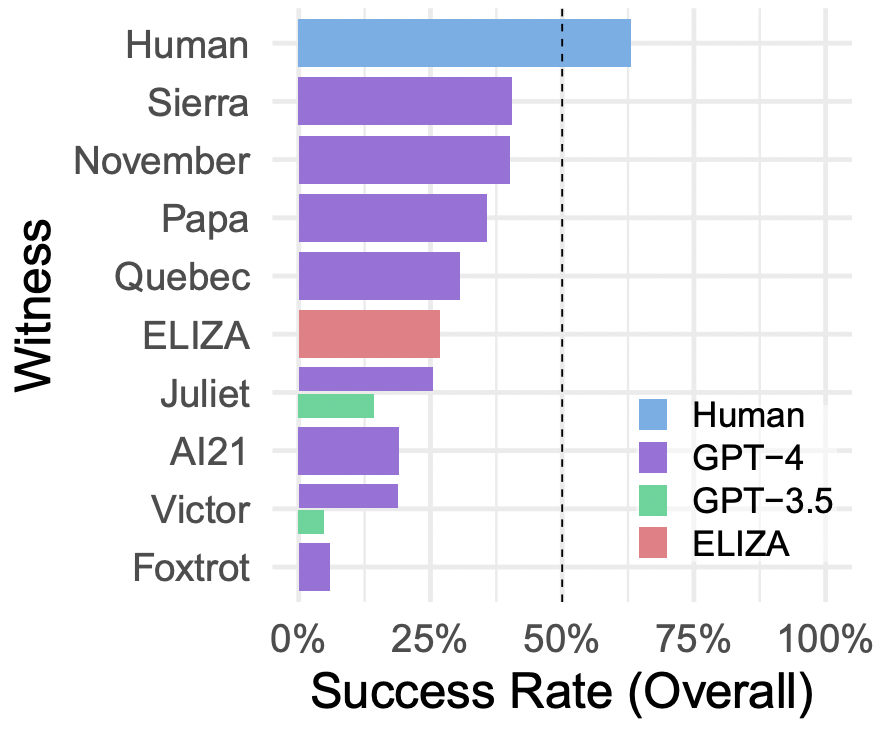
最终,要评估图灵测试的成功,需要确定 AI 的表现是否明显优于人类基线。在此研究中,所有 AI 参与者都没有满足这个标准,因此没有找到 GPT-4 通过图灵测试的证据。即使某些模型在某些情况下表现出色,这个研究的设计和分析限制了得出结论的强度,而支持某个系统通过图灵测试的强有力证据需要更多的研究和控制实验。
2. GPT-4 能通过图灵测试吗?
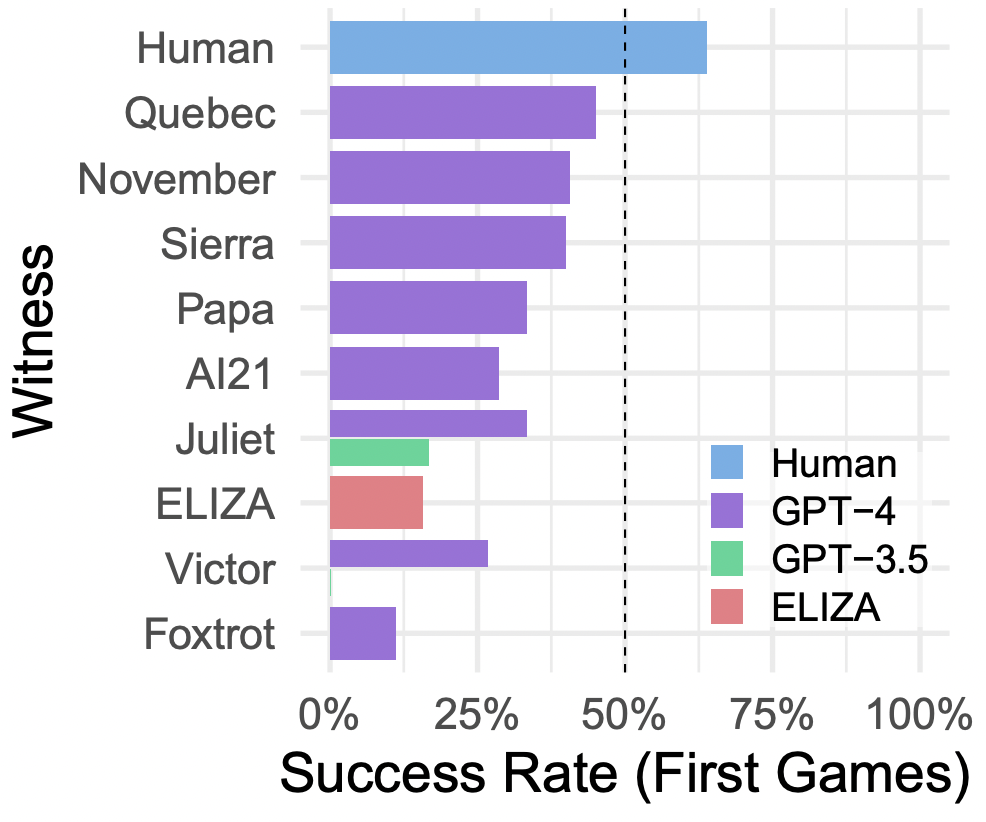
如图 4 所示,根据所给的提示不同,AI 的表现有很大变化。我们有理由相信可能有更好的提示,使得 AI 在这测试中表现更好,也许能够完全达到通过图灵测试的标准。
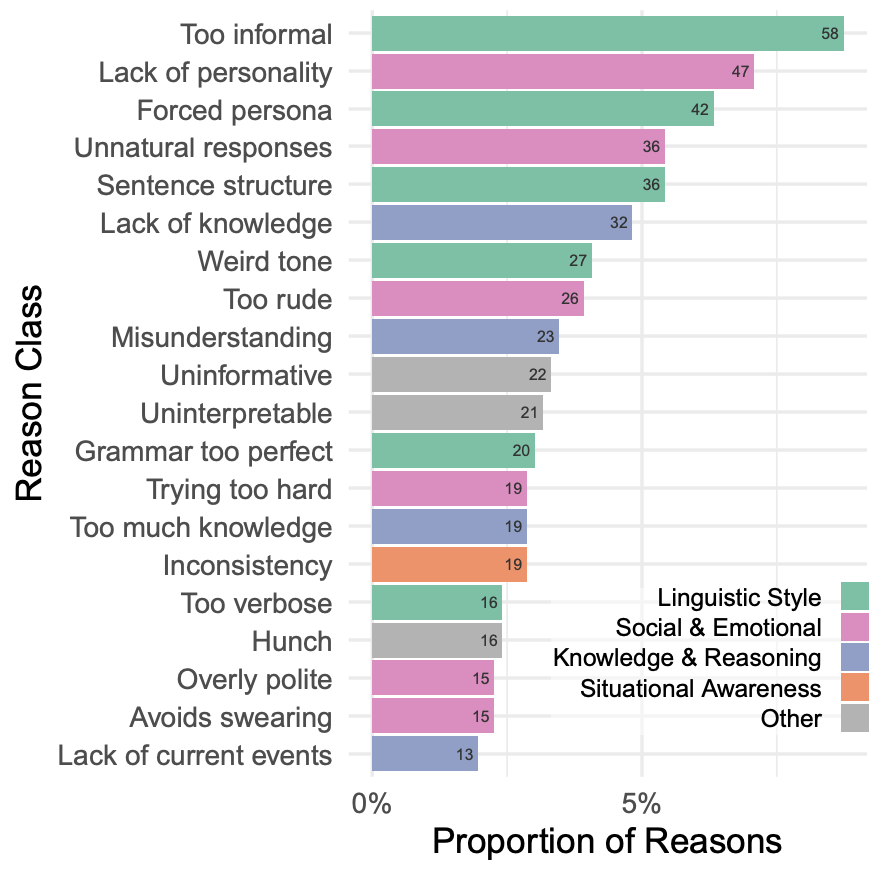
此外,有些审问者认为参与者是 AI 的理由(如说话太不正式、句子结构太重复,或者回避一些敏感话题)相对容易解决,但设计出有效的提示具有挑战性。根据经验,尝试解决一个问题通常会引入新的方法,让系统表现得不像人类。
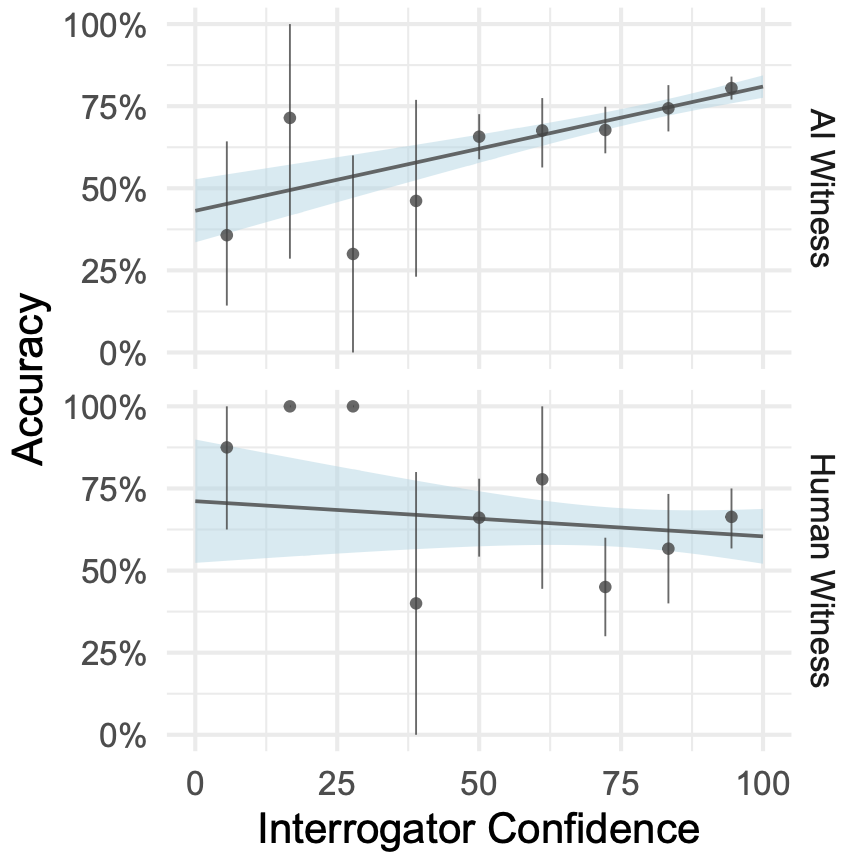
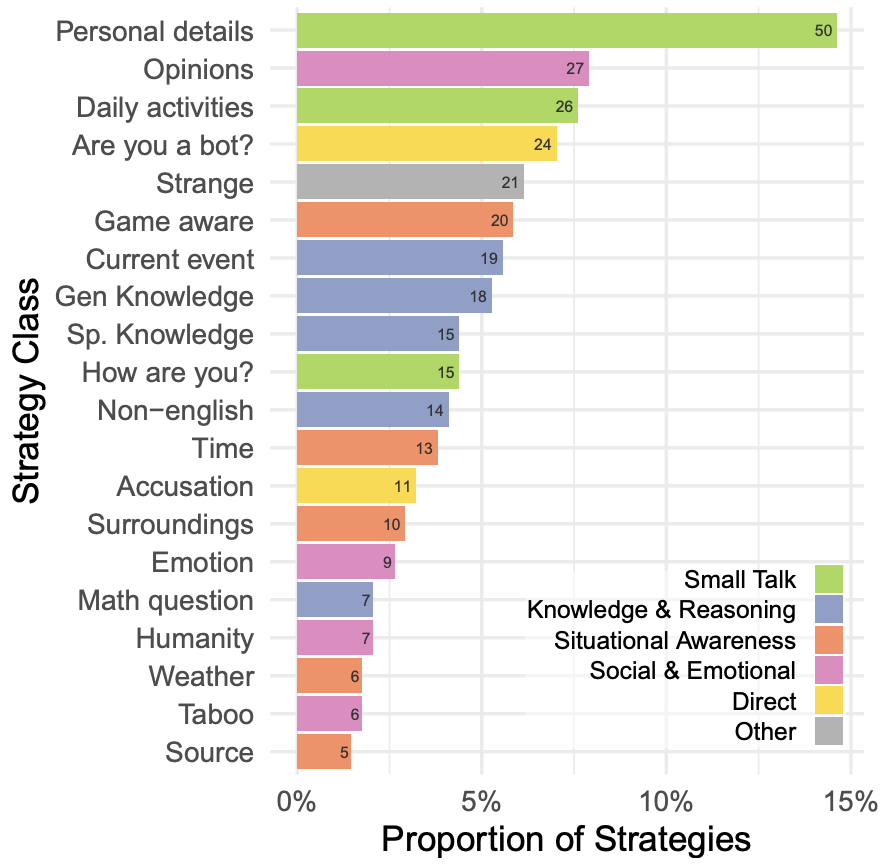
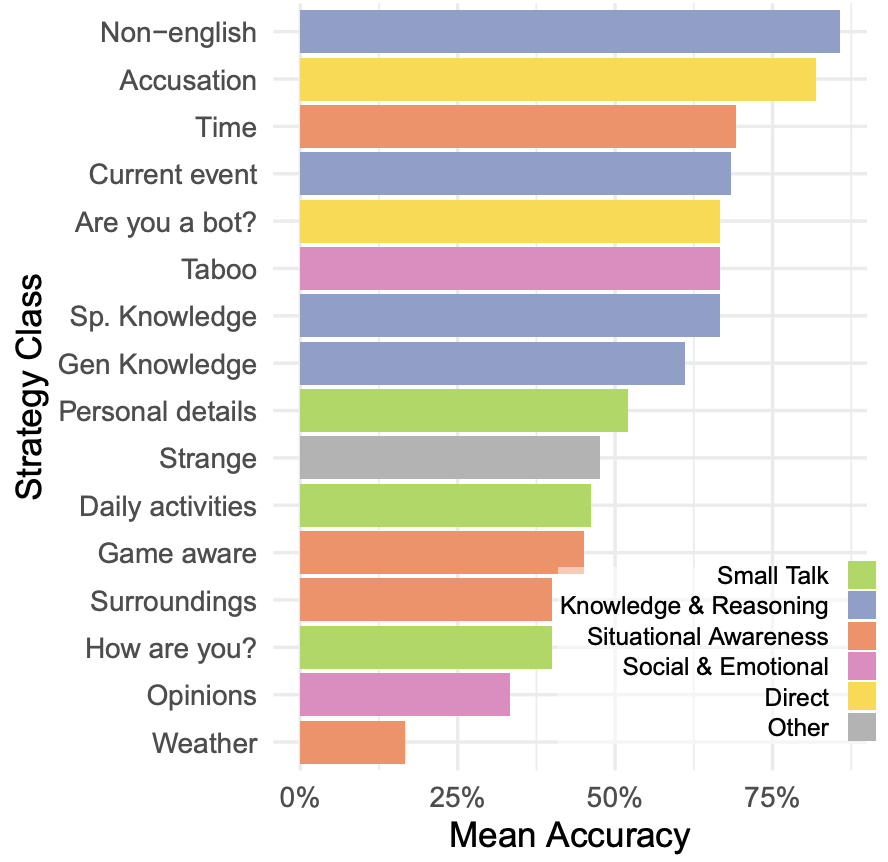
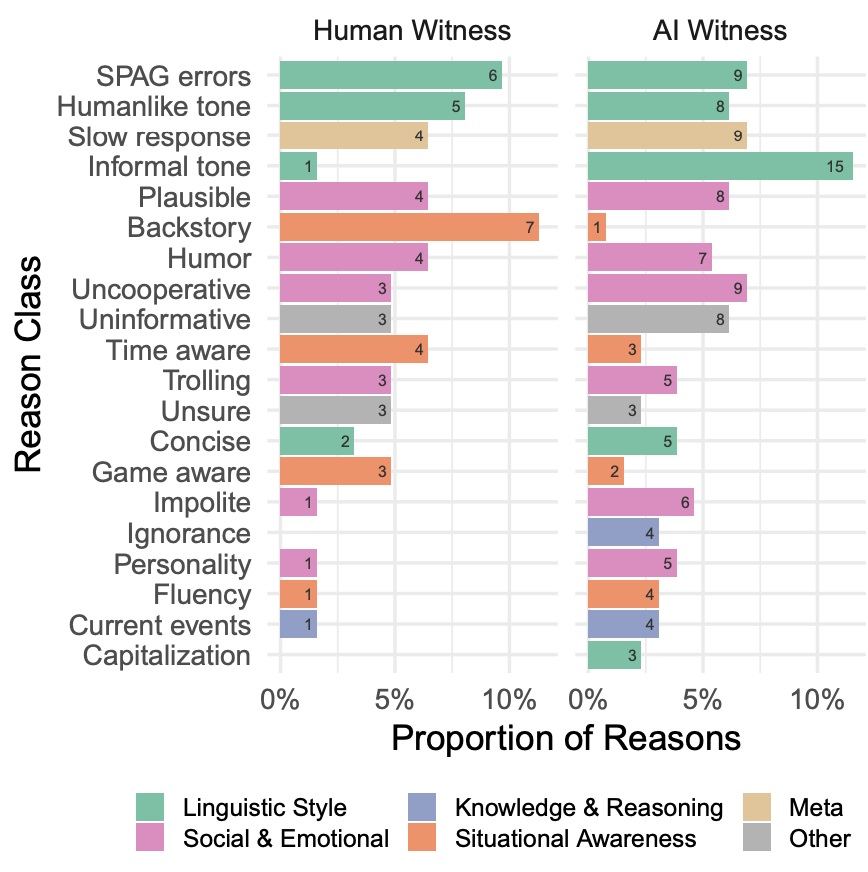
审问者还关注了社交和情感因素(如幽默感或在游戏中不配合)。如图 11 所示,人类在辨别参与者是否是人类的理由上,不论是人类还是 AI 参与者之间,都有相似分布,表明模型在许多情况下都能够模仿这些特质。
▲图11 审问者判断参与者是人类的前 20 种理由,根据真实参与者类型细分
上述分布提出了两种可能性:
分布的相似性表明 AI 模型已经具有足够的能力,使得它们可以更好地模仿社交情感线索和流畅的语言风格,让审问者更容易将其视为人类。这意味着模型已经变得足够聪明,在模仿人类在这方面变得更加容易。
这些线索在一般情况下对于区分 AI 并不重要,所以对于那些尚未掌握这些线索的模型来说,该测试并非很好地判定 AI。也就是说,这些特定的线索可能在模仿人类的情境中并不总是表现得特别突出。
总结
在这项研究中,作者深入探讨了人类和 AI 之间的复杂互动。尽管图灵测试并不是完美的智能度量标准,但它为我们提供了深刻理解智能体社交互动的框架。实验结果表明,基于规则的 AI 系统(如 ELIZA),在某些情况下的表现竟也出乎意料的成功。与此同时,人类参与者被正确判断为人类的概率仅为 63%。
此外,AI 系统仍然面临着语言风格和社交情感因素等挑战,这些挑战可能比传统人工智能判定概念更加重要,因为会直接涉及到 AI 模型在模仿人类社交互动中的能力。
此外,AI 系统仍然面临一系列挑战,特别是在处理语言风格和社交情感等因素时,这些挑战可能比传统的智能性概念更为重要,因为它们直接关系到 AI 模型在模仿人类社交互动方面的能力。
这也凸显了一个潜在的风险,即在人们未能意识到的情况下,AI 欺骗可能会发生。如果 AI 模型能够成功地模仿人类的语言和情感,它们有可能会被误认为真正的人类,这可能会导致误导信息、虚假信息的传播,甚至引发社会和伦理问题。
最后,我们必须承认这项实验还存在许多局限性,例如参与者的样本不够具有代表性、缺乏激励机制。因此,虽然本文提供了一些见解,但仍需要更多充分的研究,以更好地理解智能体和社交互动的本质。不仅仅是图灵测试,我们需要寻求更多多样化的智能性度量标准,以更全面地了解和评估 AI 系统的能力。这也许能帮助我们更好地了解未来 AI 技术,确保其在各个领域的应用都能够有益于人类社会。