
清华大学实验组18篇论文被ACL 2022录用
近日,ACL 2022录用结果出炉,我组18篇论文被ACL 2022录用,其中主会论文13篇,Findings论文5篇。以下为论文列表及介绍:
ACL 2022主会
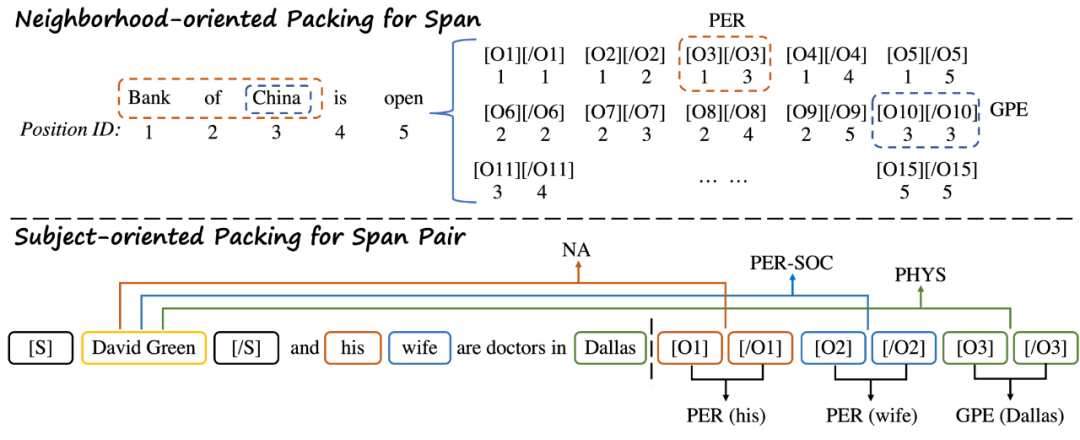
Packed Levitated Marker for Entity and Relation Extraction
QuoteR: A Benchmark of Quote Recommendation for Writing
作者:岂凡超,杨延辉,易靖,程志立,刘知远,孙茂松
类型:Long Paper
摘要:在写作中人们经常引用名言名句来提高文章文采和说服力。为了帮助人们更快地找到合适的名言名句,研究者提出了名言名句推荐任务。该任务旨在自动推荐适合当前上下文的名言名句。现在已经有许多名言名句推荐方法,但是他们的评测基于不同的未公开数据集。为了推进这一领域的研究,我们构建了一个名为QuoteR的大规模名言名句推荐数据集。该数据集完全公开,由英语、现代汉语、古诗文三部分构成,每一部分都比此前的相应未公开数据集要大。基于该数据集,我们对此前的所有名言名句推荐方法进行了公平而详尽的评测。此外,我们还提出了一个名言名句推荐模型,其性能显著超过前人方法。
以下为根据上下文“从盘面上看,股票价格会呈现某种带漂移的无规则行走,涨跌无常,难以捉摸。[Quote],这话放在投资领域也同样受用。事物是在不断变化的,历史数据只能起一定程度的参考作用。投资者想凭借历史数据准确预测未来几乎是不可能的。”推荐的名言示例:
MSP: Multi-Stage Prompting for Making Pre-trained Language Models Better Translators

Integrating Vectorized Lexical Constraints for Neural Machine Translation
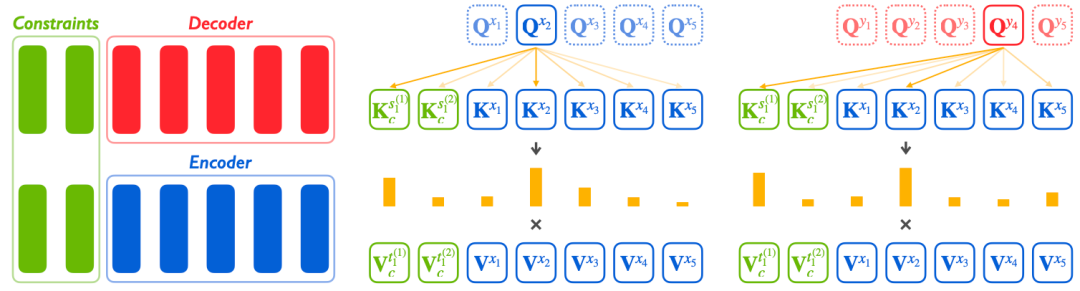
Pass off Fish Eyes for Pearls: Attacking Model Selection of Pre-trained Models
PPT: Pre-trained Prompt Tuning for Few-shot Learning

Prototypical Verbalizer for Prompt-based Few-shot Tuning
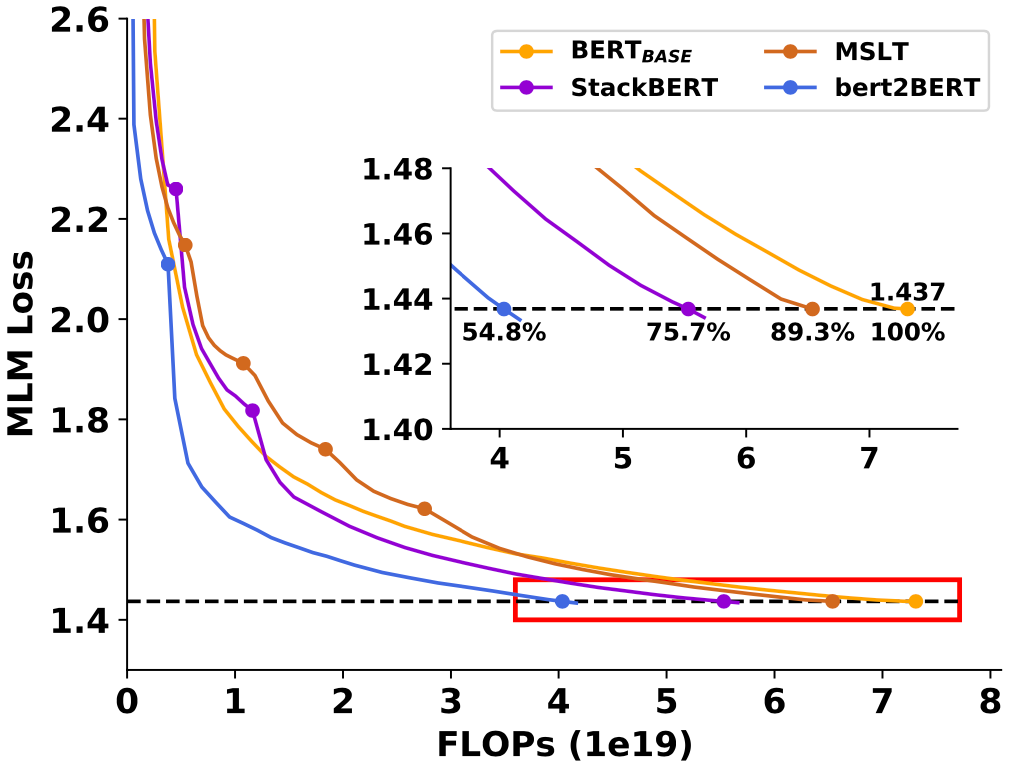
bert2BERT: Towards Reusable Pretrained Language Models
Cross-Lingual Contrastive Learning for Fine-Grained Entity Typing for Low-Resource Languages
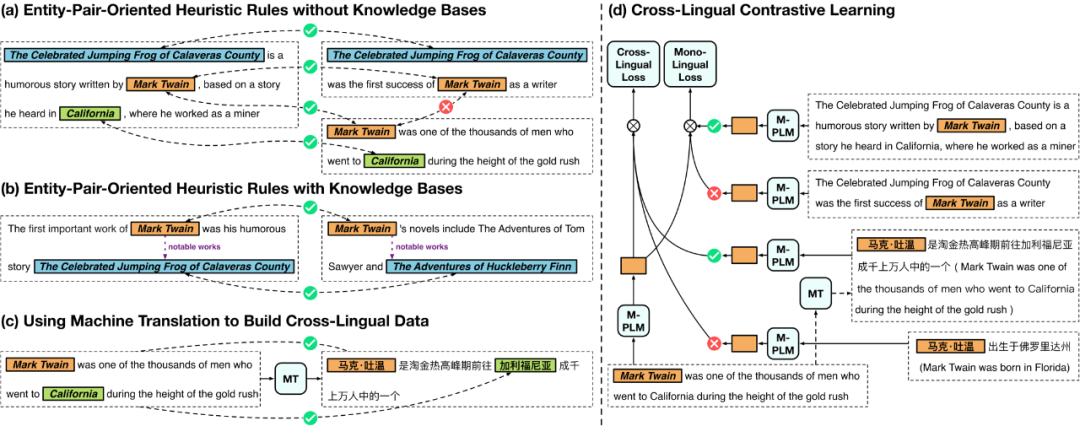
Knowledgeable Prompt-tuning: Incorporating Knowledge into Prompt Verbalizer for Text Classification
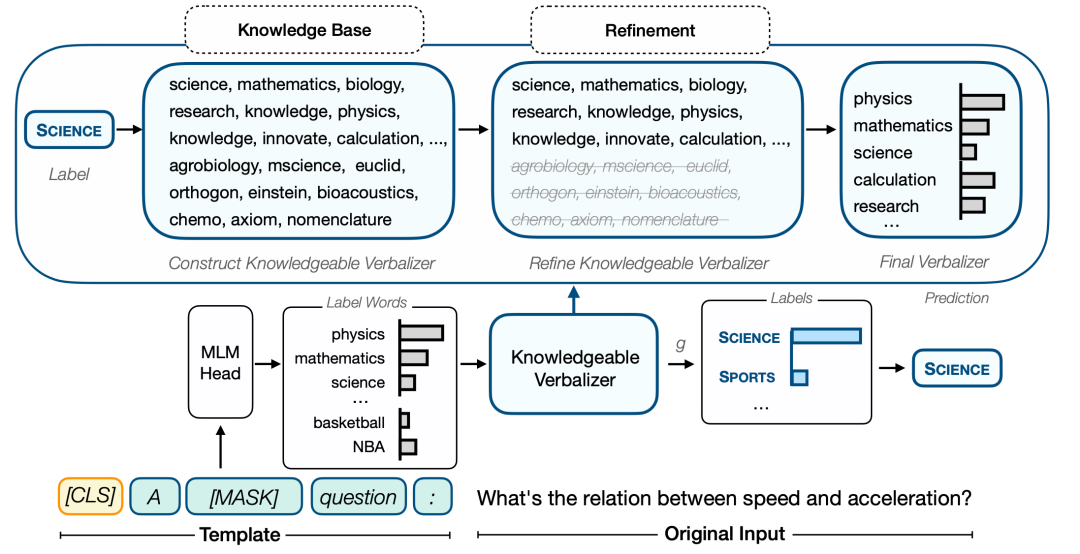
Fully Hyperbolic Neural Networks
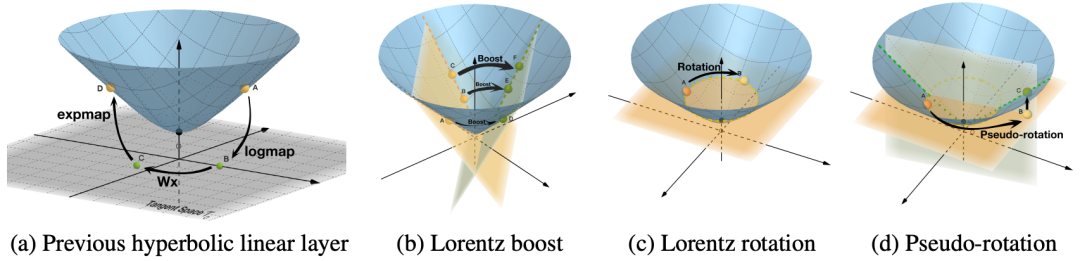
Program Transfer for Complex Question Answering over Knowledge Bases
作者:曹书林,史佳欣,姚子俊,吕鑫,侯磊,李涓子,刘知远,肖镜辉,于济凡,张含望
类型:Long Paper
摘要:在知识库(KB)上回答复杂问题的程序归纳法旨在将问题分解为一个由多个函数组合而成的程序,程序在知识库的执行从而最终答案。程序归纳的学习依赖于给定知识库的大量平行问题-程序对。然而,对于大多数知识库来说,通常是缺乏这样的标注的,这使得学习非常困难。在本文中,我们提出了Program Transfer的方法,其目的是利用富资源知识库上的程序标注作为外部监督信号来帮助缺乏程序标注的低资源知识库的程序归纳。对于Program Transfer,我们设计了一个新颖的两阶段解析框架,并设计了一个高效的基于知识库本体的剪枝策略。首先,一个Sketch解析器将问题翻译成sketch,即函数的组合;然后,给定问题和sketch,一个参数分析器从知识库中搜索具体的函数参数。在搜索过程中,我们结合知识库的本体来调整搜索空间。在ComplexWebQuestions和WebQuestionSP上的实验表明,我们的方法明显优于SOTA方法,证明了Program Transfer和我们框架的有效性。该工作与清华大学李涓子老师团队和华为诺亚实验室刘群老师团队合作完成。
A Simple but Effective Pluggable Entity Lookup Table for Pre-trained Language Models
Findings of ACL 2022
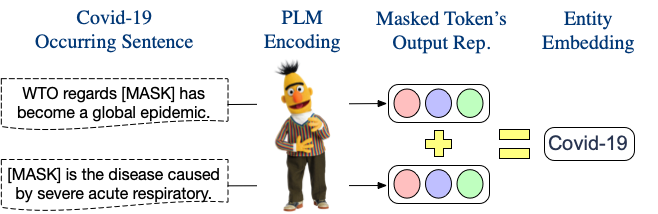
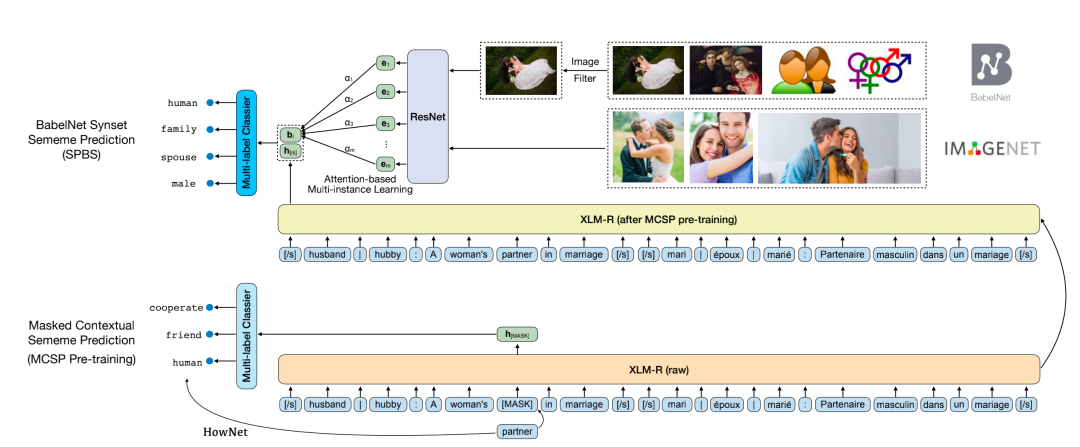
Sememe Prediction for BabelNet Synsets Using Multilingual and Multimodal Information
作者:岂凡超,吕传承,刘知远,孟笑君,孙茂松,郑海涛
类型:Long Paper
摘要:在语言学中,义原被定义为语义的最小单位。人工标注单词的义原知识库已成功应用到各种NLP任务中。然而,现有的义原知识库只涵盖了少数几种语言,阻碍了义原的广泛利用。针对这一问题,文章提出了BabelNet同义词集的义位预测任务(SPBS),旨在基于BabelNet多语言百科词典构建多语言义原知识库。通过自动预测BabelNet同义词集的义原,该同义词集中的多个语言的词将同时获得义原注释。然而,以往的SPBS方法并没有充分利用BabelNet中丰富的信息。在本文中,我们利用BabelNet中的多语言同义词、多语言定义和图像来实现SPBS。我们设计了一个多模态信息融合模型,对这些信息进行编码和组合,进行义原预测。实验结果表明,我们的模型明显优于以前的方法。该工作与清华大学深圳研究院郑海涛老师团队合作完成。
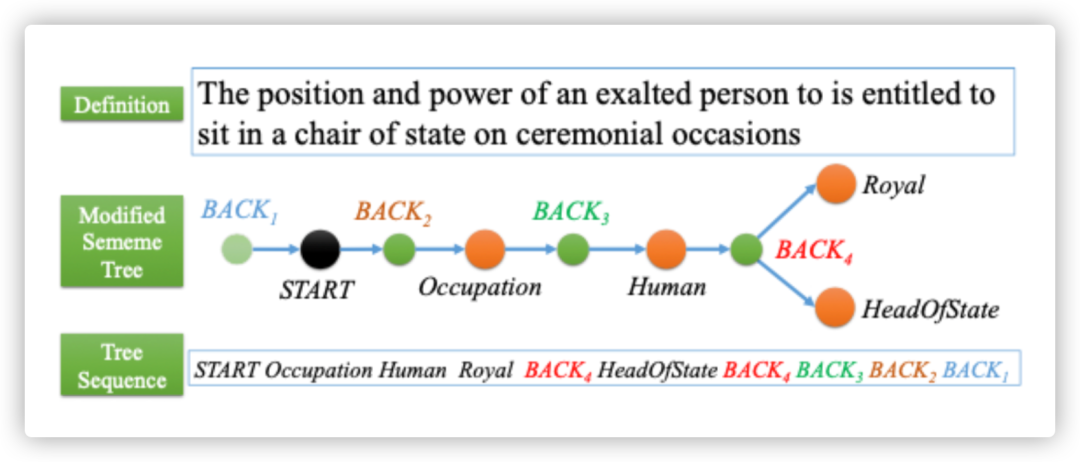
Going "Deeper": Structured Sememe Prediction via Transformer with Tree Attention
作者:叶奕宁,岂凡超,刘知远,孙茂松
类型:Long Paper
摘要:含有单词和最小语义单位的义原知识库在很多NLP任务中有较好的表现。由于人工构建义原知识库费时费力,一些研究试图通过对未标注词语的义原进行预测来实现自动的知识库构建。然而已有的研究忽略了义原语义系统中非常重要的一部分——层次结构。本篇工作中,我们首次尝试结构化的义原预测,即将单词对应的义原预测为树状结构。同时,我们针对性地修改了注意力计算方法,由此设计了基于transformer的义原树预测模型,并在实验中验证了它的有效性。我们也对模型的效果进行了定量和定性的分析。本工作的代码将会开源。
Do Pre-trained Models Benefit Knowledge Graph Completion? A Reliable Evaluation and a Reasonable Approach
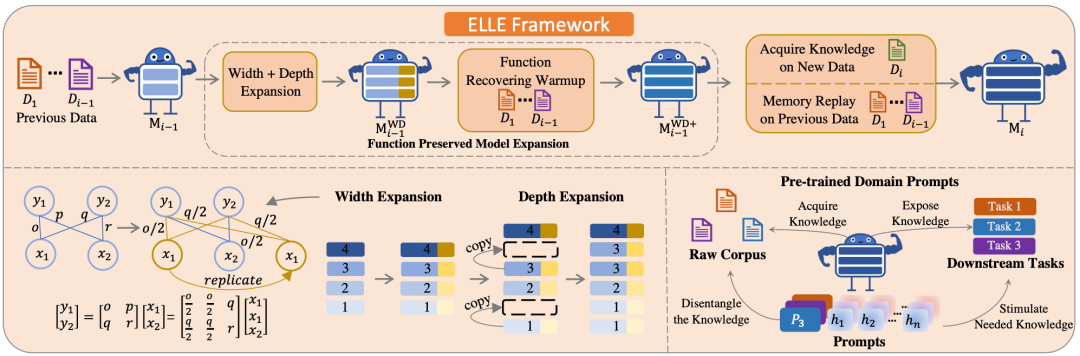
ELLE: Efficient Lifelong Pre-training for Emerging Data
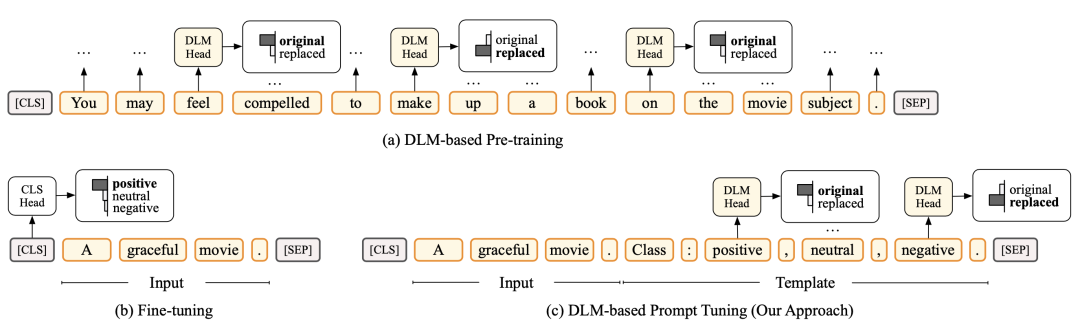
Prompt Tuning for Discriminative Pre-trained Language Models
国际计算语言学年会(Annual Meeting of the Association for Computational Linguistics,简称ACL)是自然语言处理领域顶级学术会议,在世界范围内每年召开一次,2022年是第60届会议,将于5月22-27日在爱尔兰首都都柏林以线上线下混合形式举行。
本次ACL会议首次与滚动审稿ARR合作,并首次在OpenReview系统上进行审稿匹配。在滚动审稿中,作者先将论文提交到论文池进行集中滚动审阅,在充分完善后,再将论文、ARR审稿意见等提交至ACL 2022。
大会官网:https://2022.aclweb.org/。
