
国防科大提出基于可变形三维卷积的视频超分辨,代码已开源
加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~

引言(Introduction)
方法(Method)
1、可变形三维卷积(D3D)
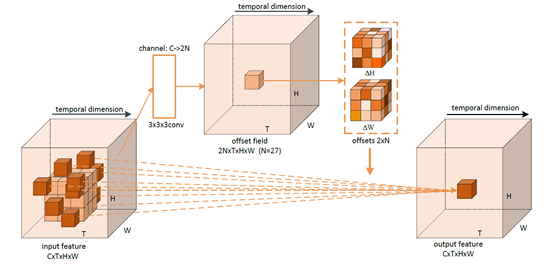
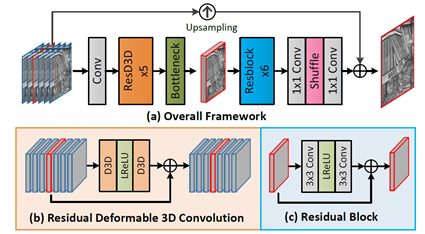
2、可变形三维卷积网络(D3Dnet)
实验(Experiments)
1、消融学习(Ablation Study)
实验部分首先通过消融学习对网络中不同模块和方案的有效性进行验证。
1)双阶段方法(two-stage)和单阶段方法(C3D,D3D)。
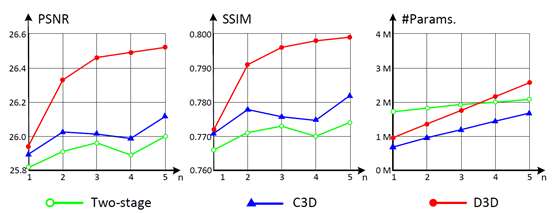
2)输入视频的帧数。

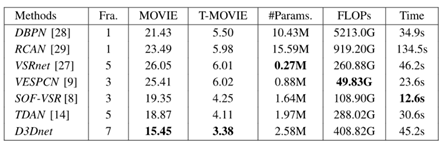
1)数值结果

2)视觉效果

3)流畅度与运行效率

结论(Conclusion)

评论