
谷歌最新提出无需卷积、注意力 ,纯MLP构成的视觉架构!网友:MLP is All You Need ?

极市导读
谷歌大脑团队提出了一种仅仅需要多层感知机的框架——MLP-Mixer,无需卷积模块、注意力机制,即可达到与CNN、Transformer相媲美的图像分类性能。 >>加入极市CV技术交流群,走在计算机视觉的最前沿


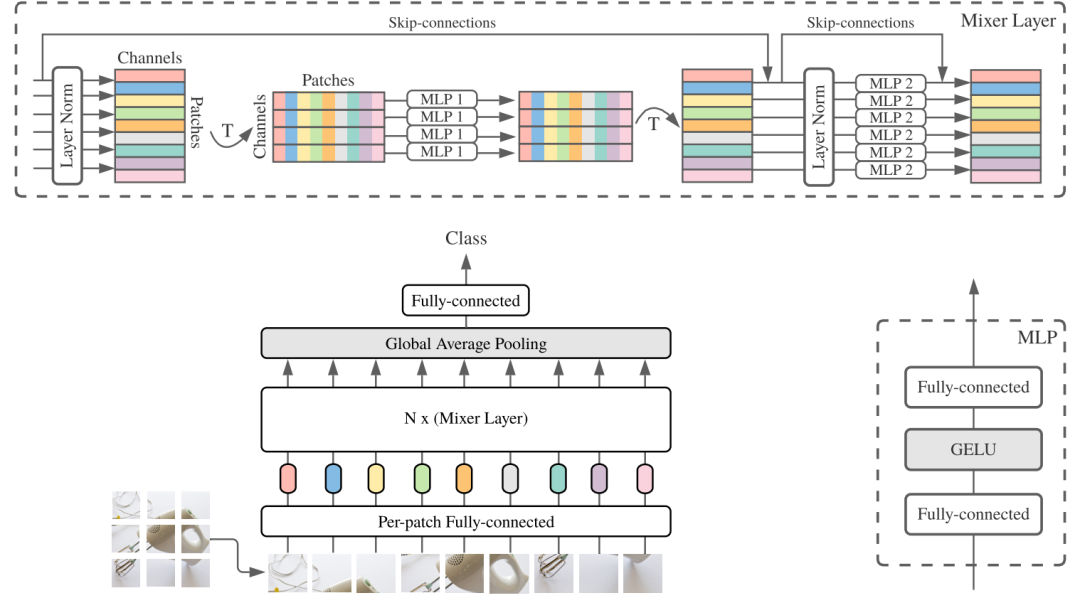
1 Mixer 混合器架构
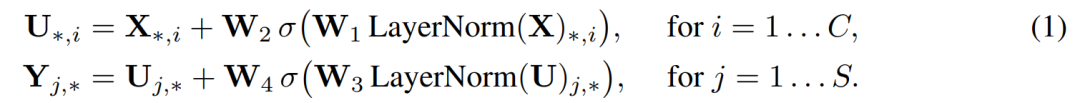
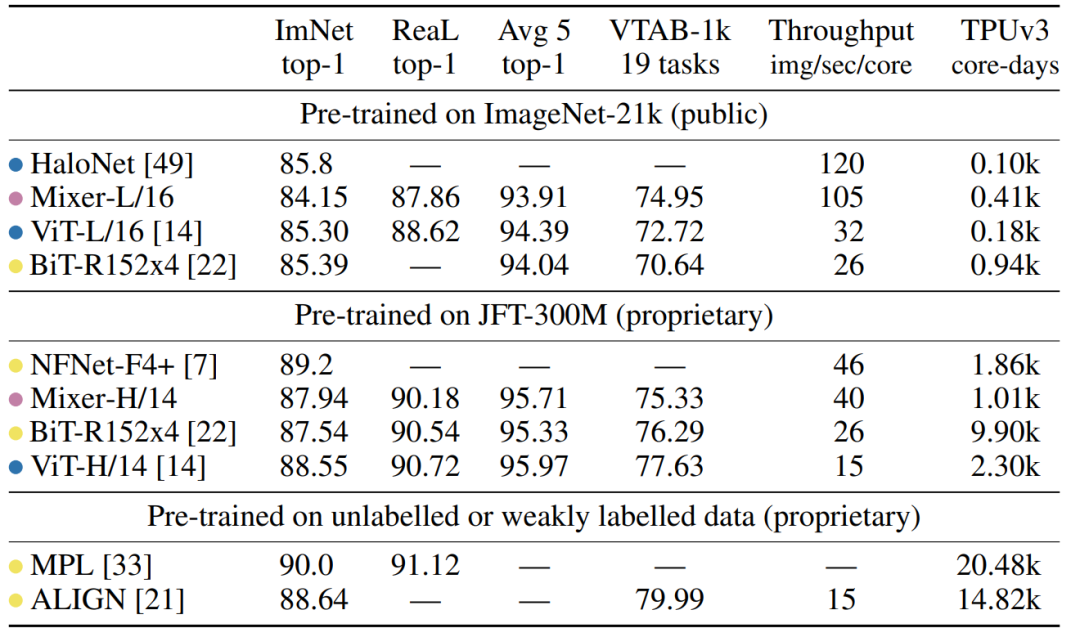
2 更多实验结果和代码


3 网友评价
FC is all you need, neither Conv nor Attention. 在数据和资源足够的情况下,或许inductive bias的模型反而成了束缚,还不如最simple的模型来的直接。

说白了就是patch内和patch间依次进行信息交换和整合,相比transformer其实缺了个动态的结构,也就是内容不可感知,有点过拟合的意思在里面。主观感觉,如果再补个patch内的attention和patch间的attention进去,差不多就能接近transformer了。
观察到两个趋势,不敢说是好还是坏: 1、以前的工作都努力在通用模型里加归纳偏置,用来减少参数优化需要的资源(数据、计算资源);近期的(一批)工作在反其道行之,逐渐去先验化,让这部分bias通过大量数据学习出来。 2、以前的模型都讲究兼容变长数据,CNN、RNN、Xformer都有处理变长数据的能力,这使得它们非常通用,现在的一些模型(包括问题讨论的这篇)都assume输入的大小是固定的,直观上看不能算太通用的框架(所以不敢苟同MLP is all you need这种观点)。
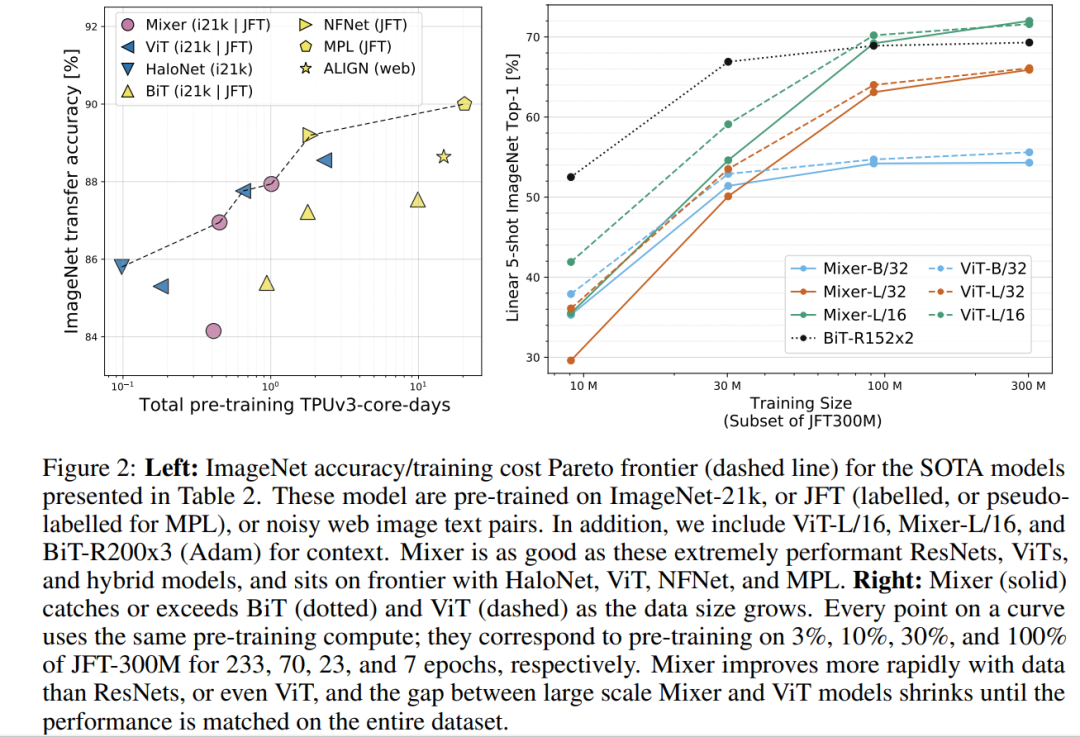
总体而言相对遗憾,没有超过SOTA,仅仅是可比较。从实验结果来看跟ViT相比还是全面落后,但还是给人一些启发的,毕竟结构极致简单。 本文核心是设计了非常小巧的Mixer-Layer,通过MLP来交互每个patches的信息。实际上,经过一次mixer-layer,每个patch就能拿到全图的信息。
感觉有点标题党,照这么说CNN也是MLP了,MLP本来就是现在大部分架构的building block,区别只是这些子MLP如何连接,如何共享权重等等。

谷歌还是不会取名字,要换成国内组的话,直接一个"MLP is All You Need"或者"Make MLP Great Again"。

 。
。本文亮点总结
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“医学影像”获取医学影像综述~
顶会干货:CVPR 二十年,影响力最大的 10 篇论文!| CVPR2021 最新18篇 Oral 论文|学术论文投稿与Rebuttal经验分享
实操教程:PyTorch自定义CUDA算子教程与运行时间分析|pytorch中使用detach并不能阻止参数更新
招聘面经:秋招计算机视觉汇总面经分享|算法工程师面试题汇总
最新CV竞赛:2021 高通人工智能应用创新大赛|CVPR 2021 | Short-video Face Parsing Challenge

# CV技术社群邀请函 #
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~

评论